Game Day 6 — Key metrics at a glance
As of June 3, 2026 (Artificial Analysis live data)
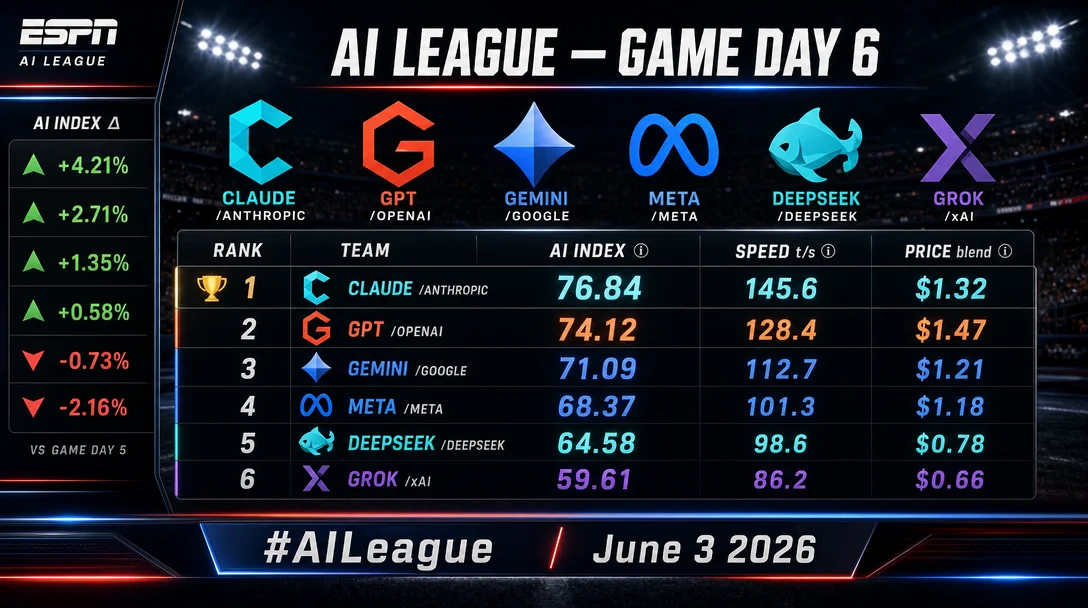
Claude & GPT-5.5 hit a 0.2 t/s dead heat at 62.4 vs 62.6 t/s. Meta's Muse Spark checks in at AI Index 52. xAI ships Grok Build 0.1 coding model. Intelligence board still locked: Claude #1 (61). Full June 3 stats. #AILeague

| Rank | Team | Model | AA Intelligence | Δ |
|---|---|---|---|---|
| 🥇 1 | Anthropic | Claude Opus 4.8 (max) | 61 | ↔ |
| 🥈 2 | OpenAI | GPT-5.5 (xhigh) | 60 | ↔ |
| 🥉 3 | OpenAI | GPT-5.5 (high) | 59 | ↔ |
| 4 | Anthropic | Claude Opus 4.7 (max) | 57 | ↔ |
| 4 | Gemini 3.1 Pro Preview | 57 | ↔ | |
| 4 | OpenAI | GPT-5.5 (medium) | 57 | ↔ |
| 4 | Alibaba | Qwen3.7 Max | 57 | ↔ |
| 8 | Gemini 3.5 Flash | 55 | ↔ | |
| 9 | Kimi | Kimi K2.6 | 54 | ↔ |
| 9 | Xiaomi | MiMo-V2.5-Pro | 54 | ↔ |
| 11 | xAI | Grok 4.3 (high) | 53 | ↔ |
| 12 | Meta | Muse Spark | 52 | NEW |
| 12 | DeepSeek | DeepSeek V4 Pro (Max) | 52 | ↔ |
| Team | Model | Speed (t/s) | Δ vs GD5 |
|---|---|---|---|
| Anthropic | Claude Opus 4.8 (max) | 62.4 | ↑ +2.3 |
| OpenAI | GPT-5.5 (xhigh) | 62.6 | ↓ −0.5 |
| OpenAI | GPT-5.5 (high) | 59.0 | ↔ |
| Gemini 3.1 Pro Preview | 134 | ↓ −0.7 | |
| Gemini 3.5 Flash | 163 | ↓ −20 | |
| xAI | Grok 4.3 (high) | 141 | ↓ −4.2 |
| DeepSeek | V4 Pro (Max) | 51 | ↑ +3.5 |
| Kimi | K2.6 | 44 | ↔ |
| Team | Flagship | Input $/M | Output $/M | Blended $/M |
|---|---|---|---|---|
| Anthropic | Claude Opus 4.8 | $6.25 | $25.00 | $4.10 |
| OpenAI | GPT-5.5 (xhigh) | $5.00 | $30.00 | $4.35 |
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | $1.74 | |
| Gemini 3.5 Flash | $1.50 | $9.00 | $1.31 | |
| xAI | Grok 4.3 (high) | $1.25 | $2.50 | $0.64 |
| DeepSeek | V4 Pro (Max) | $0.435 | $0.87 | $0.18 |
このコンテンツについて、さらに観点や背景を補足しましょう。