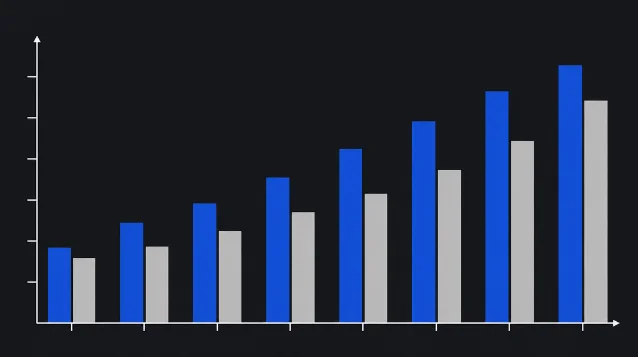
Aider Polyglot 代码基准一年内提升
5×
SWE-bench 软件工程 agent 同期提升
2×
单次请求可处理视频长度
3h
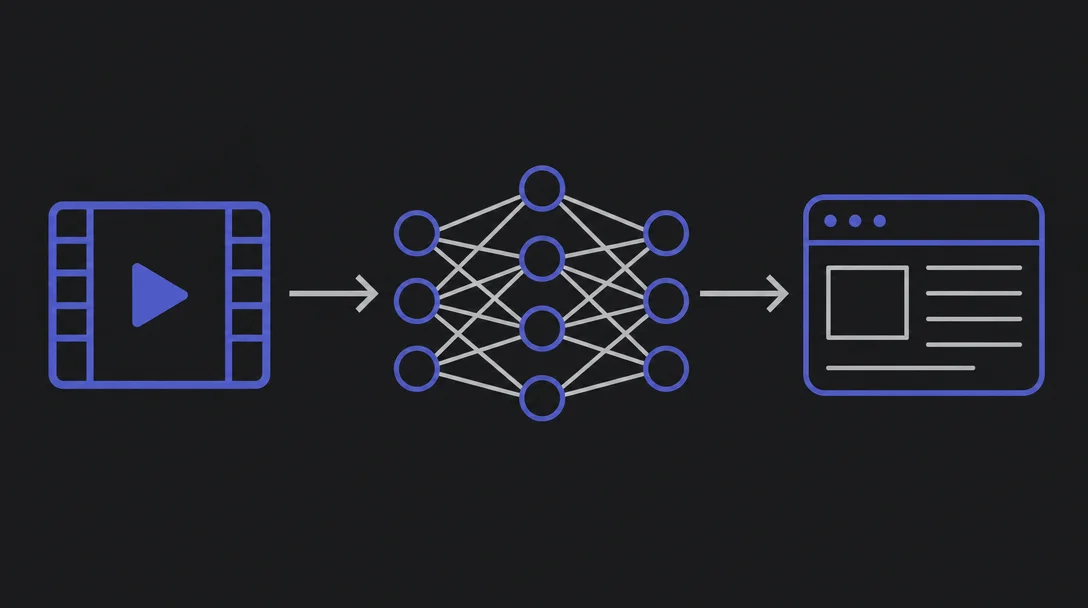
Google DeepMind 发布 Gemini 2.5 技术报告,介绍 2.X 模型家族。Gemini 2.5 Pro 以思考模型定位、3 小时视频处理能力和前沿代码/推理 SoTA 性能为核心卖点;报告同时揭示了当前 benchmark 生态面临的快速饱和问题,以及「推理 + 长上下文 + 多模态」三者组合对智能体工作流的影响。
リサーチノート
| 型号 | 定位 | 特点 |
|---|---|---|
| Gemini 2.5 Pro | 旗舰推理 | 最强代码与推理能力,当前 SoTA |
| Gemini 2.5 Flash | 高效推理 | 少量算力即具备强推理,低延迟 |
| Gemini 2.0 Flash | 高性能入门 | 低延迟低成本下的均衡方案 |
| Gemini 2.0 Flash-Lite | 超轻量 | 极低成本,大规模部署场景 |
| 基准 | 领域 | 备注 |
|---|---|---|
| Aider Polyglot | 代码跨语言任务 | 一年内提升 5× |
| SWE-bench verified | 软件工程 agent | 同期提升 2× |
| GPQA Diamond | 专业科学推理 | 顶尖水平 |
| Humanity's Last Exam | 高难度综合考试 | 单题悬赏最高 $5000 |
| 公司 | 代表模型(2025) | 智能体核心能力押注 |
|---|---|---|
| Google DeepMind | Gemini 2.5 Pro | 长视频理解 + 超长上下文 + 多模态推理 |
| Anthropic | Claude Sonnet 4 / Opus 4 | 代码智能体 + 安全对齐 + 计算机控制 |
| OpenAI | GPT-4.1 / o3 | 代码生成 + 推理模型 + 函数调用生态 |
このコンテンツについて、さらに観点や背景を補足しましょう。