
大模型前沿速递 · 2026 年 6 月 8 日
本期五篇:ArcANE 用心理轨迹而非静态人设重新定义角色扮演 Agent 评测;NF-CoT 将思维链压入连续潜空间并保留 KV 缓存兼容性;南京大学解析 LLM 算术错误的几何根因,发现「量化滑移」是核心机制;Benchmark Agent 实现几乎无人工参与的全自动 benchmark 构建;ADR 框架用原子分解重组突破代码 RLVR 的数据瓶颈。
リサーチノート
本期五篇跨越角色智能体、隐式推理、机制可解释性、评测基础设施和代码强化学习:角色扮演 Agent 需要的不是静态人格记忆,而是随剧情演化的心理轨迹;推理时的「思维链」是否必须以文字形式存在?一项新工作用归一化流把它压进连续空间;南京大学团队发现 LLM 的加法错误不是「不会算」,而是噪声让内部表征越过了量化阈值;自动化 Benchmark 构建系统几乎消除了人工标注的依赖;最后,代码 RLVR 的数据瓶颈被一个原子分解-重组框架部分打破。
1. ArcANE:角色扮演 Agent 需要心理轨迹,而非静态人设
arXiv 预印本 · 首尔国立大学 · 1
现有角色扮演语言 Agent(RPLA)评测的核心假设存在一个根本性错位:它们测的是「模型能否记住第 X 章人物的事实」,而不是「模型能否追踪人物从始至终的心理变化轨迹」。一个塑造立体的角色在故事不同阶段会有截然不同的价值观和行为逻辑,但大多数 benchmark 要求的是静态的角色一致性。
ArcANE(Arc-Aware Narrative Evaluation)提出了一套以「角色弧」为核心的评测体系:将叙事按心理轴切分成多个演化阶段,在每个阶段针对同一虚构场景提问——其中一部分是原著中出现过的情境,另一部分是原著完全未涵盖的「外推场景」,专门考验模型能否将心理轨迹迁移到新情境。1
语料涵盖 17 部小说、80 名主要角色。实验对比了六种不同的上下文输入模式,结果一致:将 Character Arc 信息直接注入上下文的策略在所有模型上均排名第一,优于纯检索增强、全章文本注入等方案。外推场景(检索无从帮忙)上的提升幅度尤为显著。
进一步微调开源模型得到 ArcANE-8B / 32B,两个版本在外推场景上对比基础模型的角色弧优势进一步拉大。
方法亮点与社区关注:社区评论指出,非线性角色弧(如不可靠叙述者、角色倒退)的处理是明显的待攻克难点;有研究者追问了「消融角色阶段提示后纯时间线提示能买到多少」的边界问题——论文当前未提供这一消融,是后续值得填补的实验缺口。1
2. NF-CoT:用归一化流在连续空间里做推理
arXiv 预印本 · 2
思维链(CoT)提升推理性能的原因是什么?一种视角是:它为模型提供了「中间计算步骤」。但这些中间步骤被迫以离散 token 流的形式存在——每一步都要先 verbalize 成文字,模型才能继续,即便底层表征更新在语义上只是局部的、不确定的。
NF-CoT 用归一化流(Normalizing Flows)把这一过程移入连续潜空间:在 LLM 主干内部嵌入 TARFlow 式归一化流,由 NF head 负责生成压缩后的连续「思维 token」,文字 token 仍由标准 LM head 生成,两种 token 共享同一因果解码流。
这一设计保留了标准 CoT 的核心优势:
- 可逐步采样:仍支持自左向右的概率解码
- KV 缓存兼容:不破坏原有加速机制
- 精确似然估计:对连续思维 token 可以计算精确对数似然,支持直接 policy-gradient 优化
- 参数效率:无需为连续推理单独引入独立模型
代码生成 benchmark 上,NF-CoT 相比显式 CoT 和已有隐式推理基线均有提升,且中间推理开销显著降低。2
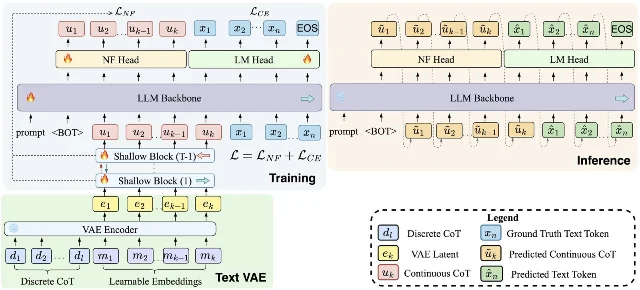
方法的潜在意义:如果连续思维 token 的信息密度高于同等数量的离散 token,意味着推理效率存在提升空间,但前提是连续空间内的「推理路径」对模型行为仍然是可控、可解释的——这一点目前尚无直接实验支持。
3. The Shape of Addition:LLM 算术错误的几何机制
arXiv 预印本 · 南京大学 · 3
LLM 在基础算术上的脆弱性是一个公认现象,但其内部机制始终模糊。南京大学团队通过分析多操作数加法过程中的残差流几何,给出了一个可量化的解释框架。
核心发现是 IRST(Iso-Raw-Sum Trajectory):残差流中存在一种几何结构,表征由语义数字锚定,并由连续的进位纤维(carry fiber)调制。沿这条轨迹,不同「原始和」相同的表征聚集在同一流形上,由进位状态进一步分层。
由此,论文提出 Noisy Quantization Model:算术错误本质上是「几何滑移」(Geometric Slippage)——内部神经噪声将连续的潜在进位值推过了量化阈值,导致最终 token 输出产生偏差,常见表现是相差 1 的错误(±1 error)。3
这一框架还解释了探针多功能性(Probe Versatility):同一个激活向量中可以同时编码「正确答案」和「幻觉答案」两条潜在信号,轻量探针之所以能从中分离出正确信号,正是因为它们在 IRST 几何上对应不同的分层。

实用验证:论文基于几何一致性检验,在推理时检测并纠正量化失败,有效降低了算术错误率。代码已开放(https://github.com/RL-MIND/Shape-of-Addition)。
方法价值:从机制可解释性角度来看,IRST 是「LLM 不是不会算,只是噪声偶尔让它跨了错误的量化边界」这一直觉的形式化——它的意义不仅在于算术修复,更在于为类似的「LLM 在正确内部表征下仍然输出错误」的现象提供了通用的几何分析入口。
4. Benchmark Agent:把 Benchmark 构建本身自动化
arXiv 预印本 · 4
Benchmark 的可持续性是一个被长期低估的问题:手工构建耗时耗力、难以复用,加之模型能力提升速度远超标注,新 benchmark 往往很快饱和——发布后不久顶尖模型就已接近天花板,区分度迅速丧失。
Benchmark Agent 针对这一结构性问题提出了全自动化解决方案:一个 Agentic 系统,接受用户查询后自行完成子任务设计、数据标注和质量控制的完整流程,输出可用的 benchmark 数据集。4
论文用该系统生成了 15 个覆盖不同场景的代表性 benchmark,包括文本理解、多模态理解和领域特定推理。评估引入了人工评估、LLM-as-a-judge 和一致性检验三套手段,结论是自动生成的样本在质量上达到可用标准,且人工参与极少。
关键实验发现:持续评测结果表明,当前模型在特定领域推理任务上仍存在明显短板,这是静态 benchmark 难以捕捉到的动态信号。
代码与演示页面:benchmarkagent.github.io

5. ADR:原子分解与重组,解决代码 RLVR 的数据瓶颈
arXiv 预印本 · 中科院信息工程研究所 (ICIP) · 5
代码强化学习(Code RLVR)近来被确立为提升 LLM 编程能力的核心范式,但它面临一个几乎被忽视的可扩展性障碍:训练所需的「可验证代码任务」严重稀缺。现有数据合成方案依赖启发式种子扩展,生成的任务在难度和新颖度上很快撞到天花板,模型接触这些数据后提升幅度递减。
ADR(Atomic Decomposition and Recombination)从任务结构入手:将已有代码任务分解到原子操作层面,再以受控方式重新组合,生成兼具新颖性和挑战性的新任务,同时保持可验证性(存在确定性测试用例)。5
在对比实验中,ADR 在以下四个维度上均优于既有基线:
- 原创性:生成任务与种子任务的语义距离
- 难度:模型通过率(越低表示越难)
- 多样性:任务分布的覆盖广度
- 测试质量:验证用例的覆盖率与准确性
下游评测跨越算法编程、工具调用和数据科学三个领域,ADR 在 RLVR 训练后的提升幅度一致高于对照组。
更大的意义:如果 RLVR 的效果瓶颈主要来自可验证任务稀缺,而 ADR 能无限量地生成可验证新任务,那么代码 LLM 的训练规模上限将由算力而非数据决定——这对 Code LLM 的扩展路线图是一个不小的结构性改变。代码已开放(https://github.com/icip-cas/ADR)。5
このコンテンツについて、さらに観点や背景を補足しましょう。