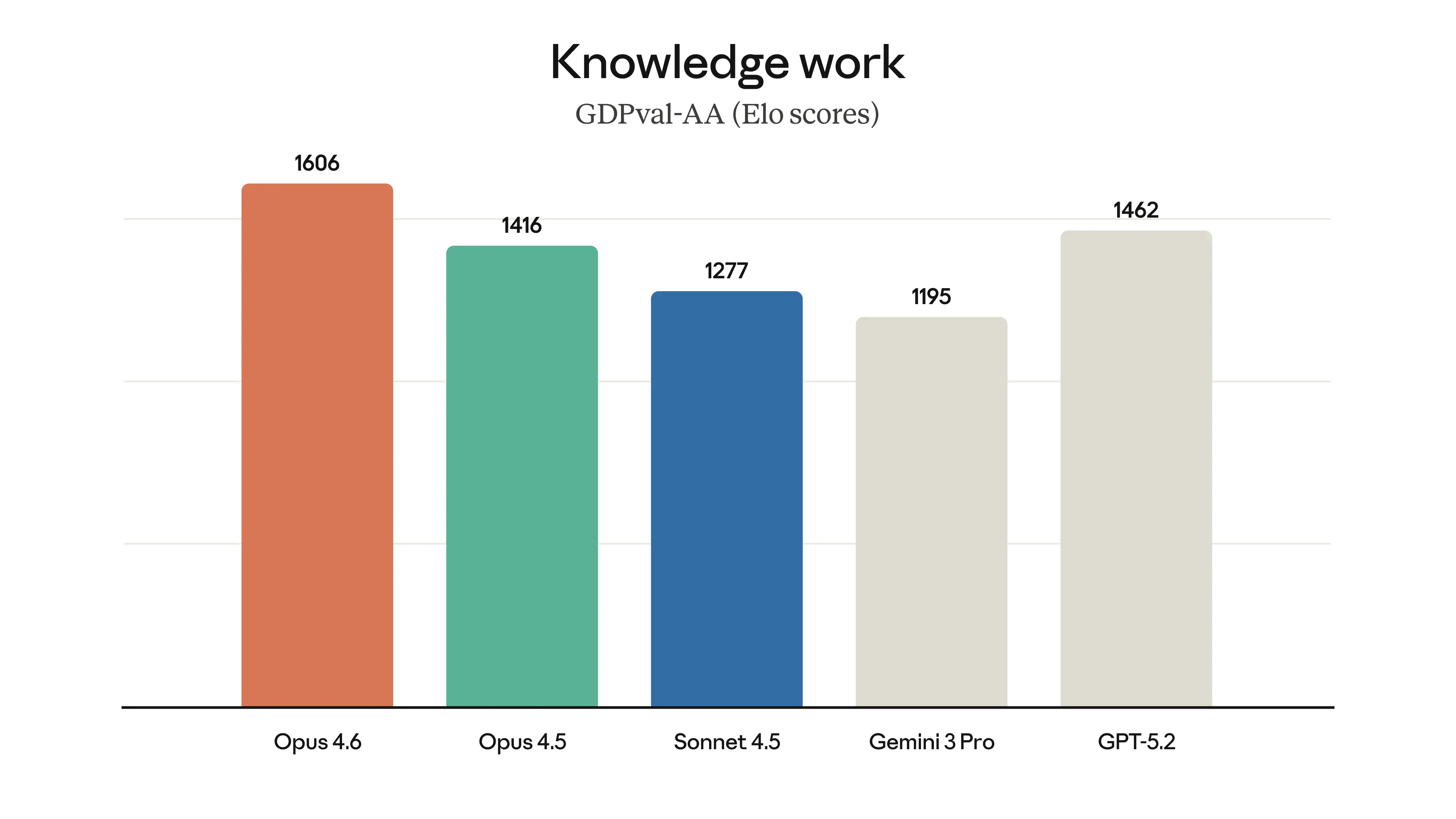
Opus 系列核心基准对比(2026 Q1)
SWE-bench Verified / CursorBench / 视觉敏锐度
2026 年 2 月至 5 月,Anthropic 在模型、定价、产品、对齐研究四条线同步推进:Opus 4.6/4.7、Sonnet 4.6、Haiku 4.5 密集迭代,旗舰降价 67%,Mythos Preview 引发 AI 安全新关注,agent 编排架构全面成熟。
/v1/messages/count_tokens 端点对典型负载做并排测试,再决定是否迁移。cache_control 字段,系统自动缓存最后一个可缓存块9。理论上,Batch API + Prompt Caching 叠加后有效成本可降至标准价的约 5%。
このコンテンツについて、さらに観点や背景を補足しましょう。