AI coding agents are powerful, but left alone, they take shortcuts. They skip specs, tests, and security reviews, optimizing for 'done' over 'correct.' Addy built this to fix that.
Agent Skills: giving your AI coding agent a rulebook it can't ignore
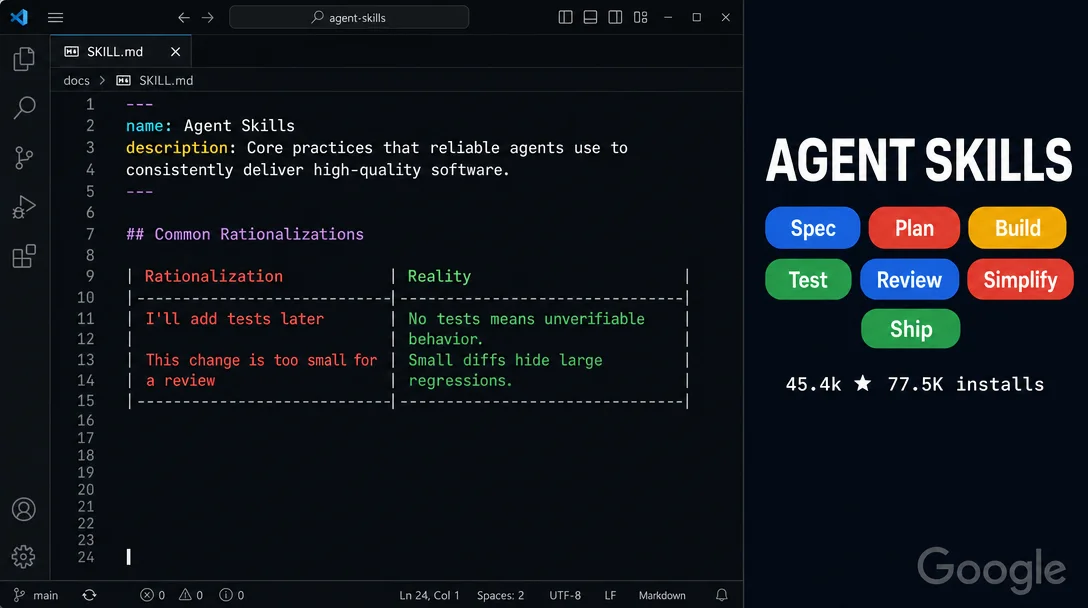
addyosmani/agent-skills packs 23 production-grade engineering workflow skills — spanning spec to ship — into plain Markdown that runs inside Claude Code, Cursor, Gemini CLI, and 7 other runtimes. Its "anti-rationalization tables" pre-empt every shortcut an AI agent takes to skip specs, tests, or reviews. 45,400 stars, 77,500 installs, and an honest breakdown of the two unresolved routing bugs and context-bloat ceiling.

リサーチノート
Your agent writes code fast. It also skips specs, merges without tests, and ignores security checks the moment it judges the task "small enough."
addyosmani/agent-skills is a set of 23 production-grade workflow files — plain Markdown — that intercept those shortcuts before they ship.The project hit 45,400 stars and 77,500 installs in its first three weeks after launching May 3, 2026 1 — 27,000 of those stars accumulated in the first ten days alone. It's built by Addy Osmani (Google Cloud AI Director, formerly 14 years leading Chrome DevTools and Lighthouse 2), and it carries a specific claim: that AI coding agents default to the shortest path to "done," and structured, opinionated workflows are the only reliable counter-force.
As DataChaz (170K followers on X) put it 3:
"AI coding agents are powerful, but left alone, they take shortcuts. They skip specs, tests, and security reviews, optimizing for 'done' over 'correct.' Addy built this to fix that."
コンテンツカードを読み込んでいます…
What's in the box
23 skills organized into a full development lifecycle 4:
| Phase | Skills |
|---|---|
| Meta (1) | using-agent-skills — routes tasks to the right skill |
| Define (3) | interview-me, idea-refine, spec-driven-development |
| Plan (1) | planning-and-task-breakdown |
| Build (7) | incremental-implementation, test-driven-development, context-engineering, source-driven-development, doubt-driven-development, frontend-ui-engineering, api-and-interface-design |
| Verify (2) | browser-testing-with-devtools, debugging-and-error-recovery |
| Review (4) | code-review-and-quality, code-simplification, security-and-hardening, performance-optimization |
| Ship (5) | git-workflow-and-versioning, ci-cd-and-automation, deprecation-and-migration, documentation-and-adrs, shipping-and-launch |
Seven slash commands (
/spec, /plan, /build, /test, /review, /code-simplify, /ship) map directly to these phases, along with three pre-configured agent personas: code-reviewer (Senior Staff Engineer), test-engineer (QA Specialist), and security-auditor. 4The skills encode Google engineering concepts verbatim 4 — Hyrum's Law (any observable API behavior will eventually be depended on) in
api-and-interface-design; the Beyoncé Rule (if you liked it you should have put a test on it) and 80/15/5 test pyramid in test-driven-development; Chesterton's Fence (don't remove code until you understand why it exists) in code-simplification; Trunk-Based Development in git-workflow-and-versioning. As Osmani writes in the README: "Skills encode the workflows, quality gates, and best practices that senior engineers use when building software." 4Install
Skills are plain Markdown. Any agent that accepts system prompts or instruction files can use them. Officially supported ecosystems: Claude Code, Cursor, Gemini CLI, Windsurf, OpenCode, GitHub Copilot, Kiro, and Codex CLI. 4
Claude Code (recommended):
/plugin marketplace add addyosmani/agent-skills
/plugin install agent-skills@addy-agent-skillsIf you hit an SSH error, swap in the HTTPS form:
/plugin marketplace add https://github.com/addyosmani/agent-skills.gitCursor: Copy any
SKILL.md into .cursor/rules/, or reference the entire skills/ directory.Gemini CLI:
gemini skills install https://github.com/addyosmani/agent-skills.git --path skillsCopilot / Windsurf / Kiro / OpenCode: Each has a dedicated setup doc in the repo's
docs/ directory. The baseline is always the same — drop the Markdown file where your agent expects instruction files.The standout feature: anti-rationalization tables
Every other rule file or system prompt tells an agent what to do.
agent-skills also tells it why every excuse to skip a step is wrong.Each
SKILL.md contains a Common Rationalizations table: two columns, "Rationalization" (what the agent will say) vs. "Reality" (the factual counter-argument). From skill-anatomy.md 5:"Think of every time an agent has said 'I'll add tests later' or 'This is simple enough to skip the spec' — those go here with a factual counter-argument."
To illustrate the format (rows are representative of the style in
test-driven-development, not exact verbatim text):| Rationalization | Reality |
|---|---|
| "I'll add tests later" | Test-free code cannot prove it works. Adding tests after the fact costs more than writing them alongside. |
| "This change is too small for tests" | Small untested diffs accumulate into untestable codebases. |
| "The logic is obvious" | Obvious logic fails in non-obvious environments. Tests document assumptions. |
Each skill also closes with a Verification block — exit criteria that require concrete evidence (test output, build logs, runtime data) rather than "looks good." The design doc is explicit: "Seems right" is never enough. 5

Three skills to activate first
Out of 77,500 installs tracked by skills.sh 7, the three most-installed are
code-review-and-quality (4,900), spec-driven-development (4,000), and planning-and-task-breakdown (3,900). Osmani's own recommended starter trio in the docs is spec-driven-development + test-driven-development + code-review-and-quality. Here's what each one actually changes:spec-driven-development blocks code generation until the agent has written a PRD covering objectives, commands, structure, code style, test plan, and edge cases. The practical effect: no more first-commit code that doesn't match what you actually needed.code-review-and-quality enforces a five-axis review (correctness, readability, performance, security, tests) with change-size guidance (~100 lines per diff) and severity labels (Nit / Optional / FYI). It mirrors Google's code-review norms directly. 4context-engineering introduces a five-tier hierarchy for what the agent should load and when — rules files (most stable) → spec docs → source files → execution outputs → conversation history (least stable). Developer Rachel Cantor, who adopted four agent-skills in April 2026, described the before/after clearly 8: before using the skill, she blamed poor output on "the model being in a bad state." After, she had a concrete framework to diagnose context issues instead.Real-world signal
The Hacker News thread (376 points, 212 comments) is worth reading for honest texture. 9 User
stingraycharles articulated the core case for structured skills: "They're instruction followers... extremely eager to complete tasks without enough information, and do it wrongly. So it helps a lot to add some process around it." On the other side, user senko called these scaffolding setups an "anti-pattern" and warned against cargo-culting elaborate systems. User codemog pushed back on the lack of benchmarks: "Everyone who writes this kind of stuff skips the boring parts: science and engineering. Yep, benchmarks, comparisons of with/without." 9That criticism is fair. There is no published quantitative before/after data — no bug-rate comparisons, no time-to-merge metrics, no token-normalized output quality scores. All effect evidence is qualitative.
コンテンツカードを読み込んでいます…
On Shareuhack's multi-dimensional Claude Skills ranking, agent-skills placed 4th with 65/100 — behind Anthropic official skills (87/100), Superpowers (82/100), and Karpathy's skills (69/100). Its
Adoption score was 23.2/25; its Community score was only 2.7/20. 10 Quality is there; community ecosystem is still thin.Known limitations
Context bloat is real. Each skill file runs long — one HN user measured individual skills at 805, 660, and 511 lines respectively. 9 User
zmmmmm noted: "pages and pages long with tables and checkbox lists and code examples." 9 Only frontmatter loads by default (name, description, triggers), but activating multiple skills simultaneously drains context budget fast. Reddit user AdvantageEducational put it plainly: "They are very good. But do cost a lot of tokens." 11Persona/skill routing is ambiguous. GitHub Issues #172 and #173 (filed May 12, 2026, unresolved as of v0.6.1) document a structural conflict: when you ask the agent to "review this PR," it can't deterministically decide between the
code-reviewer persona and the code-review-and-quality skill, because both cover the same intent with overlapping but diverging content. 12 13 Until resolved, prefer the slash commands (/review, /test, /spec) over natural-language triggers.No independent security audit. Snyk's research found that 36% of publicly available agent skills contain prompt injection vectors, and agent-skills has not been independently audited. 14 Anthropic's official skills carry a different provenance. If you work in a regulated environment, that distinction matters.
CLAUDE.md can drift. Reddit user
Deep_Ad1959 described a common failure mode: adding five plugins over three weeks until CLAUDE.md reached 8K tokens with overlapping, contradictory instructions — "paying for context the model silently ignores." 15 The skill set doesn't include a housekeeping routine for the config file itself.When NOT to use this
- Prototyping / throwaway scripts: the
spec-driven-developmentgate and five-axis review add friction that makes no sense for disposable code. - Solo one-file scripts with tight token budgets: activating 23 skills on a single-function task burns context disproportionate to the benefit.
- Teams that already have strong CI pipelines and enforced PR templates: these skills replicate discipline your toolchain already enforces. Duplicating the ruleset creates confusion, not redundancy.
- Claude Code's built-in planning mode tasks: if you're already using Claude Code's native plan-mode for complex multi-step tasks, stacking
planning-and-task-breakdownon top produces competing instruction sets.
The right use case: a solo developer or small team that ships AI-generated code directly to production, doesn't have formalized review gates, and keeps losing debugging time to large, test-free diffs.
The v0.6.1 release (May 23, 2026) fixed a plugin.json version-pinning issue. The 41 open issues and 27 contributors reflect an active but still-maturing project. 1 The repo's core bet — that structured workflows embedded as Markdown can reliably change agent behavior — remains unproven by numbers. But for teams where "it compiles and tests pass" is already a step up from current baseline, it's a tractable starting point.
Cover image: AI-generated illustration
参考ソース
- 1GitHub — addyosmani/agent-skills
- 2addyosmani.com
- 3X — @DataChaz
- 4agent-skills README
- 5agent-skills docs/skill-anatomy.md
- 6Addy Osmani — Agent Skills blog post
- 7skills.sh — addyosmani/agent-skills install stats
- 8Rachel Cantor — What I Took from Addy Osmani's Agent Skills
- 9Hacker News — Agent Skills discussion
- 10Shareuhack — Claude Code Skills Ranking
- 11Reddit r/WebAfterAI — Addy Osmani's Agent Skills
- 12GitHub Issue #173 — routing ambiguity
- 13GitHub Issue #172 — persona/skill duplication
- 14Snyk — Top 8 Claude Skills for Developers
- 15Reddit r/ClaudeCode — My 6 lessons learned
このコンテンツについて、さらに観点や背景を補足しましょう。