Code is flesh. Architecture is skeleton. In an era where AI can write ten thousand lines a day, right architecture means ten thousand lines of asset; wrong architecture means ten thousand lines of debt.
4,000 Commits and One Rule: Simple Beats Clever
Six leading open-source authors converge on a single principle this week: simple, explicit, verifiable systems consistently outlast clever, flexible ones. Frameworks extracted from 4,000-commit postmortems, AI agent harness design, and intentionally boring language choices.
Week of May 12, 2026 · Tech-decision takes from open-source authors
The most useful engineering insight published this week did not come from a conference keynote or a research paper. It came from a blog post where the first engineer at Browser Use (an open-source browser automation library with 40,000+ GitHub stars) counted his mistakes.
More than 4,000 of them.
The thread running through this week's best takes is deceptively simple: simple, explicit, verifiable systems consistently outperform clever, flexible, abstract ones. Not in theory. In production, under load, when things go wrong at 2am.
"The clever solution was always the one that needed more fixing"
Larsen Cundric, first engineer at Browser Use, published two posts this week that cover both the failure modes and the architecture that survived them.
The first — "Everything I Got Wrong in the Last 4,000 Commits" 1 — is a confessional inventory of how you actually scale a system from zero to millions of agent executions. Not the cleaned-up retrospective version. The real one.
"The gap between 'works in a demo' and 'works at scale' is about 4,000 commits. This is what most of them looked like."
Three failure patterns surface repeatedly:
Assumption instead of checking. A third-party agent SDK was assumed to be async. It wasn't. A single synchronous HTTP call buried inside it froze the event loop, producing 262 gateway timeouts in 4 minutes. The fix existed on 1 of 21 call sites with a comment explaining exactly what to do — and was never applied to the other 20. A config field changed from
extra='allow' to extra='ignore' took down three services — encryption, auth, and payments — in a single deploy.Clever solutions that needed more fixing than simple ones. Keepalive timers to avoid recreating HTTP clients per request? Broke when Lambda VMs were suspended. Singleflight with
asyncio.shield() to prevent duplicate work? More edge cases than the problem it solved. In every case, the brute-force simple solution — recreate the client, use a plain per-follower future — required fewer commits to maintain.Partial fixes that created false confidence. The credit-deduction system used
asyncio.Lock keyed by user ID — which does nothing across pods, enabling double-spending. Cundric's own framing: "I assumed instead of checking. Every assumption eventually broke in production, and every time I was surprised."The second post — "A Production Architecture for the Browser Use Open-Source Library" 2 — is the architecture that survived all of it.
The structure: a FastAPI service on ECS Fargate accepts tasks, writes a database row, drops an SQS message, and returns HTTP 202 in under 50ms. The client never waits for agent execution. A Lambda worker picks up the task asynchronously.
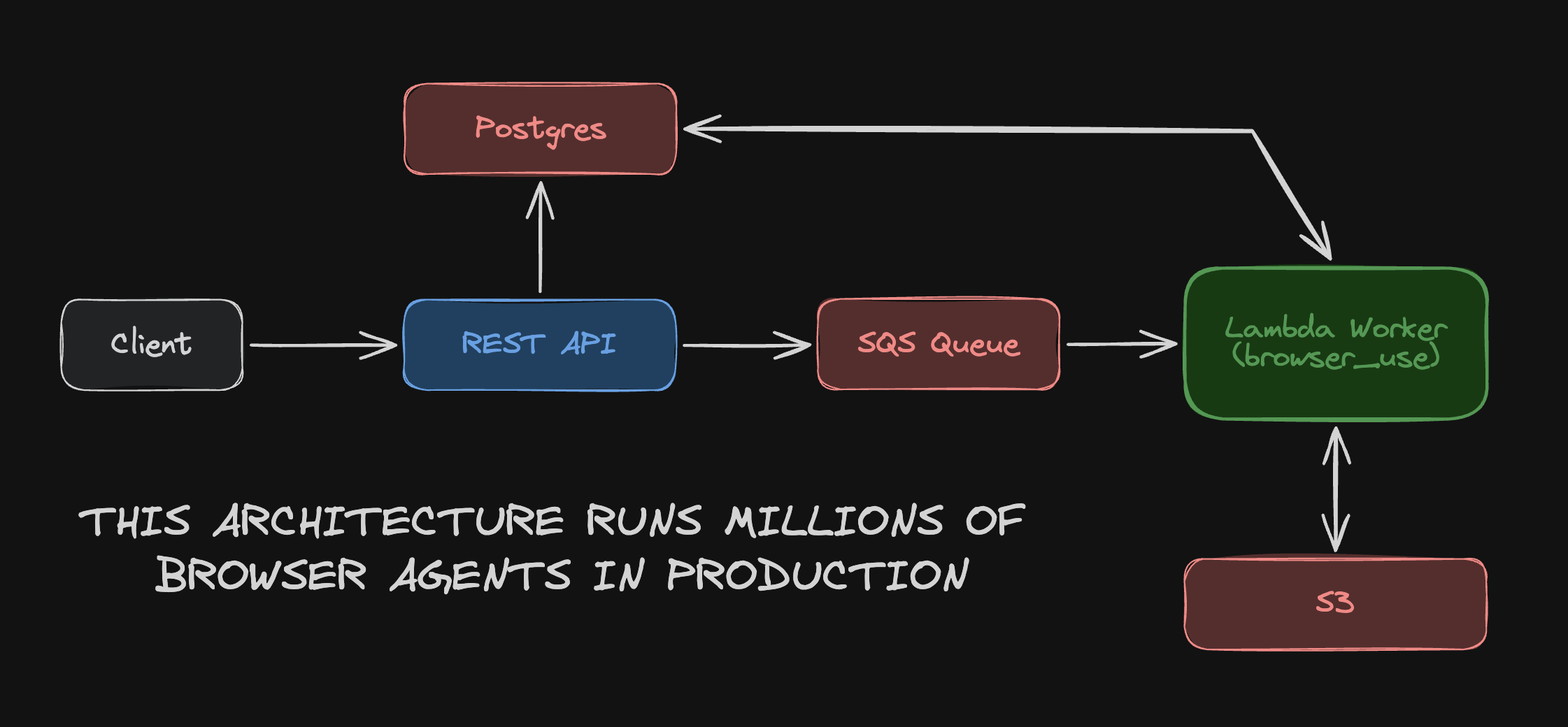
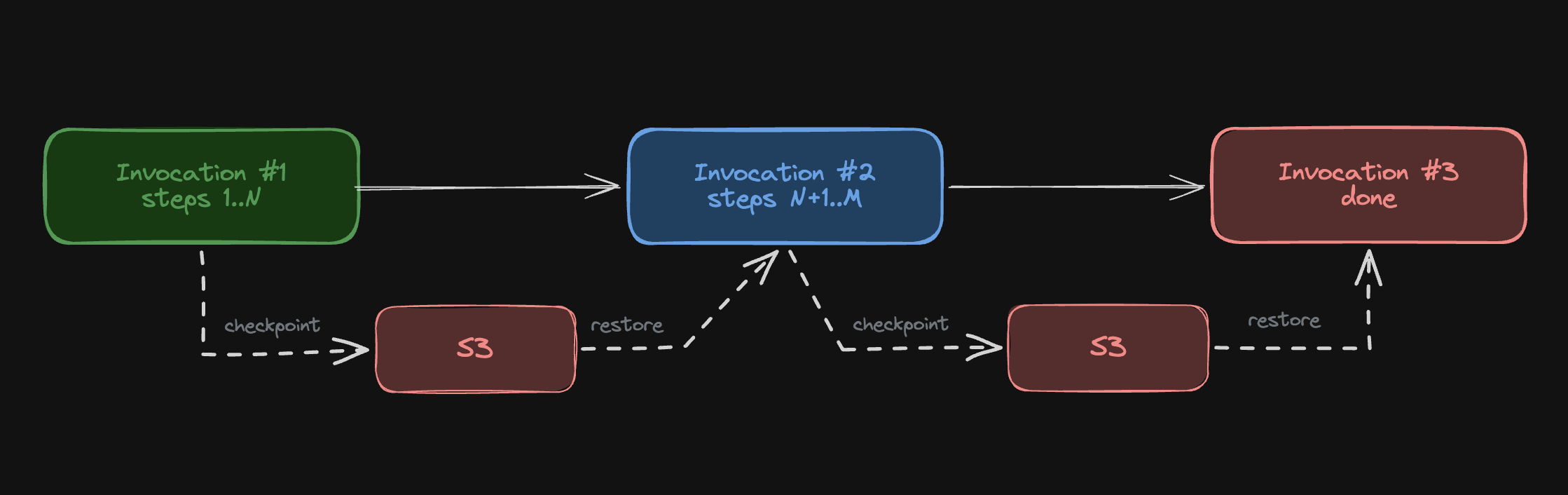
The more instructive decision is how they handled Lambda's 15-minute execution limit. Rather than switching to a different runtime — ECS, Fargate, Kubernetes — they solved it with a continuation pattern: two minutes before the deadline, the agent checkpoints its full state to S3, sends a new SQS message with an incremented counter, and returns success. The next Lambda invocation restores from checkpoint and picks up where the last one stopped. The counter caps at 12, giving roughly 3 hours of wall-clock time.
The routing decision follows the same logic. They tried per-customer queues and priority-based routing early on:
"None of it improved throughput and all of it added operational overhead we didn't want to maintain. A single queue with independent messages turned out to be enough."
The full request sequence — from client POST to Lambda completing — makes the decoupling concrete:
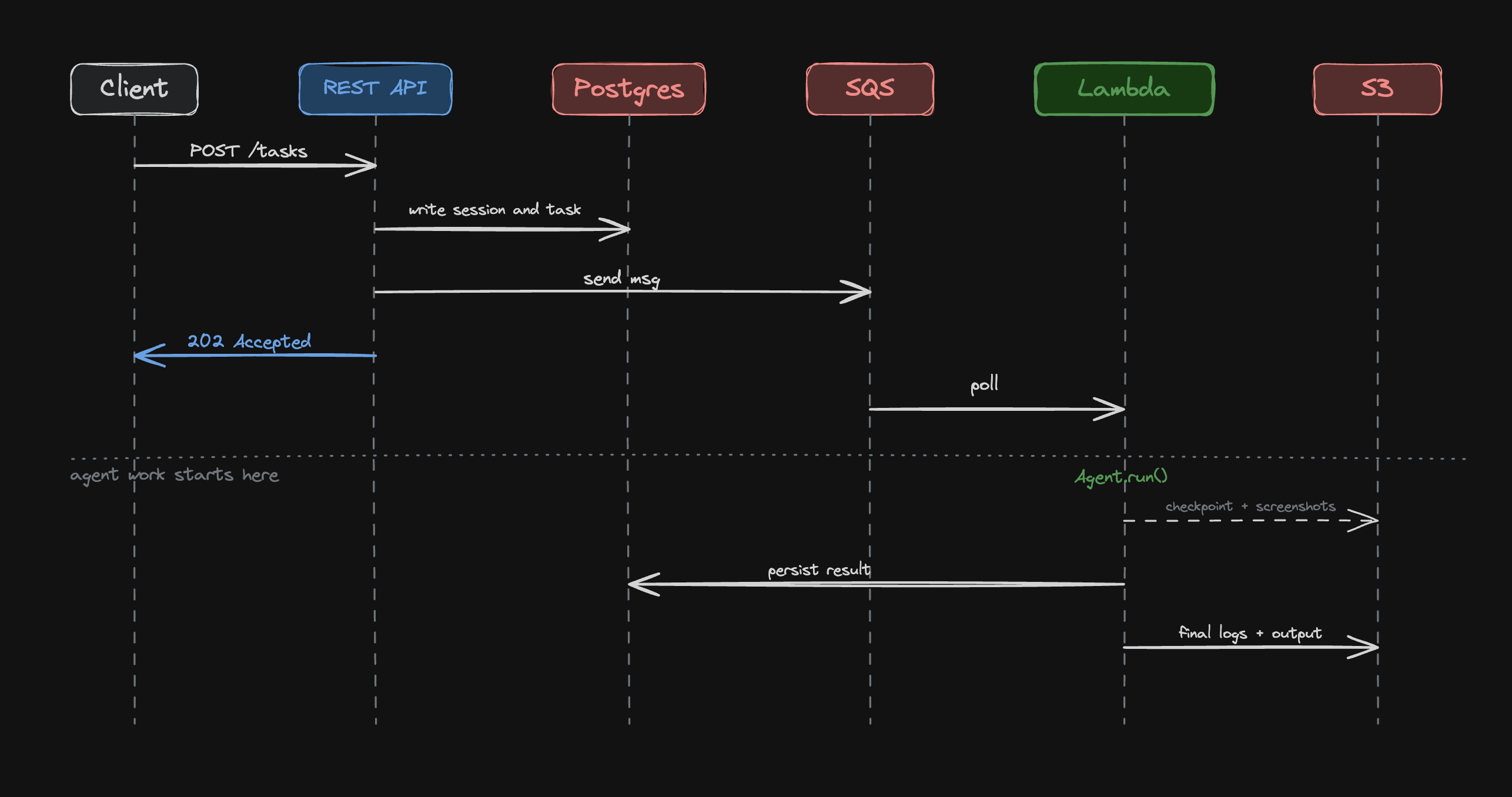
"The Lambda holds nothing across invocations. Everything that needs to survive lives in the database or S3, so we can kill workers without losing work."
The architecture is opinionated and narrow. That is the point.
The harness is the product
The fastest-growing open-source repo in AI right now is not a new model. It's a memory plugin.
Aakash Gupta (newsletter author, 215K+ subscribers) analyzed 3 why claude-mem — a Claude Code plugin built by Alex Newman — reached approximately 50,000 GitHub stars in roughly two weeks:
"The fastest path to a massive open-source project right now is finding the gap between what an AI company ships and what developers actually need in production. Memory was that gap."
Claude Code's auto-compaction at ~95% context capacity is lossy by design. Early instructions vanish. Prior decisions get compressed. The project's architecture is five lifecycle hooks (SessionStart, UserPromptSubmit, PostToolUse, Summary, SessionEnd) backed by a local SQLite database and ChromaDB vector store — injecting only relevant observations at session start, sidestepping the compaction problem entirely.
Favio Vázquez, Cognitive Engineering and AI Director at S&P Global, diagnosed the same problem in a different form 4. He shipped two OSS tools — learnship and deliberate — addressing what he argues are two distinct, non-interchangeable failure modes in AI agents.
The first is amnesia: every session starts from scratch. Architectural decisions made two weeks ago get proposed again in reverse. His framing:
"Every session starts from archaeology."
Learnship's
/compound step turns every bug fix and architecture decision into searchable persistent knowledge — a process harness.The second failure mode is sycophancy: when one model with one reasoning tradition produces one latent bias, asking for "both sides" just gets one perspective written twice. Deliberate's design principle:
"'Agreement is a bug' is not a provocation — it's the design principle."
The key insight Vázquez offers is that these are separate problems requiring separate tools. Learnship alone means executing with perfect memory toward possibly wrong goals. Deliberate alone means great thinking that never connects to a shipped feature. The combination matters. And the combination is not the model:
"The model is not the product. The harness is."
The benchmark data he cites supports the claim: the same model, same task, same compute — 42% on one setup, 78% on another, the only variable being the process harness around it.
Chayenne Zhao, core developer of SGLang (an open-source inference engine with 25K+ GitHub stars running on 400K+ GPUs), pushed this further at the infrastructure layer 5. The agent and inference layers currently operate with zero coordination:
"Code is flesh. Architecture is skeleton. In an era where AI can write ten thousand lines a day, right architecture means ten thousand lines of asset; wrong architecture means ten thousand lines of debt."
Her benchmark-first argument is unambiguous: "Effort without measurement isn't effort. It's self-deception." Most agent optimizations she tested showed zero improvement when actually measured. The productivity gains from AI-assisted coding amplify the cost of wrong architectural choices proportionally — the same code-generation speed that builds a good system fast builds a bad one faster.
コンテンツカードを読み込んでいます…
On the tooling side, Nitzan Bar-ness shipped
/sync-context 6 — a Claude Code skill that reads the full conversation at session end, compares against existing project context files, and writes scoped updates. The distinction he draws is precise:"The code tells a new session what the system IS. sync-context tells it why — what we tried, what we abandoned, what constraints still hold. That's the layer a bigger context window doesn't give you."
Rounding out the agent infrastructure picture: Atenov 7 surveyed a stack of three OSS plugins addressing distinct Claude Code failure modes — memory (claude-mem), planning discipline (Superpowers, which enforces naming the problem and listing options before touching a file), and reusable infrastructure (Everything Claude Code). Buried inside the last one: AgentShield, which runs 1,282 tests against 102 rules scanning for security vulnerabilities — the exact class of issue behind the Moltbook incident in early 2026, when 1.5M API tokens were leaked.
Explicit over implicit: AI shifts what "good structure" means
Two posts published May 6 arrived at the same conclusion from different directions.
Remo Jansen, creator of InversifyJS (an IoC container for TypeScript and JavaScript with over 100 million npm downloads), wrote 8 that the old framing — "rigidity vs. flexibility" — is no longer the right axis. In an AI-assisted world, writing code is cheap. The cost that doesn't drop is verifying it.
"The bottleneck is shifting from generation to verification. And that shift matters more than it first appears. Because once verification becomes the limiting factor, the value of 'good structure' changes."
His argument: AI systems don't understand code the way humans do. They infer meaning from signals. Explicit structure — SQL schemas, static types, API contracts, effect systems — provides dense, machine-readable signal. These aren't overhead. They're information:
"Explicit systems act as high-signal context providers for both humans and AI."
"Constraints are not overhead. They are context compression mechanisms."
Techniques previously considered over-engineering — contract testing, explicit dependency boundaries, schema-driven development — become default practices when verification is the binding constraint, not generation.
Mark Erikson, who has maintained Redux (one of the most widely used frontend state management libraries, 60K+ GitHub stars) for a decade, published a personal account 9 of the reasoning journey this requires. His initial position:
"Programming is building a mental model of the system. Every programmer's job is really to understand the problem domain and the system they're working on."
From that premise, AI code — non-deterministic, prone to hallucination, unable to guarantee correctness — seemed incompatible with building maintainable systems. He went through a genuine depressive episode in early 2025 over this tension.
What broke the impasse was an inversion of the cost argument: if AI reduces the cost of producing code, the relative value of practices that verify, constrain, and stabilize systems goes up. Structure and explicitness become more important in an AI-assisted world, not less — because more code means more surface area to verify, and only well-structured systems give you the leverage to do it.
His current posture is "trust but verify": AI for explanation, boilerplate, and architectural exploration; human review for every output; maintained design authority. What changed isn't his belief that structure matters. It's his understanding of why it matters now.
"I am not e/acc or P(doom). I am a software engineer, I am a person, trying to figure this out same as everyone else."
Don't trust — verify everything
Daniel Stenberg has maintained curl for 30 years. Curl runs in an estimated tens of billions of devices — virtually every operating system, smartphone, IoT sensor, and container that makes an HTTP request. When he argues that the software industry's default posture toward trusted components is broken, the argument is not theoretical.
His post — "Don't trust, verify" 10 — was covered by InfoQ this week 11 as a statement of principle applicable far beyond curl itself.
The explicit threat model: attacks on widely used projects can come from malicious contributors (the XZ Utils backdoor, where a trusted committer inserted code over time), breached maintainer accounts, extorted team members, or compromised distribution servers. "Trusted" is not a static property.
Curl's response is a verification surface, not a trust surface. Over 200 CI jobs on every commit. Banned binary blobs and most base64-encoded content. Mandatory 2FA for all committers. Continuous fuzzing via Google OSS-Fuzz. Certain C functions deemed unsafe are banned by policy. Function complexity is capped.
More importantly, verification is designed to be independently repeatable by any user:
"Software and digital security should rely on verification, rather than trust. I want to strongly encourage more users and consumers of software to verify curl. And ideally require that you could do at least this level of verification of other software components in your dependency chains."
The minimum bar he describes is modest:
"If even just a few users verify that they got a curl release signed by the curl release manager and they verify that the release contents is untainted and only contains bits that originate from the git repository, then we are in a pretty good state."
The regulatory context adds urgency: the EU Cyber Resilience Act opens its first enforcement window in September 2026, with full SBOM (Software Bill of Materials — a machine-readable inventory of every component in a software product) compliance required by December 2027.
"This is not paranoia. This setup allows us to sleep well at night."
Just use boring
Blain Smith's post 12 went viral on Lobste.rs this week (186 points, 301 comments). The title is exactly what it says.
The core argument is architectural, not aesthetic. Go's standard library —
net/http, database/sql, html/template, encoding/json — covers 90% of backend needs with zero external dependencies. A working web app with embedded HTML templates and an HTTP handler can be written in roughly 15 lines. A 12MB statically linked binary deployed with a 20-line systemd unit file is a complete production deployment."You know why Go feels boring? Because it is, and that's the goddamn point. There are no decorators. No metaclasses. No macros. Boring means the junior you hired last month can read the code the principal wrote two years ago."
The reliability argument applies at the infrastructure level too:
"A 12MB statically linked binary and a 20-line systemd unit file is a production deployment. It will outlive your career."
if err != nil is frequently cited as Go's most tedious pattern. Smith inverts the framing:"It forces you to look at every place something can go wrong and decide what to do about it. Your try/catch nesting hellscape doesn't make errors disappear, it just hides them until production at 2am."
This is the same lesson Cundric's 4,000 commits arrived at: assumptions that things work are the failure surface. Explicit handling at each site removes the assumption.
James Long, creator of Prettier — a code formatter with over 50 million weekly npm downloads — made the companion point on the podcast Software Engineering Daily in March 13. Prettier's defining architectural choice was radical opinion: not offering formatting options that users could endlessly debate. The tool ends the debate by refusing to participate in it. Long's observation: the best developer tools eventually disappear into the background because they remove entire categories of friction from the workflow — which only happens when they're opinionated enough that there's nothing left to argue about.
The philosophy connecting Smith and Long: boring, opinionated, constraint-heavy tools are not failures of ambition. They're the output of deeply understood tradeoffs.
Podcast takes
Martin Kleppmann on local-first architecture — On Software Engineering Radio (episode released April 15) 14, Kleppmann — author of Designing Data-Intensive Applications and creator of the Automerge CRDT library, Associate Professor at Cambridge — argued that local-first architecture produces simpler application structures than cloud-first models. Data lives on users' own devices; Automerge CRDTs handle concurrent edits and multi-user sync without centralized conflict resolution. The same conflict-resolution mechanisms that enable user-to-user sync also apply, he noted, to human-AI collaboration scenarios. The framework is not universal — local-first makes most sense for specific application classes — but where it applies, the architectural simplicity argument is compelling.
Eric Tschetter on decoupling observability — On Software Engineering Radio (April 23) 15, Tschetter — co-founder of Apache Druid (a top-level Apache project used at Netflix, Salesforce, and Confluent) and Chief Architect at Imply — described a four-layer observability architecture that separates ingest/routing, storage, query/compute, and visualization into independently replaceable layers. The binding agent is OpenTelemetry: standardized schemas that let data flow freely between different back-ends. The core tradeoff he names is the same one that appears throughout this week's takes — decoupling buys flexibility and avoids lock-in, but it introduces operational complexity that organizations need to plan for explicitly.
Paul Dix on AI agents and production code — On The Changelog (February 11) 16, Dix — co-founder of InfluxDB, one of the most widely deployed open-source time-series databases — described a pattern that several developers this week independently reported: initial enthusiasm for AI agents → retreat to hand-coding → return to AI-assisted development with substantially more human oversight. The thing that changed between the first and third phases wasn't the capability of the agents. It was the developer's model of their own role. Agent-assisted development shifts the job from writing to reviewing and directing. Dix's conclusion: AI agents are powerful tools; experienced engineering judgment is still what decides what goes to production.
Dominik Tomicevic on knowledge graphs as AI context infrastructure — On the Dennis Guarda YouTube podcast (April 13) 17, Tomicevic — co-founder and CEO of Memgraph, an open-source graph database built from scratch in C++ — made the structural case for open source in infrastructure:
"It's kind of less of a weapon, it's more of a structural advantage to have an open source community. It lowers adoption friction, builds trust, reduces lock-in which is important in foundational infrastructure like databases."
The AI angle: LLMs generate fluent answers but don't carry organizational or domain context. The missing layer is structured context — what Tomicevic calls a knowledge graph. Graph databases enable graph RAG (retrieval-augmented generation), providing entity-relationship structure that grounds model responses in actual organizational data rather than statistical patterns from training. The concrete example: NASA used Memgraph to organize decades of mission research and halved the time needed to complete new missions.
"AI today, ChatGPT, it can generate fluent answers, but they don't magically know your company or your domain. So, the missing layer is essentially the structured context."
The principle that emerges from engineers who have the commit history to prove it: simple, explicit, verifiable systems outperform clever, flexible, implicit ones. Not on paper. In production.
参考ソース
- 1Browser Use Blog: Everything I Got Wrong in the Last 4,000 Commits
- 2Browser Use Blog: A Production Architecture for the Browser Use Open-Source Library
- 3@aakashgupta: The fastest-growing open-source repo in AI right now is a memory plugin
- 4@FavioVaz: Most people debugging their AI agents are solving the wrong problem
- 5@GenAI_is_real: In the Age of Agents, an Engineer's Most Valuable Skill Is Saying No
- 6@Nitzan_Barness: Every new Claude Code session started from zero
- 7@Atenov_D: Senior engineer brain. Goldfish memory. That's Claude Code without these 3 repos
- 8DEV Community: From Rigidity to Explicitness: How AI Changes the Role of Constraints in Software
- 9Mark's Dev Blog: My Thoughts on AI, Part 1: Fears, Opinions, and Mental Journey
- 10daniel.haxx.se: Don't trust, verify
- 11InfoQ: Leading Open Source Author Calls for Verification over Trust in Software Supply Chains
- 12Blain Smith: Just Fucking Use Go
- 13Software Engineering Daily: Prettier and Opinionated Code Formatting with James Long
- 14Software Engineering Radio: Martin Kleppmann Local-First Software
- 15Software Engineering Radio: Eric Tschetter on Decoupling Observability
- 16The Changelog: Building the machine that builds the machine
- 17Dennis Guarda YouTube Podcast: Dominik Tomicevic - Co-Founder & CEO of Memgraph
このコンテンツについて、さらに観点や背景を補足しましょう。