OpenAI Agents SDK #11:多模型调度背后,你不知道的优先级覆盖链
从「给 Agent 设置了 model 参数却被静默覆盖」这个高频陷阱切入,系统拆解 OpenAI Agents SDK 的三层模型优先级覆盖链(OPENAI_DEFAULT_MODEL → Agent.model → RunConfig.model);完整讲解 LitellmModel 接入 Anthropic/Gemini/Ollama 的三种写法及版本注意事项;对比 OpenAIChatCompletionsModel 与 LitellmModel 的适用边界;深入 ModelSettings.resolve() 的字段覆盖与字典合并机制;结尾给出 A/B 测试模型、Tracing 配置、国内模型选型等四个实战场景,以及 3 条可落地建议。
リサーチノート
你以为给 Agent 设置了
model="gpt-4o",它就会用 gpt-4o。不一定。
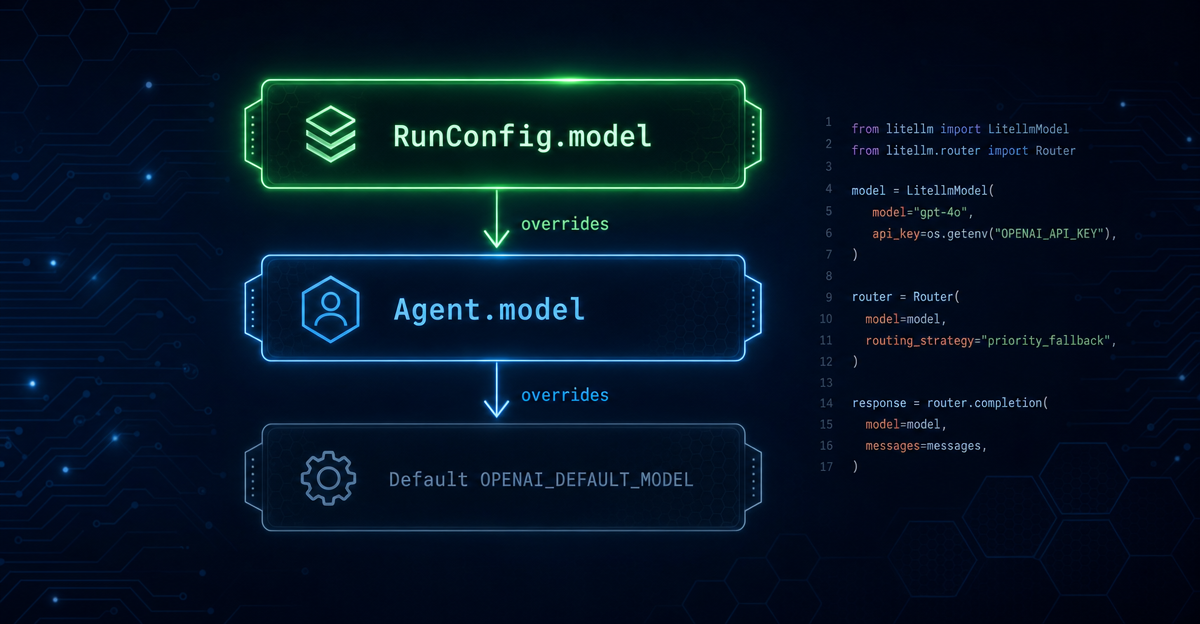
RunConfig 里如果有另一个
model 值,你 Agent 上写的那行配置会被完全覆盖。静默覆盖,没有报错,没有警告,Agent 就这么换了个脑子跑完。这不是 bug。这是 SDK 的三层优先级覆盖设计,理解它,你才能真正控制多 Agent 系统里每个节点用什么模型1。
三层覆盖链,从底到顶读一遍
SDK 的模型选择逻辑是一条单向覆盖链,层级越高优先级越高1:
环境变量 OPENAI_DEFAULT_MODEL ←── 全局默认(最低优先级)
↑ 被覆盖
RunConfig.model ←── 单次运行级别
↑ 被覆盖
Agent.model ←── 单个 Agent 级别(最高优先级)这里有个反直觉的地方:Agent.model 优先级最高,但 RunConfig.model 会覆盖它。
等等,这不矛盾了吗?
官方文档的描述是这样的:RunConfig.model 会覆盖「所有 Agent 自身设置的模型」2。也就是说,RunConfig 是一个「强制覆盖」开关:你一旦在 RunConfig 里设了 model,整个运行里所有 Agent 的 model 设置都会被忽略。
实际使用时这两种情境要分清楚:
情境 A:不同 Agent 用不同模型(A/B 实验、成本优化)
→ 只在各 Agent 上设
model,RunConfig 不设 model
→ Agent.model 生效,每个 Agent 各走各的情境 B:整个 pipeline 临时换模型(测试新版本、降级 fallback)
→ 在 RunConfig 里设
model,统一覆盖
→ 所有 Agent 都换,一行搞定from agents import Agent, Runner, RunConfig
# 情境 A:不同 Agent 各自的模型
analyst = Agent(
name="数据分析师",
model="gpt-4o", # 复杂推理用强模型
instructions="分析数据,给出判断",
)
summarizer = Agent(
name="摘要助手",
model="gpt-4o-mini", # 简单总结用轻量模型,省钱
instructions="把分析结果整理成一段话",
)
# 两个 Agent 会分别使用各自配置的模型
result = await Runner.run(analyst, "分析Q1销售数据")# 情境 B:RunConfig 强制覆盖,整个 pipeline 用同一个模型
# 无论 analyst 和 summarizer 各自配了什么,都会被替换
result = await Runner.run(
analyst,
"分析Q1销售数据",
run_config=RunConfig(model="gpt-4o-mini"), # 临时降级测试
)
接入 Anthropic、Gemini、Ollama——三种方式,按需选
SDK 支持非 OpenAI 模型,官方给了三个入口,适用场景各不同1:
方式一:set_default_openai_client(全局替换 OpenAI 客户端)
适合:整个项目都用同一个 OpenAI 兼容的提供商(比如 Azure、DeepSeek、Qwen)。
import asyncio
from openai import AsyncOpenAI
from agents import Agent, Runner, set_default_openai_client, set_default_openai_api
# 替换全局 OpenAI 客户端为 DeepSeek 兼容端点
custom_client = AsyncOpenAI(
base_url="https://api.deepseek.com/v1",
api_key="your-deepseek-api-key",
)
# 告诉 SDK 用这个客户端,不要再去找 OPENAI_API_KEY
set_default_openai_client(custom_client)
set_default_openai_api("chat_completions") # 非 OpenAI 提供商通常只支持 Chat Completions
agent = Agent(
name="DeepSeek Agent",
model="deepseek-chat", # 直接写提供商的模型名
instructions="你是一个有帮助的助手",
)
async def main():
result = await Runner.run(agent, "你好,介绍一下自己")
print(result.final_output)
asyncio.run(main())方式二:ModelProvider(单次运行级别)
适合:同一个项目里有些 Agent 用 OpenAI,有些要临时换供应商。
from openai import AsyncOpenAI
from agents import Agent, Runner, RunConfig, OpenAIChatCompletionsModel, ModelProvider
class MyCustomProvider(ModelProvider):
"""自定义 ModelProvider,按模型名路由到不同提供商"""
def get_model(self, model_name: str | None):
if model_name and model_name.startswith("claude"):
# Anthropic 走 OpenAI 兼容端点(需要 Anthropic 支持)
client = AsyncOpenAI(
base_url="https://api.anthropic.com/v1",
api_key="your-anthropic-key",
)
return OpenAIChatCompletionsModel(model=model_name, openai_client=client)
# 其他模型走默认 OpenAI
return None # 返回 None 时 SDK 使用默认 MultiProvider
agent = Agent(
name="Claude Agent",
model="claude-opus-4-5",
instructions="你是一个有帮助的助手",
)
result = await Runner.run(
agent,
"解释量子纠缠",
run_config=RunConfig(model_provider=MyCustomProvider()),
)方式三:LitellmModel(单个 Agent 级别,覆盖 100+ 供应商)
适合:快速接入任意模型做实验,项目里有个别 Agent 需要特殊模型。
这是最灵活的方式,但也是测试版,使用前要先安装额外依赖1:
pip install "openai-agents[litellm]"from agents import Agent, Runner
from agents.extensions.models.litellm_model import LitellmModel
# 写法一:直接用 litellm/ 前缀格式的字符串
agent_anthropic = Agent(
name="Anthropic Agent",
model="litellm/anthropic/claude-opus-4-5", # litellm 格式:provider/model
instructions="用中文回答问题",
)
# 写法二:实例化 LitellmModel(更清晰,可传额外参数)
agent_gemini = Agent(
name="Gemini Agent",
model=LitellmModel(
model="gemini/gemini-2.0-flash",
api_key="your-google-api-key", # 也可以靠环境变量
),
instructions="用中文回答问题",
)
# 写法三:接入本地 Ollama(无需 API Key)
agent_local = Agent(
name="本地 Llama Agent",
model=LitellmModel(
model="ollama/llama3.2",
api_base="http://localhost:11434", # Ollama 默认端口
),
instructions="你是本地运行的助手",
)
async def main():
# 三个 Agent 各跑各的
r1 = await Runner.run(agent_anthropic, "什么是 Transformer?")
r2 = await Runner.run(agent_gemini, "什么是 Transformer?")
r3 = await Runner.run(agent_local, "什么是 Transformer?")
print("Claude 说:", r1.final_output)
print("Gemini 说:", r2.final_output)
print("Llama 说:", r3.final_output)一个版本提示:v0.14.2 修复了 LiteLLM 的extra_body转发问题,如果你在 Agents SDK 中使用 LiteLLM 且发现自定义请求体参数没生效,请先升级到 v0.14.2+4。
OpenAIChatCompletionsModel vs LitellmModel:两种路线,不是竞争
很多人第一次看到这两个类会犯迷糊。说清楚:
OpenAIChatCompletionsModel:SDK 内置实现,直接调用 OpenAI Chat Completions API 协议。任何支持 OpenAI API 格式的提供商(Azure、DeepSeek、Qwen、国内大部分厂商)都可以用,只需要传一个自定义 AsyncOpenAI 客户端5。LitellmModel:借助 LiteLLM 这个第三方适配层,统一封装了 100+ 提供商的 API 差异。好处是不用自己处理各家 API 格式的差异;代价是多一层依赖、处于测试阶段、偶尔有兼容性 bug1。官方的建议很直接:优先用
OpenAIChatCompletionsModel,因为国内和海外大部分主流提供商都支持 OpenAI 兼容格式——用标准路径更稳定。只有内置方式真的搞不定时,再考虑 LiteLLM。# 推荐路径:OpenAI 兼容格式 → OpenAIChatCompletionsModel
from openai import AsyncOpenAI
from agents import Agent
from agents.models.openai_chatcompletions import OpenAIChatCompletionsModel
qwen_client = AsyncOpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="your-dashscope-key",
)
agent = Agent(
name="通义千问 Agent",
model=OpenAIChatCompletionsModel(
model="qwen-max",
openai_client=qwen_client,
),
instructions="你是通义千问助手",
)ModelSettings:参数覆盖也有层级
模型参数(temperature、top_p 这些)的覆盖逻辑和模型本身一样,也是多层级的6。
ModelSettings.resolve() 方法负责合并:把 override 里所有非 None 的字段覆盖到当前实例,返回新实例。这意味着——你在 RunConfig 里设的 model_settings 只会覆盖你明确传了值的字段,没传的字段保留 Agent 自己的配置2。from agents import Agent, Runner, RunConfig
from agents.model_settings import ModelSettings
# Agent 自己的模型参数
creative_agent = Agent(
name="创意写作",
model="gpt-4o",
model_settings=ModelSettings(
temperature=0.9, # 高温,更有创意
max_tokens=2000,
top_p=0.95,
),
instructions="你是一位富有创意的作家",
)
# RunConfig 的 model_settings 只覆盖 temperature
# max_tokens 和 top_p 仍然用 Agent 自己的值
result = await Runner.run(
creative_agent,
"写一首关于代码的诗",
run_config=RunConfig(
model_settings=ModelSettings(
temperature=0.3, # 覆盖为低温,更确定
# max_tokens 没传 → 保留 Agent 的 2000
# top_p 没传 → 保留 Agent 的 0.95
)
),
)值得单独说一下
extra_args:它的合并策略和其他字段不同,是字典合并,而不是直接覆盖6。Agent 的 extra_args 和 RunConfig 的 extra_args 会被合并,键冲突时 RunConfig 的值优先。# Agent 设了 extra_args
agent = Agent(
model_settings=ModelSettings(
extra_args={"response_format": "json_object", "seed": 42}
)
)
# RunConfig 覆盖其中一个键,另一个保留
run_config = RunConfig(
model_settings=ModelSettings(
extra_args={"seed": 99} # 只改 seed,response_format 保留
)
)
# 最终生效:{"response_format": "json_object", "seed": 99}ModelRefusalError 是 v0.15.0 新加的:当模型拒绝请求时,不再返回空文本,而是直接抛出异常4。这对调试模型参数很有用:以前 temperature 设得过低模型可能悄悄不回应,现在至少会有明确报错。多模型实战建议
场景一:不同 Agent 用不同模型,降成本
三个 Agent 的 pipeline:分类 → 深度分析 → 摘要。分类和摘要任务简单,用
gpt-4o-mini;深度分析任务复杂,用 gpt-4o。只需要在 Agent 定义时各自指定 model,RunConfig 不设 model,就能自动路由。场景二:A/B 测试两个模型版本
不用改 Agent 定义,只改 RunConfig:
import random
from agents import Agent, Runner, RunConfig
agent = Agent(name="客服机器人", instructions="解答用户问题")
async def run_with_ab_test(user_input: str):
# 50% 流量用 gpt-4o,50% 用 gpt-4o-mini
model = "gpt-4o" if random.random() > 0.5 else "gpt-4o-mini"
result = await Runner.run(
agent,
user_input,
run_config=RunConfig(model=model),
)
# 记录 model 到日志,用于后续对比
print(f"[{model}] {result.final_output}")
return result场景三:非 OpenAI 模型的 Tracing 配置
接入 Anthropic 或 Gemini 后,链路追踪默认还是推到 OpenAI——你需要专门配一下8:
from agents import set_tracing_export_api_key
# 全局配置:即使用非 OpenAI 模型,Trace 数据仍发到 OpenAI Tracing
set_tracing_export_api_key("sk-your-openai-key-for-tracing")
# 或者单次运行配置
run_config = RunConfig(
model=LitellmModel(model="claude-opus-4-5"),
tracing={"api_key": "sk-your-openai-key-for-tracing"},
)场景四:接入国内模型的选型原则
官方文档的建议是:优先选择支持 JSON Schema 输出的提供商1。SDK 的工具调用和结构化输出依赖 JSON Schema,如果提供商不支持,工具执行会报错或行为不稳定。国内的 Qwen(通义千问)、DeepSeek 都支持 OpenAI 兼容格式和 JSON Schema,是接入
OpenAIChatCompletionsModel 的优质选择。明天就能用上的 3 条建议
1. 审查你现有的 RunConfig,看有没有意外的模型覆盖
如果你的多 Agent pipeline 里有个别 Agent 表现和预期不一样,先检查 RunConfig.model 是不是设了值。一行
print(run_config.model) 就能排查这个问题。2. LiteLLM 接入先装对版本
接入
LitellmModel 前,先 pip install "openai-agents[litellm]",不然会静默 import 失败。用完了别忘了确认 SDK 版本 ≥ 0.14.2,这个版本修了 extra_body 转发的 bug4。3. 用
ModelSettings 做精细参数分层,不要全靠全局配置把生产环境的「稳定低温」和创意场景的「高温」分别写到对应 Agent 的
model_settings 里,RunConfig 只做全局兜底。这样不同任务的参数各司其职,改一个不影响另一个。Models 模块到这里就讲完了。三层覆盖链、三种接入路径、参数层级合并,这些机制组合起来,让你能在同一个 pipeline 里同时调度 OpenAI、Anthropic、Gemini、本地 Ollama,各跑各的,互不干扰。
整个 OpenAI Agents SDK 系列已经走过了 Agent、Runner、Tools、Memory、Sandbox、Handoffs、Tracing、Guardrails、Streaming、Context,以及今天的 Models,共 11 篇覆盖了 SDK 的核心技术模块。如果你一路跟下来,相信对这个框架的全貌已经有了比较完整的认识。后续还有更多进阶话题可以展开,比如 Realtime Agents、MCP Server 工具调用,或者结合真实业务场景拆解多 Agent 架构设计,有机会再聊。
官方示例目录 examples/model_providers 包含了
OpenAIChatCompletionsModel 和 LitellmModel 的完整参考代码,是本篇所有示例最好的延伸阅读5。封面图:图片由 AI 生成,主题为 OpenAI Agents SDK Models 模块优先级覆盖链可视化
参考来源
- 1OpenAI Agents Python SDK - Models
- 2OpenAI Agents Python SDK - Running Agents
- 3OpenAI Agents Python SDK - Agent Core
- 4OpenAI Agents Python SDK - Releases
- 5GitHub - openai-agents-python examples
- 6OpenAI Agents Python SDK - ModelSettings API
- 7GitHub - openai/openai-agents-python
- 8OpenAI Agents Python SDK - Tracing
このコンテンツについて、さらに観点や背景を補足しましょう。