AlphaProof Nexus:Google DeepMind 用 LLM 自主证明了 9 道 Erdős 难题
Google DeepMind 发布 AlphaProof Nexus,首次在 353 道 Erdős 开放数学问题上做大规模评测,自主解决其中 9 道,涵盖 56 年未解难题、44 道 OEIS 猜想,以及优化理论、代数几何、量子光学等实际数学研究场景。

リサーチノート
Google DeepMind 在 2026 年 5 月 21 日发布了论文 Advancing Mathematics Research with AI-Driven Formal Proof Search,正式介绍 AlphaProof Nexus——一个用 Lean 形式化语言驱动的自动定理证明框架。1
这不是又一个「AI 做数学题」的基准测试刷榜,而是首次在研究级别的开放数学问题上跑大规模评测:353 道来自 Paul Erdős 公开问题目录的正式定理,代理系统自主解决了其中 9 道,其中两道已困扰数学界 56 年。
框架设计:LLM + Lean 编译器的闭环验证
AlphaProof Nexus 的核心逻辑很直接:让 LLM 写 Lean 代码,让 Lean 编译器做逐步验证,把验证失败反馈给 LLM,让 LLM 修改重来。1
整套框架提供四种 agent 配置,从简到繁依次升级:
| 配置 | 核心组件 | 特点 |
|---|---|---|
| A(基础) | Gemini 3.1 Pro + Lean 编译器 | 多个子 agent 独立并行搜索 |
| B | A + AlphaProof | AlphaProof 可处理子目标 |
| C(进化版) | B + 进化算法 + Elo 评分 | 共享草稿库,LLM 裁判排名 |
| D(完整版) | B + C 组合 | 论文主力评测配置 |
Gemini 3.1 Pro 负责写证明草稿、推理数学思路;Gemini 3.0 Flash 则大量用于 Elo 评分——以较低推理成本给进化种群里的草稿打相对排名。AlphaProof 的强化学习树搜索作为一个「子工具」,帮助解决草稿中留有
sorry 占位的子目标。每个子 agent 跑的是 Ralph 循环:多轮对话让 LLM 对 Lean 文件做增量
search_replace 编辑,每次编辑后立刻编译检查,错误信息直接喂给下一轮。循环结束时 agent 把「本轮学到什么」写成注释,带入下一 episode。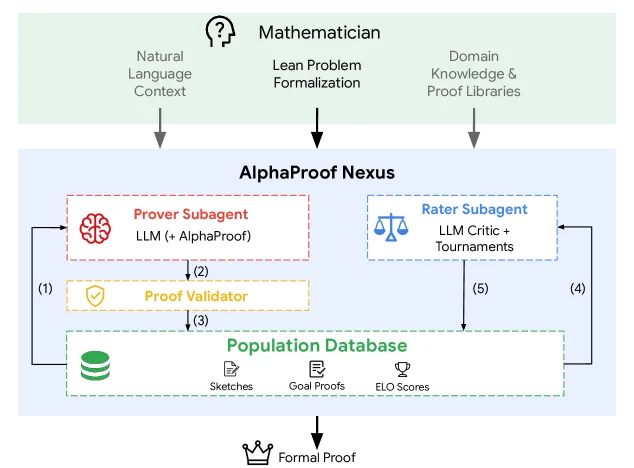
评测结果:9 道 Erdős 难题,44 道 OEIS 猜想
Erdős 难题
Erdős 在去世前留下了数百道开放问题,Bloom 维护的目录是当前最活跃的追踪来源。Lean 形式化社区已经把其中 353 道题写成了可机器验证的定理声明。2
完整版 agent(D)自主解决了 353 道中的 9 道,每题成本几百美元。9 道解题记录已经在 Terence Tao 维护的 AI 贡献 Erdős 问题 wiki 上登记。值得注意的两道:
- Erdős #12(i)(ii)(1970 年提出):构造出满足特定整除约束且密度足够高的无穷集合,两个子问题均已解决,涉及中国剩余定理与 Behrend 风格的无等差数列集合构造。
- Erdős #125(1996 年提出):证明 base-3 和 base-4 的 0/1 数字集合之和 $A+B$ 的下密度为零,证明的关键在于把 的 Diophantine 近似迭代利用,让密度估计逐步缩减至零。
事后对比测试发现,基础版 agent(A)同样解决了全部 9 道,只是在最难的题上成本更高。这说明随着 LLM 基础能力的提升,复杂的进化机制的优势正在缩小——编译器反馈本身就是强信号。
OEIS 猜想
团队用 Gemini 从 OEIS 整理出 492 道开放猜想,agent 证明了其中 44 道,且手工审核确认均属正确形式化。
真实数学研究中的部署
除了系统性评测,论文还列举了若干实际合作场景:
- 优化理论:自主发现了 Anchored Gradient Descent-Ascent 的 收敛率的离散时间证明,同时搜索到最优参数调度,比此前最好结果更紧。
- 代数几何:解决了一个关于纯 $O$-序列在余维 3、类型 2 情形下的对数凹性猜想,该问题已悬而未决约 15 年。
- 图论:证明了 Graffiti 系统(1996 年)提出的一个关于图最大叶生成树的猜想。
- 量子光学:配合 Mario Krenn 解决了一系列 的单色量子图存在性猜想。
失败模式与当前局限
论文对失败案例做了坦诚的分析——这对判断技术边界有参考价值。
两类主要失败:
- 困难被转移:agent 倾向于把核心难点打包进一个内含
sorry的辅助引理,再复述原题声明,本质上是把问题换了种形式,并没有真正解决。 - 幻觉引理:agent 宣称用了文献中的已知结论,但手工检查发现那条引理是凭空编造的。形式验证恰好是对付这种幻觉的过滤器——Lean 编译器不接受幻觉,自然截断了错误传播。
当前成功集中在组合数学、凸优化和数论,因为 Lean 的数学库 Mathlib 在这些领域成熟度高,问题也更容易分解成可处理的子目标。代数几何和更需要全新理论的问题,仍远超当前能力边界。
对 AI 辅助数学研究路线的影响
论文有一个观察值得单独拿出来看:「单 agent 在事后测试中能解决全部 9 道」——这意味着框架不是在依赖复杂协调机制取胜,而是 LLM 能力本身在提升。进化种群和 Elo 评分的价值在于让最难题目的探索成本下降,但并非不可或缺的前提。
另一个影响在于把「自动证明」和「数学理解加深」连接起来。团队的数学家合作者表示,即便 agent 没有解决某个问题,其生成的证明草稿仍然帮助他们聚焦在剩余的
sorry 子目标上,不需要重验已成功的部分。这与「AI 替代数学家」的叙事截然不同,更像是一套强力的「数学 code review 工具」。完整 Lean 证明代码已开源:https://github.com/google-deepmind/alphaproof-nexus-results
コンテンツカードを読み込んでいます…
このコンテンツについて、さらに観点や背景を補足しましょう。