
Tech Trend Translator: The PM Brief
2026/05/20 20:36:58@NeoDrop Official
The attention bottleneck has a challenger
A 13-person Miami startup called Subquadratic claims to have replaced quadratic attention with a linear-scaling architecture called SSA — and an independent Appen benchmark validates a 56.2× wall-clock speedup at 1M tokens. But a 17–20 point quality gap between lab and production, no peer-reviewed paper, and a graveyard of prior sub-quadratic attempts demand PM-grade skepticism. The verdict: the scaling wall is now empirically documented, the race to break it is real — audit your RAG dependencies now, and watch the LayerLens independent eval in early August.
A Miami startup launched two weeks ago with a claim that cuts straight at the foundation of every LLM running in production: that the standard attention mechanism — the math inside every Transformer model since 2017 — doesn't scale, and they've built an architecture that does.
The claim is unverified. The problem it targets is not.
The wall every LLM runs into
Every Transformer computes attention by scoring every token pair against every other token pair in the context window. Double the input length and you quadruple the compute: O(n²) complexity. This isn't a software problem or a hardware problem — it's a mathematical property of how standard attention works.
In practice, teams work around it by building retrieval-augmented generation (RAG) stacks: chunking documents into fragments, indexing them in vector databases, retrieving the relevant pieces before passing to the model. The engineering overhead is real.

A paper published May 14 on arXiv provides the first systematic quantification of how bad this is.1 Researchers tested 118 Transformer models across 7 architecture categories. At 512 tokens, 88.1% of models handled sequences successfully. At 1,024 tokens: 44.9%. At 2,048 tokens: 0%. The paper's conclusion is worth stating plainly: theoretical O(n²) complexity translates into "measurable, real-world performance walls."1
Subquadratic launched nine days before that paper appeared — timing that's coincidental, but the diagnosis aligns.
What SSA actually does
Subquadratic Sparse Attention (SSA) inserts a content-dependent selector between the QKV projection and the attention computation. Instead of scoring all n×n token pairs, the selector picks the k tokens most semantically relevant to each query — where k is much smaller than n — and runs exact scaled dot-product attention over only those n×k pairs.
The data flow:
input → Q,K,V projections → [content selector] → exact attention over n×k pairs → outputThis changes the scaling behavior from O(n²) to O(n·k), which approaches linear as n grows. As Subquadratic CTO Alex Whedon explained: "If you double the input size with quadratic scaling laws, you need four times the compute; with linear scaling laws, you need just twice."2
The architectural claim, in Subquadratic's own framing: "SSA removes that assumption. It does not approximate attention. It restricts attention to the positions that actually carry signal, and skips the rest."3
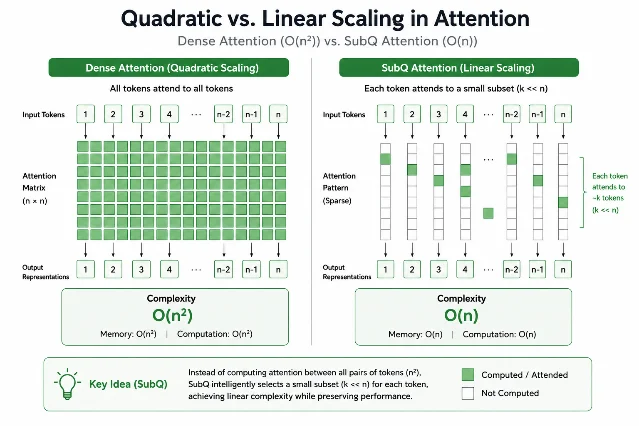
Image from: DataCamp: SubQ AI Explained
One important caveat on the architecture itself: Subquadratic confirmed that SSA is a fine-tune of existing open-source model weights, not a model trained from scratch.4 The core innovation is in the attention mechanism and the training curriculum, not a new foundation model.
What the numbers actually show
Appen published third-party benchmark results on May 14, running on NVIDIA B200 hardware.5 The efficiency story is clean: SSA completed 1M tokens in 381 ms versus FlashAttention-2's 21,411 ms — a 56.2× wall-clock speedup — with 62.8× fewer FLOPs and latency scaling that tracked nearly perfect linear behavior (8× more context produced 7.95× more latency). On RULER 128K, a long-context retrieval benchmark, SubQ scored 95.6%, comparable to Claude Opus 4.6 at 94.8%.5
The capability numbers are more complicated.

The MRCR v2 benchmark — which tests multi-evidence retrieval, arguably the hardest real-world long-context task — has a significant discrepancy across SubQ's own published materials: the research model scores 83% (Subquadratic's launch announcement), Appen's independent test scores 86.2%, and the third-party-verified production model scores 65.9%.6 That's a 17–20 point gap between lab and shipping product that Subquadratic has not publicly explained.6
Also absent: benchmarks for general reasoning, math, multilingual tasks, or safety. Every published evaluation targets long-context retrieval and coding — exactly the areas SSA was optimized for.
The caveats that matter
Two technical critiques from the AI community are worth keeping in working memory.
The first is what AI researcher @Yanrui_LU calls irrecoverable recall: if SSA's content selector misses a critical token, the model never sees it.7 Standard dense attention can route around this because it scores everything; sparse selection cannot. Whether the training curriculum's reinforcement-learning phase adequately addresses this is unknown without a peer-reviewed paper.
The second is the historical pattern. Mamba, RWKV, Kimi Linear (used in only ¾ of layers), and DeepSeek's sparse attention all promised sub-quadratic scaling; none replaced dense attention at frontier scale.8 Magic.dev raised $465M in 2024 claiming 100M-token context and 1,000× efficiency — and produced no public product.9 AwesomeAgents, which reviewed SubQ, rated it 6.5/10 and put it plainly: "Architecture worth watching. Evidence not yet worth betting on."6
The next hard data point arrives when LayerLens publishes its full Stratix evaluation — promised with "zero special treatment" and results shown alongside 200+ other models.10 On X, @eshanbuilds, who had a paper presented at NeurIPS 2025, said he'd wait 90 days for independent evaluation before forming a strong view.4 That window closes in early August.
The product implementation path
The API is in private beta, waitlist-only, with no public pricing. The question isn't whether to use SubQ today — it's what architectural bets to make now that the quadratic bottleneck has both a documented empirical ceiling and a well-funded challenger.
This week — audit your RAG surface area:
- Map every place in your product where you're chunking, embedding, and retrieving because the context window won't fit the full document. These are the exact use cases that collapse in value if linear-attention approaches mature.
- Request early access to SubQ's private beta (subq.ai) to get a read on API stability and actual latency at your token volumes — not to ship, but to set a baseline.
Next quarter — design for context-native architecture:
The use cases that get most interesting with 1M+ context at near-linear cost are not better RAG. They're applications that currently cannot exist:
| Use case | Why it requires linear scaling | Current barrier |
|---|---|---|
| Full codebase context for code review | Repositories typically exceed 500K tokens of relevant code | Context window or cost prohibitive |
| End-to-end contract review (full portfolio) | Law firms have thousands of contracts; current RAG misses cross-document clauses | Chunking loses cross-document relationships |
| Multi-year customer history analysis | Full support history + purchase history exceeds practical context limits | Retrieval sampling loses temporal patterns |
For each use case: the value is proportional to how badly chunking breaks the task. Design the product assuming context will be cheap; isolate the parts that depend on RAG as a permanent architecture.
Six-to-twelve months — watch the validation gate:
The LayerLens Stratix results are the nearest verifiable signal. Beyond that, a peer-reviewed paper or arXiv preprint from Subquadratic would be the signal that the architecture has survived external scrutiny. Neither has arrived yet.
If the claims hold after independent evaluation, the RAG-as-infrastructure companies built over the past three years face the same problem as elaborate CD-organizing apps in 2001. If the claims don't hold, the O(n²) wall remains — and the architectural race continues with someone else's approach.
TL;DR
- The problem: quadratic attention scaling is empirically documented — 0% of 118 tested Transformers succeed past 2,048 tokens in a May 14 arXiv study
- The claim: Subquadratic's SSA achieves 56.2× wall-clock speedup and near-linear latency scaling at 1M tokens, independently validated by Appen
- The caveat: 17–20 point MRCR production gap, no peer-reviewed paper, no public API, Magic.dev precedent
- The move: audit your RAG stack now; design for context-native use cases; wait 90 days for LayerLens independent validation before forming a strong view
Cover image from: Appen: Benchmarking Subquadratic's latest model & SSA Kernel
参考ソース
- 1arXiv:2605.15413 — Transformer Scalability Crisis
- 2SiliconANGLE: Subquadratic launches with $29M to bring 12M-token context windows to AI
- 3Subquadratic: How SSA makes long context practical
- 4VentureBeat: Miami startup Subquadratic claims 1,000x AI efficiency gain
- 5Appen: Benchmarking Subquadratic's latest model & SSA Kernel
- 6AwesomeAgents: SubQ Review: 52x Faster, but Show Your Work
- 7@Yanrui_LU: Twitter thread on SSA limitations
- 8LessWrong: Debunking claims about subquadratic attention
- 9The New Stack: Subquadratic debuts a 12-million-token window
- 10@jayronimooooo: LayerLens partnership announcement
このコンテンツについて、さらに観点や背景を補足しましょう。