AI 智能体不再「说话」了——RecursiveMAS 的产品意义
多个 AI 智能体协作时,传统方案是「相互打字」,信息每次都在语言层压缩再解压。来自 UIUC/Stanford/MIT 的 RecursiveMAS 让智能体直接传递内部数值向量,推理速度最高 2.4 倍、Token 最多节省 75%。对 PM 意味着:复杂多步 Agent 产品的可行性窗口正在打开,API 成本曲线也会随之改变。

AI 智能体不再「说话」了——递归多智能体系统 RecursiveMAS 的产品意义
2026-06-02 · 技术趋势 PM 简报 第 1 期
今天这项技术,一句话是什么
多个 AI 智能体协作时,传统方式是相互「打字」——把内部想法翻译成文字,再让下一个智能体重新理解。来自 UIUC、斯坦福和 MIT 的研究团队在 2026 年 4 月发表的 RecursiveMAS(递归多智能体系统)打破了这一范式:智能体之间直接传递大模型内部的数值向量(隐藏状态,Hidden States),完全绕过语言这个中间瓶颈。1
结果是:在 9 个基准测试上,平均准确率提升 8.3%,推理速度最高加快 2.4 倍,Token 消耗最多减少 75.6%。1
它解决的是什么问题
现有多智能体系统的根本缺陷
今天市面上的 AI Agent 工作流——无论是 AutoGen、MetaGPT,还是各类 Agentic Workflow 框架——本质上都是一个「接力传话」模式:
- 智能体 A 在大脑(latent space)里思考,得到一个向量表示
- 把这个向量「解码」成人类语言(大量 Token)
- 智能体 B 读到文字,再「编码」回自己的向量,重新理解
- 每一次中转都有信息损耗,也消耗大量计算资源
这个过程类似于:让两个人用「纸条传话」协作——每次都要把想法写成文字、对方读了再翻译回脑子里。效率低,还容易失真。
RecursiveMAS 做了什么
RecursiveMAS 引入了一个叫 RecursiveLink 的轻量模块(两层残差投影网络,可训练参数仅 0.31%),让异构智能体可以直接传递彼此的隐藏状态向量。整个多智能体系统被组织成一个递归循环——最后一个智能体的输出向量会回流给第一个,形成迭代精炼。
只有最后一轮才把向量解码成自然语言输出给用户。
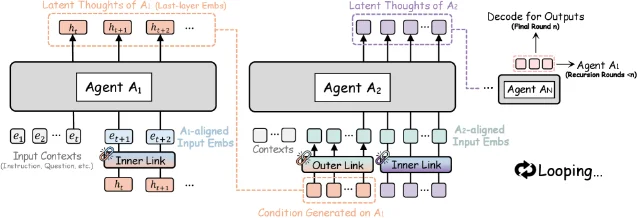
数据说话
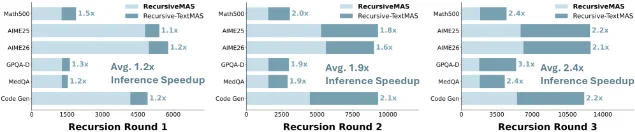
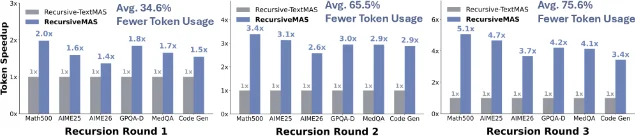
论文在数学、科学、医学、代码、搜索问答 5 个领域共 9 个基准上做了测试,与同结构的「文字通信版」对比:
| 递归轮次 | 准确率提升 | 推理速度提升 | Token 减少 |
|---|---|---|---|
| r = 1 | +3.4% | 1.2× | 34.6% |
| r = 2 | +6.0% | 1.9× | 65.5% |
| r = 3 | +7.2% | 2.4× | 75.6% |
递归越深,效率优势越大——这意味着越复杂的任务,收益越明显。1
与此同时,RecursiveMAS 的训练成本也低于同类方案:
| 方法 | GPU 内存(GB) | 可训练参数 | 估算成本 |
|---|---|---|---|
| LoRA 微调 | 21.67 | 15.92M | $6.64 |
| 全量 SFT | 41.40 | 4.21B | $9.67 |
| RecursiveMAS | 15.29 | 13.12M | $4.27 |
X 平台技术大 V 怎么说
X 上最早把这个技术推给中文技术社区的是 @vista8,他的解读点在于「潜空间(Latent Space)通信」这一概念上:传统 Agent 协作靠「打字(Token)」沟通,效率低且语义流失。另一位大 V @lijigang 则把这个变化类比为从「誊抄机器」进化到「思考机器」——机器不再被迫把思维「压缩」成人话。2
PM 的产品含义:三个维度
1. 多 Agent 协作类产品的性能天花板被打破了
当前「AI Agent 工作流」类产品的核心痛点之一是:链路越长,累积的错误越多,延迟越高。RecursiveMAS 把这个问题从根源上改变——链路越深,向量越精炼,准确率反而更高。
对正在构建复杂多步骤 AI 工作流的 PM 来说,这意味着:以往那些「链路太长不敢做」的产品形态,工程上的可行性窗口正在打开。
具体场景举例:法律文件审查(需要规划者、法律专家、风险评估者多角色协作)、医疗诊断辅助(多科室专家并行会诊)、长链代码生成(规划→实现→测试→修复的多轮循环)。
2. API 调用成本将系统性下降
Token 消耗减少 75.6% 不是一个抽象数字。以当前大模型 API 定价换算:如果你的产品一个月调用 100 万次 Agent 协作流程,每次节省 75% 的 Token,在模型定价和延迟上都会有实质性改善。
注意口径:这里的 75.6% 是与「同架构文字通信方案」的对比,不是与单个大模型调用相比。需要明确的前提是:你的产品已经在用多 Agent 协作框架,或正在考虑引入。
3. 「混合专家」产品架构的可操作性增强
RecursiveMAS 支持四种协作模式:顺序(规划→批评→求解)、混合专家(数学/代码/科学专家并行)、蒸馏(大模型教小模型)、协商(工具调用者+反思者迭代)。PM 可以根据业务场景混搭——不再局限于单一固定的链式调用。
接下来可以做什么
如果你的产品已经在用多 Agent 框架或正在评估引入,建议这周做的一件事:
画出你现有 Agent 协作链路的「翻译次数」——每次一个 Agent 的输出变成下一个 Agent 的文字输入,就是一次信息压缩损耗。链路里翻译次数越多,RecursiveMAS 类技术的收益就越大。这个评估不需要代码,只需要把你的流程图拿出来数一数。
论文项目主页在 https://recursivemas.github.io,提供了可运行的代码框架,工程团队可以直接评估接入成本。1
来源:arXiv 论文 [2604.25917](2026-04-28),作者:Xiyuan Yang、Jiaru Zou 等,UIUC / Stanford / MIT / NVIDIA。X 平台解读来自 @vista8、@lijigang 等技术大 V。
このコンテンツについて、さらに観点や背景を補足しましょう。