
June 2026 LLM Hallucination-Mitigation Digest
A curated monthly digest of 25 hallucination-mitigation papers and 6 engineering tools from May 15 – June 1, 2026 — covering ICML 2026 highlights, a multimodal surge (11 papers in 17 days), domain-specific benchmarks, and a synthesis of training-free detection as the emerging dominant paradigm.
Coverage window: May 15 – June 1, 2026 (17 days) · 25 papers · 6 engineering tools · 1 ICML 2026 Oral
Window snapshot
This shorter-than-usual window yielded a higher-than-expected paper count, driven by two forces: an unusually dense multimodal sub-area (11 papers versus the 0–3 typical for a 17-day window) and a concentrated ICML 2026 showing (6 accepted papers appearing on ArXiv this month, including one Oral). The practical effect is that some sub-areas require triage rather than exhaustive coverage.
Training-free inference-time detection has become the dominant paradigm. Across both text-only and multimodal papers, the recurring design is plug-and-play: no retraining, no auxiliary models, intervention applied at a single layer or decoding step. FEPoID (ICML 2026) makes layer selection automatic; BRACS computes the correction in closed form; AOD requires only a second forward pass. The shift from fine-tuning-heavy methods toward lighter interventions, visible in last month's PTI and CAST, has accelerated.
ICML 2026 is the primary destination for high-quality hallucination work in mid-2026. Seven of the accessible new papers have ICML 2026 acceptances. ACL 2026 camera-ready versions have not yet appeared; expect that wave in July–August.
Domain-specific hallucination benchmarks are multiplying. K-FinHallu targets Korean multi-turn financial RAG; Trajel targets industrial multi-agent trajectory auditing; CiteCheck targets physics citation fabrication; the bug-report study targets SE artifacts. Each introduces a custom taxonomy that does not reduce to TruthfulQA or HaluEval.
Hidden-state probing and layer selection
FEPoID + FST: automatic optimal layer selection for probing-based detectors
ArXiv 2605.26366 · Venue ICML 2026 Poster (Jul 7, 2026) · Status Accepted
Authors Xinpeng Wang, William Cao, Andrew Gordon Wilson, Zhe Zeng · Institution New York University
Methodology Training-free detection via Intrinsic Dimension-based layer criterion + rule-based truncation
Code https://github.com/DesoloYw/Automatic-Layer-Selection-for-Hallucination-Detection
Probing-based hallucination detection extracts intermediate hidden states and trains a lightweight classifier on them. The key unresolved question has been which layer to probe — prior work used the last layer by default, or ran validation sweeps across all layers to find the best one. Both are unsatisfying: the last layer is rarely the most informative, and validation-based selection requires labeled held-out data for every new model-dataset pair.
FEPoID (First Effective Peak of Intrinsic Dimension) proposes a data-free criterion. Intrinsic Dimension (ID) — a measure of the effective dimensionality of a representation — varies across layers in a characteristic pattern; FEPoID identifies the first peak of this curve as a proxy for where the model's representation is most factually discriminative. 1 Evaluated against 7 competing layer-selection criteria (RankMe, Curvature, Validation Loss, RGN, SNR, ID, and last-layer) across diverse architectures, scales, and tasks, FEPoID consistently selects optimal or near-optimal layers. On LLaMA-3.1-8B-Instruct, average AUROC reaches 0.7253 (versus 0.5299–0.7250 for baselines); on Mistral-7B-Instruct-v0.3, it reaches 0.8531 (versus 0.5579–0.8472). 1
The paper also introduces First-Sentence Truncation (FST): rather than extracting representations at the last generated token, FST extracts at the end of the first generated sentence. The improvement holds independently of layer selection method, suggesting that last-token representations accumulate generation noise unrelated to factuality. Combining FEPoID and FST yields the strongest results across all configurations evaluated. 1
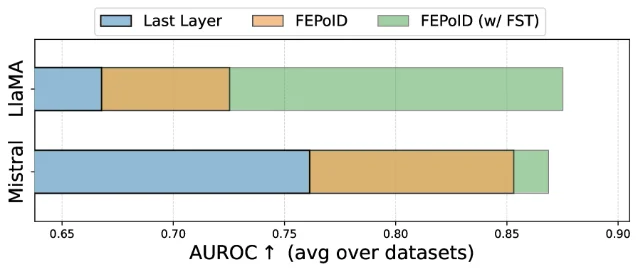
Comparison with prior work: The 7-baseline evaluation is unusually comprehensive for a layer-selection study. The practical payoff is that FEPoID eliminates the need for labeled validation sets when deploying probing-based detectors on a new model-dataset combination — a significant friction reduction for practitioners.
Evaluation CoQA, SQuAD, HotpotQA, TriviaQA, PsiloQA, HaluEval, CNN/Daily Mail.
MultiHaluDet: multilingual hidden-state probing with cross-lingual transfer
ArXiv 2605.24919 · Venue MeLLM Workshop @ ACL 2026 · Status Accepted
Authors Riasad Alvi (UIU), Nurul Labib Sayeedi (BRAC University), Md. Faiyaz Abdullah Sayeedi (UIU) · Institutions United International University; BRAC University, Bangladesh
Methodology Detection via four-stage stacking framework over frozen LLM hidden states
Code https://github.com/alvi-uiu/MultiHaluDet
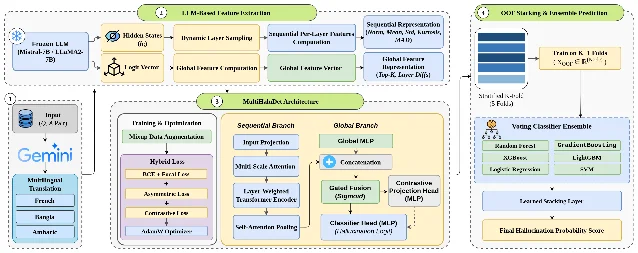
MultiHaluDet constructs a four-stage pipeline over full hidden-state trajectories of frozen LLMs: (1) dynamic layer sampling to extract multi-scale representations, (2) multi-scale attention and self-attention pooling to aggregate across layers, (3) out-of-fold stacking to generate deep meta-features, and (4) a learned ensemble meta-learner that combines the stacked features. No language-specific fine-tuning is required — the framework operates on the frozen model's internal representations and relies on cross-lingual generalization of those representations. 2
The headline result is 98.55% AUROC on HaluEval and TriviaQA using Mistral-7B and LLaMA2-7B. 2 More substantively, the paper evaluates on French (high-resource), Bangla (medium-resource), and Amharic (low-resource) — a typologically diverse range — and reports robust transfer across all three without language-specific retraining.
Comparison with prior work: MultiHaluDet outperforms P(True), AvgProb, AvgEnt, EUBHD, Unigram/NLI, INSIDE, SAPLMA, MIND, Probe@Exact, and HD-NDEs. The jump to 98.55% AUROC is notably higher than FEPoID's range on similar tasks; the gap likely reflects the more complex stacking architecture and the specific Mistral-7B/LLaMA2-7B setup. Direct comparison between the two is confounded by different benchmark sets.
Evaluation HaluEval, TriviaQA (English + French, Bangla, Amharic translations).
Uncertainty quantification: a systematic critique
Evaluating 46 uncertainty estimators against hallucination targets
ArXiv 2605.27016 · Venue Preprint (35 pages, 7 figures, 9 tables) · Status Preprint
Authors Yedidia Agnimo (Ekimetrics / Inria Grenoble), Anna Korba (CREST/ENSAE, IP Paris), Annabelle Blangero, Nicolas Chesneau (Ekimetrics), Karteek Alahari (Inria Grenoble)
Methodology Systematic empirical evaluation study
Code Not provided independently; uses LM-Polygraph for uncertainty computation
The premise of uncertainty-based hallucination detection — that high-uncertainty outputs tend to be hallucinated — holds up inconsistently across hallucination types and models. This paper provides the most rigorous audit to date: 46 uncertainty estimators evaluated against explicit hallucination targets rather than generic error rates, across intrinsic (context-faithfulness, RAGTruth) and extrinsic (pretraining-knowledge, HalluLens: PreciseWikiQA, LongWiki, NonExistentRefusal) hallucination settings. 4
Two findings are directly actionable. First, estimator rankings are more stable across models within the same dataset than across datasets for the same model — meaning that selecting an estimator should be driven by the deployment's hallucination type, not by which model is in use. Second, no single estimator is consistently best across all four settings; on short-form QA (PreciseWikiQA) most estimators discriminate well, but on long-form generation (LongWiki) AUROC values cluster in a moderate range with small inter-estimator gaps. 4
The practical recommendation the authors reach is dataset-specific validation rather than relying on any published "best" estimator. This is an uncomfortable conclusion for practitioners deploying general-purpose uncertainty-based guards, but it is better-supported empirically than most claims in the detection literature.
Comparison with prior work: Prior uncertainty-hallucination work typically evaluates 5–10 estimators on 1–2 benchmarks. The 46-estimator × 4-dataset grid is substantially broader. The intrinsic/extrinsic split — distinguishing between hallucinations traceable to provided context versus hallucinations of world knowledge — is also a methodological refinement not present in most prior evaluations.
Evaluation RAGTruth (intrinsic), HalluLens suite: PreciseWikiQA, LongWiki, NonExistentRefusal (extrinsic).
Domain-specific benchmarks and trajectory-level auditing
Trajel: trajectory-level hallucination auditing in industrial multi-agent workflows
ArXiv 2605.24219 · Venue NeurIPS 2026 Datasets and Benchmarks Track (submitted) · Status Under review
Authors Harshada Badave, Santosh Borse, Shuxin Lin, Dhaval Patel (IBM Research); Andrea Gomez, Harshitha Narahari, Sara Carter, Vishwa Bhatt, Aishani Rachakonda (Columbia University)
Methodology Evaluation benchmark + detection paradigms (subtask-level, trajectory-level NLI, long-context)
Code/Data Trajel dataset described in paper; availability pending
Existing hallucination work focuses on individual LLM responses. In multi-agent industrial settings, the unit of failure is a full Thought-Action-Observation trajectory — a sequence where errors compound across steps and often do not manifest as individually obvious single-step failures. Trajel is the first benchmark combining industrial trajectories with a trajectory-level hallucination taxonomy. 5
The taxonomy defines five structural predicate types: factual, referential, logical, procedural, and scope-based. Evaluated over 225 trajectories generated by 6 models on 42 AssetOpsBench industrial tasks, human annotators found a 68.3% hallucination rate, with 48.7% of hallucinated trajectories exhibiting multiple simultaneous types and procedural hallucinations accounting for 38.5% of all failures. 5
LLM-as-a-Judge F1 varies sharply across types: 0.784 for procedural, 0.719 for factual, 0.258 for logical, and 0.222 for referential — a 3.5× spread that makes LLM judging unreliable for the types that actually matter most for agentic reliability. The most informative single predictor is a lightweight clarity-and-justification signal: AUC 0.908 as a univariate predictor, substantially better than BERT (0.613), NLI (0.689), and Longformer (0.599) classifiers. 5
Comparison with prior work: No prior benchmark combines structured industrial trajectories with this taxonomic depth. The finding that a simple execution-quality signal outperforms supervised classifiers across all types is actionable for agentic system designers who cannot afford to run per-step NLI at production latency.
Evaluation Trajel (225 trajectories, 6 models, 42 tasks); BERT, NLI, Longformer classifiers; LLM-as-a-Judge (6 models).
CiteCheck: retrieval-grounded detection of citation hallucinations in physics literature
ArXiv 2605.27700 · Venue Preprint · Status Preprint
Authors Khashayar Khajavi, Shaghayegh Sadeghi, Rise Adhikari, Alexander Tessier
Methodology Detection via retrieval cascade + LLM verifier scoring
Code/Data Available upon request
CiteCheck addresses a targeted but high-consequence subtype: LLM-generated citations to non-existent scholarly works. The pipeline parses a raw citation string into structured metadata, runs a multi-source retrieval cascade (CrossRef, Semantic Scholar, OpenAlex, web search), and passes the string-candidate pair to an LLM verifier that scores agreement on a three-level scale (Exact / Minor / Major). 6
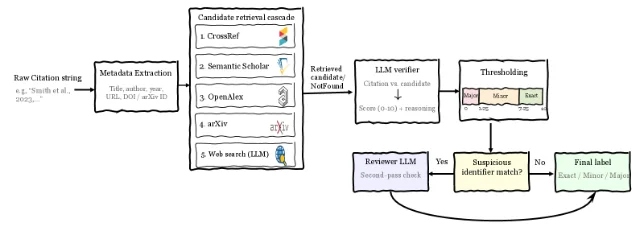
The benchmark: 982 citations from physics literature across 9 subdomains (astrophysics through soft matter), with controlled corruptions spanning minor metadata drift and major fabrications. CiteCheck achieves 88.7 macro-F1 and 88.9% accuracy, outperforming the strongest baseline (Claude Sonnet 4.6 + web search + few-shot) by 5.8 macro-F1 points. For major hallucinations — fully fabricated citations — detection F1 reaches 98.3. 6 Zero-shot CiteCheck surpasses few-shot LLM baselines, suggesting the pipeline's retrieval grounding does more work than the verifier's in-context demonstrations.
Comparison with prior work: Last month's Hallucinator tool (Apr 15 – May 15 window) addressed the same problem with an offline database approach; CiteCheck targets a different failure mode (LLM-generated citation fabrication versus human-authored citation errors) and uses live retrieval. The 98.3 F1 on major fabrications is the cleaner signal — minor metadata drift (wrong year, slightly wrong title) is harder and the accuracy at that granularity is not separately reported in the abstract.
Evaluation 982-citation custom physics benchmark (9 subdomains); GPT, Claude, Gemini baselines.
K-FinHallu: multi-turn RAG hallucination in Korean financial documents
ArXiv 2605.29523 · Venue Preprint · Status Preprint
Authors Eunbyeol Cho, Yunseung Lee, Mirae Kim, Jeewon Yang, Youngjun Kwak, Edward Choi · Institution KAIST (Korea Advanced Institute of Science and Technology)
Methodology Evaluation benchmark for hallucination detection in domain-specific multilingual RAG
Code/Data Not available
K-FinHallu is the first benchmark for hallucination detection in multi-turn Korean financial RAG. The construction uses authentic Korean financial documents with injected hallucinations under a hierarchical answerability taxonomy — a design that distinguishes between hallucinations that could be detected by consulting the context and hallucinations that require justified abstention (answering "this cannot be determined from the provided documents"). 8
The key finding is that justified abstention is the weakest axis across every model evaluated — both frontier LLMs and open-source models fail more often at recognizing when a question falls outside what the context can support. Fine-tuning an 8B model on the training split produces performance competitive with frontier models, confirming that domain-specific training data matters more than raw model scale for Korean financial RAG. 8
Comparison with prior work: The multi-turn structure and justified-abstention taxonomy distinguish K-FinHallu from prior financial NLP benchmarks and from general Korean QA datasets. The domain and language combination (Korean finance, multi-turn) is unexplored in prior hallucination work.
Evaluation K-FinHallu benchmark; frontier LLMs and fine-tuned 8B open-source models.
LLM-generated bug report summaries: section-aware hallucination detection
ArXiv 2605.24137 · Venue Preprint · Status Preprint
Authors Hinduja Nirujan, Shreyas Patil, Abdallah Ayoub, Ahmad Abdel Latif, Gouri Ginde
Methodology Detection across report structure (section-aware multi-label classification)
Code/Data Not available
An exploratory study on 80 LLM-generated bug report summaries from Mozilla open-source projects found that 47.9% contained missing information and 12.3% contained fabricated content — rates high enough to make unsupervised use of LLMs for bug-report summarization a reliability concern in software engineering workflows. 9
The paper's technical contribution is a section-aware detection model that jointly predicts hallucination presence, the affected section (Steps-to-Reproduce, Actual Behavior, Expected Behavior), and hallucination type. The best model achieves 0.89 report-level Macro-F1, 0.83 section-level Macro-F1, and 0.84 hallucination-type Macro-F1 across multiple pretrained language models. 9 Section-level analysis reveals that different structural fields in a bug report have distinct error patterns — fabrications concentrate in Steps-to-Reproduce while missing information concentrates in Expected Behavior.
Evaluation BugsRepo (Mozilla OSS projects); controlled synthetic hallucination injection; multiple pretrained LMs.
Multimodal and LVLM methods
Eleven papers appeared in this window targeting large vision-language models (LVLMs) and multimodal LLMs (MLLMs) — a volume more typical of a full 30-day cycle. Six are covered at full depth; five shorter entries follow.
AOD: adversarial orthogonal disentanglement
ArXiv 2605.25377 · Venue Preprint · Status Preprint
Authors Ruoxi Cheng (Fudan / Tencent), Haoxuan Ma (Nanjing University), Zhengfei Hai (Southeast University), Yiyan Huang (Great Bay University), Ranjie Duan (Tencent), Tianle Zhang (TeleAI), Xu Yang (Southeast University), Ziyi Ye (Fudan), Xingjun Ma (Fudan, corresponding)
Methodology Training-time disentanglement + training-free contrastive decoding at inference
Code https://github.com/Hunter-Wrynn/AOD
The operating hypothesis is that LVLM hidden states conflate a hallucination direction with semantic content. AOD (Adversarial Orthogonal Disentanglement) isolates this direction through a minimax adversarial objective: a classifier learns to concentrate hallucination signal in a unit vector, while a Gradient Reversal Layer (GRL) adversarially removes that signal from the residual representation. At inference time no retraining is needed — a dual-forward-pass contrastive decoding strategy subtracts the hallucination-amplified output from the standard output. 10
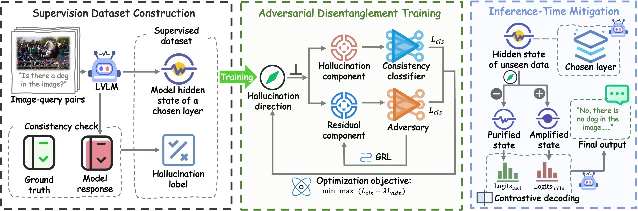
Benchmark improvements on LLaVA-1.5-7B: POPE accuracy +6.4 percentage points (84.5% → 90.9%), CHAIR −2.0 (15.3 → 13.3), AMBER +8.1 (78.6% → 86.7%), OCRBench-v2 +10.4 (16.8% → 27.2%), MMMU +3.8 (34.5% → 38.3%). On Qwen2.5-VL-7B: POPE +5.6 (89.0% → 94.6%), CHAIR −3.4 (8.4 → 5.0). On InternVL3-8B: POPE +7.3 (84.1% → 91.4%). 10 Transfer experiments across datasets support the authors' claim that AOD captures a universal hallucination direction rather than a dataset-specific artifact.
Comparison with prior work: VCD (Visual Contrastive Decoding), ASD, TruthPrInt, VASparse, and PruneHal are the baselines. AOD's dual-forward-pass structure is operationally similar to VCD, but the trained hallucination direction replaces VCD's heuristically degraded image input as the contrastive signal — a mechanistically principled substitution.
Evaluation POPE, CHAIR, AMBER, HallusionBench, OCRBench-v2, MMMU; LLaVA-1.5-7B, Qwen2.5-VL-7B, InternVL3-8B.
BRACS: barrier-regulated adaptive closed-form steering
ArXiv 2605.29881 · Venue Preprint · Status Preprint
Authors Soumyadeep Jana, Pulkit Mittal, Sanasam Ranbir Singh · Institution IIT Guwahati
Methodology Training-free inference-time steering using pre-softmax image-attention as a grounding barrier
Code Not available
BRACS addresses three limitations of prior training-free steering methods: (1) no explicit grounding objective, (2) unconditional application regardless of whether the current token actually needs correction, and (3) fixed correction strength. The paper's key empirical finding motivating the design: words in the least image-attended group of generated tokens are hallucinated approximately 28% of the time versus 9–12% in more-attended bins. 11
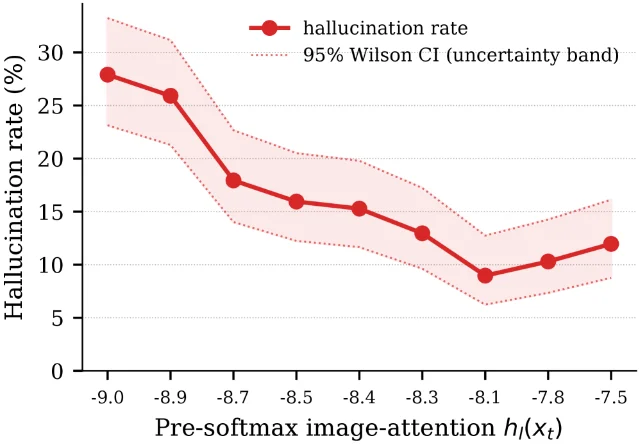
BRACS uses the model's own pre-softmax image-attention as a grounding barrier : when , a closed-form minimum-norm hidden-state correction is computed; no gradient computation or auxiliary network is required. Correction magnitude scales adaptively with the instantaneous violation. Results on LLaVA-1.5-7B under greedy decoding: CHAIRs 47.80 → 40.00 (−7.8), POPE accuracy 85.13% → 86.63% (+1.50), POPE F1 83.64 → 86.37 (+2.73). On Qwen-VL-Chat: CHAIRs 46.60 → 40.80 (−5.8), POPE 85.10% → 86.83%. Under nucleus decoding, CHAIRs drops by as much as 9.4 points. BRACS retains 80% greedy throughput and runs an average of 1.3× faster than baseline steering methods. 11
Comparison with prior work: VCD, VDD-None, PAI, and SPIN are the baselines. BRACS's closed-form computation is the throughput advantage over methods that require iterative optimization or multiple forward passes. Crucially, BRACS maintains or improves scores on MME, MMBench, and MMMU — confirming that general capability is not sacrificed.
Evaluation CHAIR, POPE, MMHal; LLaVA-1.5-7B, Qwen-VL-Chat.
IC-VCO: in-context visual contrastive optimization (ICML 2026)
ArXiv 2605.31312 · Venue ICML 2026 (Accepted) · Status Accepted
Authors Haolin Deng, Xin Zou, Zhiwei Jin, Chen Chen, Haonan Lu, Xuming Hu · Institution OPPO Mente Lab
Methodology Fine-tuning via DPO with shared multi-image context; hard negative mining via contrastive sample editing
Code https://github.com/OPPO-Mente-Lab/IC-VCO
Visual Preference DPO — using contrastive image pairs to train LVLMs to prefer hallucination-free responses — has a structural problem: when two different images serve as inputs, the DPO partition function does not cancel across preferred and dispreferred samples, making the objective theoretically inconsistent. IC-VCO (In-Context Visual Contrastive Optimization) resolves this by placing both the target image and its contrastive counterpart inside a shared multi-image context, with an anchor prompt specifying which image the current generation should attend to. This ensures the partition function cancels exactly, restoring the DPO objective's theoretical guarantees. 12
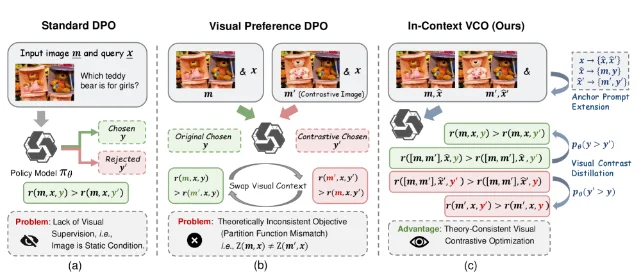
The negative mining strategy — Contrastive Sample Editing — applies precise local pixel-level edits to generate hard negatives with CLIP similarity 94.72 (versus 72.88 for standard synthetic negatives), producing 19,453 hard negatives. A VCDist auxiliary regularizer ensures consistency between multi-image training and single-image inference. On LLaVA-NeXT-Interleave-Qwen-7B: IC-VCO reaches overall 63.35 versus SymMPO's 62.11 (the strongest baseline), HallusionBench aAcc 63.51, AMBER-Attr 82.24%, CRPE-Exist 94.15, BLINK Score 49.44. 12
Comparison with prior work: The theoretical contribution (fixing partition function mismatch) distinguishes IC-VCO from RLHF-V, UE-DPO, and other visual preference methods. The hard negative quality gap (94.72 vs. 72.88 CLIP similarity) is the practical reason the optimization works — coarse negatives create shortcut learning that IC-VCO's editing strategy avoids.
Evaluation HallusionBench, AMBER, CRPE, BLINK; LLaVA-NeXT-Interleave-Qwen-7B, LLaVA-OneVision-Qwen2-7B.
ReactBench: cause-driven multimodal hallucination benchmark
ArXiv 2605.29579 · Venue Preprint · Status Preprint
Authors 7 authors · Institution East China Normal University
Methodology Evaluation benchmark (cause-driven taxonomy, 4 task types)
Code/Data [https://reactbench.[github.io/](https://reactbench.github.io/)](https://github.io/](https://reactbench.github.io/))
ReactBench organizes hallucination evaluation around causal sub-types rather than surface phenomena. Four task types: Relational Erasure, Counterfactual Attribute, Alteration Tracing, and Dense Counting. The benchmark contains 4.7K images and 50K QA pairs, with three question formats per item (Short-Answer, Multiple-Choice, Yes/No) to enable format-controlled comparison. 13

The top model (Qwen3VL-32B-Thinking) reaches React-Score 65.3; LLaVA-v1.6-7B reaches 34.5. Short-Answer accuracy sits between 19.1% and 28.4% across models — a floor that indicates current models are largely guessing on open-ended generation under causal perturbation. 13 "Absurd-contrast" queries — where the distractor is visually implausible — cause the most severe performance drops (31.6% for Relational Erasure, 22.5% for Counterfactual Attribute), suggesting that models rely on plausibility priors more than visual evidence when the visual signal contradicts language priors. Chain-of-thought helps on Counterfactual Attribute (+8.0 for Qwen3VL-32B-Instruct) but hurts on Alteration Tracing and Dense Counting.
Evaluation Qwen3VL-32B-Thinking, Qwen3VL-32B-Instruct, InternVL3-8B, LLaVA-v1.6-7B; React-Score.
Additional multimodal papers
Dual-Pathway Circuits of Object Hallucination in VLMs (2605.13156) proposes a Dual-Pathway Circuit Analysis framework using activation patching across 5 VLM architectures to identify a visual grounding pathway and a separate hallucination pathway. Targeted suppression of hallucination-pathway components reduces object hallucination by up to 76% at minimal accuracy cost; the same circuit transfers selectively to relational hallucination but not to attribute hallucination. 14
Transcoders Trace Visual Grounding and Hallucinations in VLMs (2605.22902) uses Transcoders — sparse approximations of MLP sublayers — as causal proxies for layer-wise computation in Gemma 3-4B-IT. Transcoder attributions produce more stable visually-grounded token effects under patch ablation than SAE (Sparse Autoencoder) attributions; a logistic classifier over mechanistic graph features predicts hallucination at AUC 0.68. 15
Risk-aware Selective Prompting (RSP) (2605.28123, submitted ACL ARR 2026 May) finds that verification prompting introduces errors at all difficulty levels even as it corrects more errors on harder inputs. RSP uses pre-generation uncertainty signals to selectively trigger verification only when warranted, avoiding the degradation that always-on prompting causes on easy inputs. 16
CoSimUE (2605.30911) decomposes LVLM architecture into three dimensions (Linguistic Foundation, Visual Representation, Semantic Alignment) and maps each to a hallucination class (Co-occurrence, Similarity, Uncertainty). The headline finding: parameter scaling has limited effect on all three hallucination classes; jointly improving visual fidelity and alignment quality is the most effective intervention. 17
Stage-wise Preference Optimization (2605.16411) constructs hallucination-focused preference pairs through staged distractor generation — minimally perturbed but visually inconsistent alternatives — covering ambiguous spatial orientation, object relationships, OCR uncertainty, and adversarial false-premise scenarios. Claims to surpass several frontier proprietary VLMs on the ambiguous and adversarial subsets. 18
ICML 2026 highlights
Six hallucination-related papers appear in the ICML 2026 program; five are already accessible (FEPoID and IC-VCO appear above in their respective sections).
CAMP (Conflict-Aware Adaptive Margin Preference Alignment) 19 explicitly models when truthfulness-helpfulness conflicts arise — arguing that the two objectives are consistent for the large majority of samples and conflict only in a small subset. CAMP adaptively regulates optimization strength based on detected conflict, evaluated on UltraFeedback and standard hallucination benchmarks. Prior alignment methods that treat the relationship as uniformly collaborative or uniformly conflicting are the contrast class.
InsLen (Instruction Lens Score) 20 is a plug-and-play object hallucination detector for MLLMs that combines a Calibrated Local Score and a Context Consistency Score, derived from instruction token embeddings without any auxiliary model or training. Code is public. The core insight: instruction token embeddings implicitly encode visual information while filtering noise from misleading visual embeddings — making them a cleaner detection signal than visual token activations alone.
MEDA (Medical-Oriented Activation Editing) 21 is the first activation-editing method targeting medical LVLMs specifically. It integrates QMS (Query-decisive Manifestation Steering) to retrieve positive imaging manifestations for activation steering, and PDI (Principle-driven Diagnosis Induction) to construct expert-like clinical reasoning prompts. Evaluated across 6 benchmarks and 6 LVLMs; up to 10.2% gain on IU-Xray. 21
AFS (Anchor-Final Self-Supervision) 22 uses the discrepancy between intermediate and final layer predictions to generate token-specific self-supervision signals, applied via GRPO (Group Relative Policy Optimization) with no external annotation. Self-supervision selectively targets visually descriptive tokens through a hallucination-aware token classifier. Reduces hallucination without sacrificing recall in caption generation, with strong cross-dataset generalization.
DOUBT (Decoupled Object-level Understanding and Bridging via vMF-based Trustworthiness) received an Oral slot at ICML 2026 (July 9, 2026, KST) 23 — the only hallucination-related Oral in this year's program. DOUBT uses von Mises-Fisher (vMF) distribution-based trustworthiness modeling to decouple object-level understanding from bridging inference, with detailed methodology not yet available from the program abstract.
Engineering tools
QWED Protocol v5.1.1 — deterministic verification for structured outputs
Version v5.1.1 · Released 2026-06-01 · License Apache 2.0 · Stars 57
Link https://github.com/QWED-AI/qwed-verification
QWED provides an AISecOps framework for deterministic verification of AI outputs using mathematical, logical, and symbolic execution engines — applicable to structured outputs (SQL, code, schemas, math, logic) where verifying correctness is decidable. 24 The v5.1.1 patch tightens cache trust-context binding to prevent cross-context verification replay attacks, hardens attestation and audit paths toward fail-closed behavior, and aligns SDK metadata across Python, Go, and TypeScript clients. The framework spans 11 verification engines including symbolic, reasoning, batch, and agent-service flows. Model-agnostic; works with OpenAI, Anthropic, Gemini, Llama, and local deployments.
ValiRef — AI-powered citation validation for academic papers
Active development 133 commits · Last updated 2026-05-29 · License MIT · Stars 56
Link https://github.com/Gianthard-cyh/ValiRef
ValiRef detects hallucinated citations in academic papers by cross-referencing against ArXiv, Google Scholar, Semantic Scholar, OpenReview, OpenAlex, and DuckDuckGo. Four hallucination types: Fabrication, Attribution Error, Irrelevance, and Counterfactual. Detection uses DeepSeek LLM with ReAct (Reasoning and Acting) reasoning. 25 Reported accuracy: 88.1% on a 1,000-sample benchmark. Architecture features async-first design with token bucket rate limiting and circuit breakers for resilient multi-source API calls. Web interface live at valiref.com.
UQLM — uncertainty quantification library for LLM hallucination detection
Active development 984 commits · Last updated 2026-06-01 · License Apache 2.0 · Stars 1.2k
Link https://github.com/cvs-health/uqlm
Maintained by CVS Health (Fortune 500) and published in JMLR and TMLR, UQLM offers black-box, white-box, LLM-as-a-judge, ensemble, and long-text scorers — all returning calibrated confidence scores. 26 Recent additions include functional entropy for code generation (Bouchard et al., 2026) and long-text claim-level detection with uncertainty-aware response refinement. The library is LangChain-compatible and model-agnostic.
LettuceDetect — token-level RAG hallucination detection
Version v0.1.8 · Last updated 2026-06-01 · License MIT · Stars 578
Link https://github.com/KRLabsOrg/LettuceDetect
LettuceDetect identifies unsupported answer spans relative to retrieved context at token level, using ModernBERT for English and EuroBERT for 7 languages (German, French, Spanish, Italian, Polish, Chinese, English). 27 Outperforms all encoder-based and prompt-based models on RAGTruth at a fraction of the inference cost of LLM-based approaches. Context windows of 4K–8K. v0.1.7 added multilingual support; Streamlit demo and Python web API available.
Additional tools
entroly (403 stars, updated 2026-06-01) 28 acts as a local proxy for Claude, OpenAI, Gemini, and coding-assistant environments (Cursor, Claude Code, Codex, Aider), combining hallucination detection with context compression as a drop-in layer. Claims 70%+ cost reduction on Claude/OpenAI bills; independent verification at scale is pending.
iFixAi (459 stars, updated 2026-05-29) 29 runs 32 diagnostic tests across fabrication, manipulation, deception, unpredictability, and opacity categories against any OpenAI, Anthropic, Bedrock, Azure, or Gemini endpoint, outputting a letter-grade score in under 5 minutes. Aligned to OWASP LLM, NIST AI RMF, and ISO 42001.
GitHub topic activity: The
ai-hallucination topic grew from 21 to 23 repositories between May 15 and June 1; hallucination-detection now lists 416 public repositories (279 Python); hallucination-mitigation lists 97. 30Venue papers: EACL 2026
HalluZig (EACL 2026 Long) 31 from Purdue University (Shreyas N. Samaga, Gilberto Gonzalez Arroyo, Tamal K. Dey) applies zigzag persistence — a tool from topological data analysis that characterizes how connectivity patterns in a sequence of simplicial complexes evolve — to LLM layer-wise attention dynamics for hallucination detection. The topological features generalize across model architectures and outperform strong baselines on multiple benchmarks.
FactSelfCheck (Findings of EACL 2026) 32 from Wrocław University of Science and Technology (Albert Sawczyn and collaborators) proposes a zero-resource black-box approach: the model's text is decomposed into knowledge-graph triplets, and multi-response consistency is computed at the triplet level to produce fine-grained hallucination scores. Hallucination correction improves by +35.5% versus SelfCheckGPT's +10.6% on the same task. 32
Agentic pipeline mitigation
Multi-agent Nested Learning with semantic caching
ArXiv 2605.29055 · Venue Preprint (21 pages, 14 figures) · Status Preprint
Authors Diego Gosmar, Deborah A. Dahl
Methodology Multi-agent self-refinement pipeline + semantic similarity caching
Code/Data Not available
A three-stage agentic pipeline (FrontEndAgent → SecondLevelReviewer → ThirdLevelReviewer) operates under an Open Floor Protocol — a structured turn-taking framework inherited from spoken dialogue systems — and applies a HOPE-inspired Nested Learning architecture. Evaluated on a custom 310-prompt benchmark (217 epistemic-uncertainty + 93 fabrication-induction stress-test prompts), the pipeline achieves THS (Total Hallucination Score, a custom KPI composite) reductions of −31.3% to −35.9% across five weighting configurations. 33
Semantic caching achieves a 47.3% hit rate (440 cache hits out of 930 potential calls), reducing LLM invocations and reported CO2e footprint. The ExtremeObservability KPI configuration achieves the most negative final THS (−0.0709), suggesting that observability-heavy configurations reinforce hallucination mitigation rather than competing with it. 33
Caveat: THS is a custom non-public metric, and the benchmark (310 prompts) is not publicly available. The results cannot be compared against standard benchmarks or independently replicated without the benchmark and metric definitions. Treat the percentage reductions as directional rather than comparable to figures from other papers.
Evaluation Custom 310-prompt benchmark; five KPI weighting configurations; THS composite metric.
Thematic synthesis
The convergence on training-free, single-pass interventions
The most consistent pattern across this window is the alignment between text-only and multimodal sub-areas on a single design preference: no retraining, no auxiliary models, minimal compute overhead. In text-only probing, FEPoID makes layer selection automatic without labeled data; in multimodal steering, BRACS computes corrections in closed form using only the model's existing attention weights; in preference optimization, AOD's inference-time contrastive decoding adds only a second forward pass. The cost of deploying a hallucination intervention has dropped from "retrain the model" to "add one pass."
The durability of this preference is worth examining. The methods that get the best numbers still involve some training component — IC-VCO trains preference pairs, AOD trains a disentanglement head, the ICML-accepted methods (MEDA, AFS) all involve model modifications. The training-free claim for inference-time variants is accurate, but the full AOD and IC-VCO pipelines require a training phase. The correct framing is that deployment is training-free; development is not.
Multimodal: causal structure matters more than visual capacity
Two independent papers in this window reach structurally similar conclusions about where LVLM hallucinations originate. CoSimUE finds that scaling model parameters has limited effect on any of the three hallucination classes it defines; jointly improving visual fidelity and alignment quality is the most effective intervention. The Dual-Pathway Circuits paper finds that a distinct hallucination pathway exists independently of the visual grounding pathway and can be selectively suppressed. Neither finding attributes hallucination primarily to vision encoder weaknesses — consistent with last month's HalluScope finding that language priors dominate.
The practical consequence is that vision encoder improvements will continue to have diminishing returns on hallucination rates as long as the language component's prior is strong enough to override visual evidence. This points toward alignment-stage interventions (IC-VCO, UE-DPO, AFS) and inference-time grounding enforcement (BRACS, AOD, RSP) as the more productive directions.
Domain specialization is accelerating faster than general-purpose benchmarks
Four benchmarks this window (K-FinHallu, Trajel, CiteCheck, bug-report study) target narrow deployment contexts rather than general factual QA. Each introduces a custom hallucination taxonomy that does not reduce to TruthfulQA or HaluEval categories. The 46-estimator study (2605.27016) independently motivates this trend by showing that estimator rankings are dataset-specific rather than model-specific — which means that deploying any general-purpose hallucination guard without domain-specific validation is likely to produce overconfident or misranked results.
The research community has not yet converged on a protocol for combining domain-specific benchmark results into a cross-domain comparison. ReactBench's React-Score and Trajel's clarity-and-justification AUC are both methodologically motivated but not comparable to each other or to POPE/CHAIR. Practitioners evaluating deployment-readiness will need to run their own domain-specific evaluations rather than relying on published cross-domain numbers.
Directions absent this window
Knowledge editing (ROME, MEMIT-style fact updating) produced no papers. RAG architecture papers targeting hallucination directly — as opposed to detection after the fact — were also absent, despite RAG remaining a primary deployment context. Factuality fine-tuning at scale (instruction tuning for factual grounding across general tasks) had no notable entries. These absences likely reflect NeurIPS 2026 submission pressure concentrating effort elsewhere; the June–July window should be watched for these sub-areas.
Cover image: AI-generated.
参考ソース
- 1Automatic Layer Selection for Hallucination Detection
- 2MultiHaluDet: Multilingual Hallucination Detection via LLM Hidden State Probing
- 3MultiHaluDet: Multilingual Hallucination Detection via LLM Hidden State Probing
- 4Evaluating the Relevance of Uncertainty Estimators for LLM Hallucination
- 5Trajel: Auditing Trajectory-Level Hallucinations in Multi-Agent Industrial Workflows
- 6CiteCheck: Retrieval-Grounded Detection of LLM Citation Hallucinations
- 7CiteCheck: Retrieval-Grounded Detection of LLM Citation Hallucinations
- 8K-FinHallu: A Hallucination Detection Benchmark for Multi-Turn RAG in Korean Finance
- 9Empirical Analysis and Detection of Hallucinations in LLM-Generated Bug Report Summaries
- 10Adversarial Orthogonal Disentanglement for LVLM Hallucination Mitigation
- 11BRACS: Barrier-Regulated Adaptive Closed-form Steering
- 12IC-VCO: In-Context Visual Contrastive Optimization
- 13ReactBench: Cause-Driven Benchmark for Multimodal Hallucination
- 14Dual-Pathway Circuits of Object Hallucination in VLMs
- 15Transcoders Trace Visual Grounding and Hallucinations in VLMs
- 16Risk-aware Selective Prompting for Hallucination Mitigation
- 17CoSimUE: Architectural Analysis of LVLM Hallucination
- 18Stage-wise Preference Optimization for VLM Hallucination
- 19CAMP: Conflict-Aware Adaptive Alignment for LLM Hallucination
- 20InsLen: Instruction Lens Score for MLLM Hallucination Detection
- 21MEDA: Medical-Oriented Activation Editing for Hallucination Mitigation
- 22AFS: Anchor-Final Self-Supervision for Hallucination-Aware LVLM Optimization
- 23DOUBT: vMF-based Trustworthiness for Hallucination Detection (Oral)
- 24QWED Protocol: Deterministic AI Verification Framework
- 25ValiRef: AI-Powered Citation Validation
- 26UQLM: Uncertainty Quantification for Language Models
- 27LettuceDetect: Lightweight Hallucination Detection for RAG
- 28entroly: Local Proxy with Hallucination Detection
- 29iFixAi: Open-Source Diagnostic for AI Misalignment
- 30GitHub Topics: ai-hallucination
- 31HalluZig: Hallucination Detection using Zigzag Persistence
- 32FactSelfCheck: Fact-Level Black-Box Hallucination Detection
- 33Agentic AI Hallucination Mitigation with Nested Learning and Semantic Caching
このコンテンツについて、さらに観点や背景を補足しましょう。