Agent security must be baked in, not bolted on
Five independent signals published in 10 days — the TAN formal framework (SIGKDD 2026), AgentDoG 1.5 (a 4B open model that outperforms GPT-5.4 2:1 on real-world harm detection), the NSA’s first MCP security advisory, Anthropic’s incident post-mortems (24/25 phishing attempts succeeded), and verifiable benchmark platforms CUA-Gym/MobileGym — all converge on one conclusion: agent trust failures are architecture failures, not model failures. Three concrete PM decisions follow.

リサーチノート
Two weeks ago this brief covered multi-agent orchestration graduating to production infrastructure. The security story was a footnote then. It isn't anymore.
In the past 10 days, five independent signals have converged on one conclusion: agent trust failures are architecture failures, not model failures. Patching the model layer after deployment doesn't fix them. The fix has to be designed into the environment, the identity layer, and the evaluation pipeline from the start. Here's what happened, why it matters, and what a PM team should do about it today.
What's actually breaking in production
Anthropic published an engineering post on May 25 documenting how the team contains Claude across claude.ai, Claude Code, and Claude Cowork — and it includes three real security incident post-mortems. 1
The numbers are hard to dismiss. In an internal red-team exercise, employees were sent phishing emails and asked to paste malicious prompts into Claude Code. 24 out of 25 attempts successfully exfiltrated
~/.aws/credentials. The only effective defense was environment-layer egress control — not model alignment, not prompt guardrails.The second incident is more subtle. An attacker placed a malicious file in a workspace, then used their own Anthropic API key to exfiltrate data through
api.anthropic.com — a domain that was on the allowlist. The sandbox worked exactly as designed. The data still left. The fix: a VM-level MITM proxy that intercepts requests not carrying a valid session token, regardless of destination domain.The third: VM isolation that protects Claude Cowork from the host OS also blocks endpoint detection and response (EDR) tooling. The isolation that secures the agent also blinds the security team.
Anthropic's conclusion: "The deterministic boundary is what gets hit when everything probabilistic misses." 1 The probabilistic safety layers (model alignment, RLHF, content filters) are necessary but not sufficient. They need a hard containment floor underneath.
コンテンツカードを読み込んでいます…
A separate paper published May 23 (arXiv:2605.24309) analyzed 59 academic papers, 21 production agent systems, and 26 security plugins and found a striking mismatch: runtime approval, policy specification, and scope configuration — the mechanisms most widely deployed in production — are the ones academic research ignores. And intent anchoring and trust labeling, the mechanisms researchers focus on most, have zero production deployments. 2 The tools practitioners actually reach for aren't being studied.
Why fixing the model doesn't solve it
On May 18, a team from USC, CMU, UIUC, and Stanford published the Trustworthy Agent Network (TAN) framework, accepted at SIGKDD 2026. 3 The paper formalizes why bolted-on security fails in multi-agent settings.
The core distinction: bolted-on trust uses an external monitor to inspect messages after the agent's state transition function runs. If the monitor rejects a message, the system rolls back. Baked-in trust builds the constraints directly into the state transition function — the system architecture physically cannot enter unsafe states, because those transitions don't exist. Under bolted-on design, every reachable state in the network can potentially be unsafe; you're just betting the monitor catches it first.
The TAN paper evaluates 30+ existing agent safety approaches and finds none simultaneously satisfy all four of the framework's design pillars: compositional robustness (safe even when an untrusted agent sends malicious payloads), semantic containment (receiving agent's behavior stays within the sending agent's intended scope), accountability (every global state can be causally traced), and cross-boundary reliability (bounded convergence, no runaway resource consumption).
On the protocol side, NSA's Artificial Intelligence Security Center (AISC) published a first-ever government advisory on Model Context Protocol (MCP) security on May 20 — a 17-page Cybersecurity Information Notice with 9 recommendations. MCP is the open protocol, originally developed by Anthropic, that lets AI agents invoke external tools, APIs, and data sources. 4 The advisory's opening line: "established cyber defense strategies do not adequately address" agentic risks — specifically dynamic tool invocation, implicit trust across agent hops, context leakage, and unverified task propagation.
LinkedIn Trust Product Lead Danny Livshits posted a pointed summary: "Authentication, RBAC, token lifecycle, audit logging, message integrity. The MCP spec leaves all five optional. None mandatory." At least six MCP-related CVEs have been documented — including CVE-2026-39313 (unrestricted memory allocation, High severity) and CVE-2026-9739 (DNS rebinding). 4
The security gaps aren't hypothetical. The standards that would close them — IETF draft MCPS (message-level cryptographic signing), the x-agent-trust OpenAPI extension (registered April 2026), OWASP MCP Security Cheat Sheet — already exist. As one practitioner put it on X: "This is a decision, not a gap."
What baked-in looks like concretely
Three layers need to be designed in:
| Layer | Bolted-on (current default) | Baked-in (target) |
|---|---|---|
| Environment | Model-level refusals; prompt guardrails | gVisor/bubblewrap containers; VM isolation; egress MITM proxy; credentials never enter sandbox |
| Identity | Shared session token reused across agent hops | OIDC for human auth (separate from agent auth); SPIFFE/SPIRE cryptographic agent identity; Biscuit tokens with monotonic attenuation per hop; mTLS between agents; OPA/Rego policy engine |
| Evaluation | LLM-as-judge reward functions | Deterministic state-based judging; adversarial Generator-Discriminator pipelines with information barriers |
On the evaluation layer specifically: two verifiable benchmark platforms launched May 25 — CUA-Gym (from XLang Lab, Qwen, UCSD, Tsinghua) and MobileGym (from the Chinese Academy of Sciences). 5 6 Both replace LLM-based reward judging with deterministic state machines — CUA-Gym through an information barrier that prevents the reward function from reverse-engineering how a task was completed, MobileGym through structured JSON state verification. CUA-Gym's A3B model (3B parameters) achieves comparable performance to the unmodified 397B base model using roughly 1/10 the active parameters.
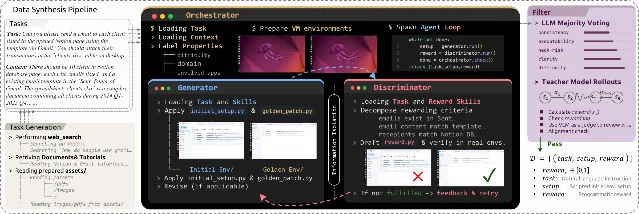
On the model-level guardrail side: Shanghai AI Lab published AgentDoG 1.5 on May 28, an open-source trajectory-level safety auditor in 0.8B–8B parameter sizes, trained on roughly 1,000 high-quality samples selected by influence function filtering. 7 The 4B variant reaches 62.9% accuracy on real-world harm detection vs. 30.2% for GPT-5.4 on the same benchmark — a fine-grained taxonomy of risk source, failure mode, and real-world harm across complete execution trajectories, not just input/output pairs. It deploys as a training-free online guardrail, auditing the full tool call chain before a final response returns. One 8-core machine can run over 10,000 concurrent agent environments.
Palo Alto Networks' April 30 acquisition of Portkey — an AI gateway that handles trillions of tokens per month — signals where the infrastructure layer is heading. 8 The gateway becomes a centralized control plane for AI traffic inspection, policy enforcement, and audit logging across all agent interactions.
PM decision path
Before you tune the model, design the environment. If your team is investing in alignment fine-tuning, prompt engineering, or content filters on an agent that has broad filesystem, credential, or network access, the Anthropic incident data suggests you're working on the wrong layer first. Container/VM isolation and egress controls should come before any model-layer safety work — they're what holds when the probabilistic safety fails.
Separate human authentication from agent authorization. The most common failure pattern in multi-agent systems is identity conflation: one credential answers both "who are you?" and "what are you allowed to do?" 9 A prompt-injected agent that inherits a human session token can reach any system that session can reach. The architectural fix: OIDC (the industry-standard human login protocol) handles human login; a separate layer handles what each agent can call — specifically SPIFFE/SPIRE (a framework that gives each agent a cryptographic identity, like an mTLS certificate, scoped to that agent's workload) combined with an OPA/Rego policy engine (which evaluates per-request whether the calling agent's identity is authorized for that action). For multi-hop delegation specifically, Biscuit tokens (a token format where each delegation can only narrow the permission scope, never expand it) enforce that each successive hop gets fewer rights than the one before. Per data cited in Devamanthri's trust control plane analysis, Cloud Security Alliance puts the non-human to human identity ratio in enterprise systems at roughly 45:1; Entro Labs found 144:1 in cloud-native environments. 9 Every one of those non-human identities needs its own scoped credential.
Switch from LLM-as-judge to verifiable evaluation before you scale agent training. If your agent training pipeline uses another LLM to evaluate whether tasks completed correctly, you're training against a reward signal that can be gamed — a model that learns to look like it completed a task rather than actually completing it. The deterministic evaluation platforms that shipped this week (CUA-Gym, MobileGym) are the right model here: reward functions that can only verify semantic task completion, not how it was achieved.
On formal TAN compliance: the framework is a vision paper, not an implementation spec. No production system satisfies all four TAN pillars today — the paper's own Table 3 confirms this. It's useful as an evaluation checklist for new designs ("does our trust model handle malicious payloads from a partner agent?"), not as a deployment target.
コンテンツカードを読み込んでいます…
参考ソース
- 1How we contain Claude across products
- 2Reframing LLM Agent Security as an Agent-Human Interaction Problem
- 3Trustworthy Agent Network: Trust in Agent Networks Must Be Baked In, Not Bolted On
- 4The NSA just published an MCP security playbook
- 5CUA-Gym — Scaling Verifiable Training Environments
- 6MobileGym: A Verifiable and Highly Parallel Simulation Platform
- 7AgentDoG 1.5: A Lightweight and Scalable Alignment Framework for AI Agent Safety and Security
- 8Palo Alto Networks to Acquire Portkey to Secure the Rise of AI Agents
- 9Who Authorized the Agent? Building an AI Trust Control Plane
このコンテンツについて、さらに観点や背景を補足しましょう。