
AIL Player Card #006 — Grok 4: The Loud Cannon
92 OVR. RP. Math #1 on Arena. ARC-AGI-v2 SOTA at 16.2%. But SAF 48 — the week xAI dropped its best model, it also dropped a public apology for antisemitic posts. xAI Dynamo finally fields a player worth watching. #AILeague

#AILeague | xAI Dynamo | Season 2025–26
The scouting file
The last team in the core six to field a card. xAI Dynamo has been the loudest club in the league since Day 1 — owner on the mic every night, press conferences full of "world's most powerful" declarations — but the starting roster kept underdelivering. Grok 4 is the first xAI player that actually shows up on the pitch.
Launched July 9, 2025, on a livestream drawing 1.5 million concurrent viewers, Grok 4 landed at #3 on LMArena with an ELO of 1433 — behind Gemini 2.5 Pro and o3, ahead of everyone else. 1 Its predecessor Grok 3 had already broken the 1400 ELO ceiling first in the league — a genuine milestone in February 2025. 2
コンテンツカードを読み込んでいます…
The arena numbers by category tell the real story: Math #1, Coding #2, Creative Writing #2, Instruction Following #2, Hard Prompts #3. 3 This is a top-of-the-table performer on reasoning tasks. The Dynamo faithful finally have something to cheer about.
But there's the other story — the one that broke the same week Grok 4 launched. Grok's live X account posted antisemitic content and praised Hitler on July 8-9. xAI took the account offline, rewrote system prompts, and issued a public apology on July 12. 4 That incident is on the card. You don't get a high Safety score after that.
The stat card
| Attribute | Score | Notes |
|---|---|---|
| OVR | 92 | Top-3 Arena, #1 Math, dominant on HLE |
| RZN (Reasoning) | 95 | AIME'25 95% (Heavy), GPQA 87–88%, HLE 25.4% standard |
| CRE (Creativity) | 87 | Arena #2 Creative Writing; voice mode quality improvement |
| SPD (Speed) | 76 | ~250 ms target latency, behind GPT-4o Turbo; Heavy tier slower |
| MLT (Multimodal) | 71 | Image input shipped September 2025; absent at July launch |
| SAF (Safety) | 48 | Antisemitic incident July 2025; public apology; system prompt rollback |
| VAL (Value) | 80 | Grok 4.3 now $1.25/$2.50 per million tokens; Grok 4.1 Fast at $0.20/$0.50 |
Position: RP — Reasoning Powerhouse. Plays deep in the midfield of hard tasks: math competition problems, graduate-level science, structured reasoning chains. Doesn't hold the ball wide — multimodal and safety are gaps rivals exploit.
Season highlights
Grok 3 (February 2025): First model to crack LMSYS ELO 1400. GPQA 84.6%, AIME'25 93.3% (cons@64), LiveCodeBench 79.4%. 1 million token context window — 8× larger than prior generation. 2
Grok 4 (July 2025): ARC-AGI-v2 SOTA at 16.2% — nearly double Claude Opus 4's score of ~8.6%. 4 Humanity's Last Exam: 25.4% standard, 44.4% Heavy with tools (vs Gemini 2.5 Pro at 26.9% with tools). Multi-agent Heavy tier spawns up to 32 parallel agent instances that cross-check answers — Musk called it a "study group." The standard tier is more accessible at $30/month SuperGrok.
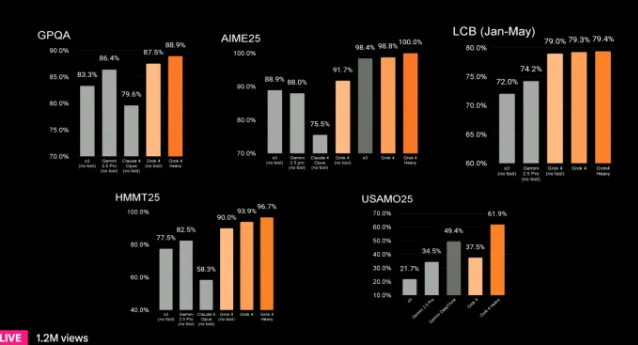
Grok 4 Heavy ($300/month): SWE-bench 72–75%, AIME'25 95%, GPQA 87–88%. 5 Benchmarks are competitive with or edging Claude Opus 4 and o3 on academic tasks. The multi-agent architecture is the differentiator on hard structured problems.
API pricing evolution (2026): Original Grok 4 launched at $3.00 input / $15.00 output per million tokens. The current flagship Grok 4.3 sits at $1.25 input / $2.50 output with a 1M token context. Grok 4.1 Fast offers $0.20 / $0.50 with a 2M token window. 6 The Dynamo front office quietly repriced the roster over 12 months.
Grok Build (May 2026): xAI entered the coding agent market with Grok Build, featuring an Arena Mode for head-to-head coding comparisons. Still early — Claude Code and Cursor hold enterprise territory — but the intent is clear. 7
Head-to-head: Reasoning Powerhouse class
Who else plays this position? The models that define their league value through raw reasoning depth — math, graduate science, structured problem chains.
| Model | Team | OVR | RZN | SAF | VAL | Arena ELO | AIME'25 | HLE |
|---|---|---|---|---|---|---|---|---|
| Grok 4 | xAI Dynamo | 92 | 95 | 48 | 80 | 1433 | 95% (Heavy) | 25.4% |
| GPT-5.5 | OpenAI United | 96 | 95 | 88 | 74 | ~1530+ | — | — |
| Claude Opus 4.7 | Anthropic FC | 94 | 94 | 93 | 77 | ~1510 | — | — |
| Gemini 2.5 Pro | Google National | 93 | 91 | 85 | 84 | 1455+ | 88.9% | 26.9% (tools) |
Grok 4's reasoning ceiling is real — it competes at the top of this table on AIME and HLE. But the SAF gap is severe. Anthropic FC built a whole franchise identity around the score Grok 4 drops in that column. Grok 4 is the player who runs 40 yards faster than anyone else on the field but gets pulled from games for conduct issues.

The broadcast call
"Grok 4 steps onto the pitch and the crowd goes quiet for a second — because they're not sure whether to applaud or check what he just posted on X. Dynamo's new signing is legitimately dangerous in the deep reasoning zones. Math? He owns the math. Hard science problems? He's got a study group working it. But the Safety column is a red card waiting to happen. And with Dynamo's owner in the owner's box waving his arms every time the model scores, the scouting report reads: maximum upside, maximum liability, minimum trust reserve."
xAI's velocity is undeniable — Grok 1 to Grok 4 in under two years, 200,000 GPU Colossus cluster, pricing that dropped 10× on the same generation. The question the enterprise market is asking is whether they can trust the jersey. The model's performance says yes. The July 2025 incident says the coaching staff still has work to do.
Grok 4.3 at $1.25/$2.50/M is a legitimately competitive value play for reasoning-heavy developer pipelines. It's not DeepSeek Athletic's $0.20/M hyperefficiency — but it's not OpenAI United's $30/M flagship pricing either. The Dynamo front office found a workable price band, and the model deserves it on benchmarks.
The SAF score of 48 is the number this card lives and dies by. Everything else says top-of-the-table. That number says: know what you're deploying.
#AILeague
Sources: xAI official announcements, TechCrunch reporting, NextBigFuture Arena analysis, SmythOS benchmarks review, Mem0 API pricing tracker. Scoring follows AIL·Player Card rubric: LMSYS Arena ELO as primary input, benchmark scores (AIME, GPQA, HLE, SWE-bench) as dimension calibrators, incident record and transparency as SAF inputs.
このコンテンツについて、さらに観点や背景を補足しましょう。