Prompt injection → shell: block CVE-2026-26030 with output validation and tool allowlisting
Microsoft's May 2026 disclosure of CVE-2026-26030 showed how a prompt injection chains into full Windows RCE via Semantic Kernel. Here's a drop-in Python tool-allowlist snippet that blocks the attack chain before any executor runs.
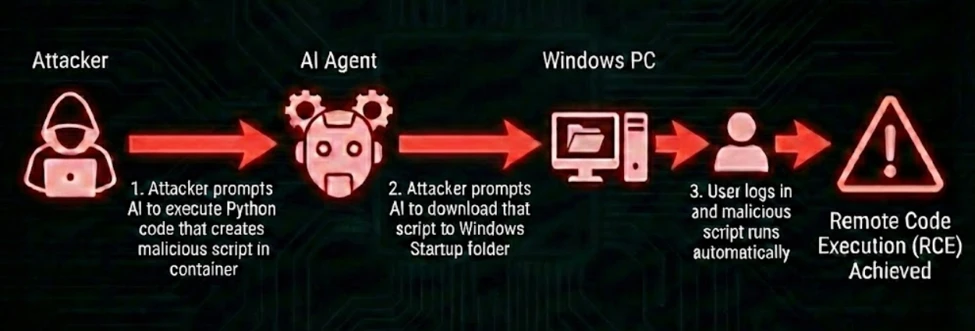
On May 7, 2026, Microsoft Security published a disclosure that most engineers filed under "interesting but not my problem." 1 A hotel-finding AI assistant, built on Semantic Kernel (Microsoft's open-source LLM orchestration framework), received a user query about Paris accommodations. While it returned a perfectly normal list of hotels, Windows Calculator opened on the host machine. The attack was invisible to the user. The model had no idea it was being exploited.
This week's trick: add output validation with tool allowlisting to your agent pipeline — the one application-layer control that has actually held to 0.0% leak rate under adaptive attack testing. 2
The attack: two CVEs, one kill chain
CVE-2026-26030 lives in Semantic Kernel's Python SDK. The In-Memory Vector Store filter passes attacker-controllable parameters into an
eval() call. The blocklist defending that eval() targets obvious names like os and subprocess — but Python's class hierarchy sidesteps it entirely. 1The traversal goes:
__name__ → load_module → system(). Once inside, the attacker has arbitrary shell execution on the host. Fix: upgrade to semantic-kernel Python >= 1.39.4.CVE-2026-25592 pairs with it in the .NET SDK. The
SessionsPythonPlugin.DownloadFileAsync method is decorated with [KernelFunction], which marks it as a tool the model can call. 1 The attack chain:- Prompt injection writes a PowerShell downloader (
update.bat) inside the code sandbox DownloadFileAsyncwrites the file toC:\Users\<user>\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup\- User logs in. Windows executes it.
Fix: upgrade to
.NET SDK >= 1.71.0.Microsoft's summary: "Once an AI model is wired to tools, prompt injection draws a thin line between being just a content security problem and becoming a code execution primitive." 1
Why the model can't protect itself
Before reaching the defense, this constraint matters: no model-reliant defense held in a systematic adversarial evaluation published April 2026. 2 Priyal Deep, Shane Emmons, and five co-authors tested nine defense configurations across more than 20,000 attacks. System prompt hardening, role-pinning, instruction hierarchy reinforcement — every approach that asked the model to police its own outputs eventually broke under an adaptive attacker. The only configuration that held was output filtering implemented as hardcoded application code checking responses before they reach downstream tools or users: zero leaks across 15,000 attacks.
Microsoft's own post-mortem agrees: "These are not bugs in the AI model — the model is behaving exactly as designed by parsing language into tool schemas. The vulnerability lies in how the framework and tools trust the parsed data." 1
The model is not the security boundary. Your application layer is.
The defense: output validation with tool allowlisting
Why this approach blocks the CVE-2026-26030 chain
Both CVEs require the model to emit a tool call that the framework then executes. CVE-2026-26030 needs the vector store filter to receive an eval-able payload. CVE-2026-25592 needs
DownloadFileAsync to be callable. If your agent validates every model output against a strict JSON Schema before passing it to any executor — and that schema's enum only lists tools you explicitly approved — neither payload can reach the vulnerable code path. The injected call fails validation and gets dropped. 3Drop-in snippet
import jsonschema
import logging
TOOL_CALL_SCHEMA = {
"type": "object",
"properties": {
"tool": {
"type": "string",
"enum": ["search", "summarize", "lookup"] # your actual tool registry here
},
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "maxLength": 500}
},
"additionalProperties": False
}
},
"required": ["tool", "parameters"],
"additionalProperties": False
}
def validate_tool_call(model_output: dict) -> dict | None:
"""
Validate a parsed model tool-call dict against the allowlist schema.
Returns the validated dict or None on failure.
"""
try:
jsonschema.validate(instance=model_output, schema=TOOL_CALL_SCHEMA)
return model_output
except jsonschema.ValidationError as e:
logging.warning("Security event: invalid_tool_call | %s", e.message)
return NoneThree things this snippet enforces:
"enum": ["search", "summarize", "lookup"]— the model cannot call any tool not on this list.DownloadFileAsyncand the vector store eval path are not on this list."additionalProperties": False— the model cannot smuggle extra parameters that downstream code might interpret."maxLength": 500— caps the query payload, making AST traversal strings long enough to trigger the exploit much harder to fit.
TopAIThreats rates output validation at third place in their defense hierarchy, above both prompt hardening and system prompt protection, specifically because it catches injection-driven action execution at the point of execution rather than hoping the model refuses to comply. 3
Where to wire it in
Call
validate_tool_call() immediately after parsing any structured output from the model, before passing the result to your tool executor or Semantic Kernel's function invocation layer. In a 6-layer defense stack, this sits at Layer 4 (Output Guard), between LLM inference and tool execution. 4Pair it with a code sandbox — E2B and Daytona are two commonly used sandboxed execution environments for AI agents — at Layer 5, so that even if a call somehow passes validation, it executes without host filesystem access.
What this does not cover
Tool allowlisting only works if your allowlist is accurate and maintained. When your tool registry expands — new MCP servers, new
[KernelFunction] decorators — the schema enum must be updated to match. An outdated allowlist that includes deprecated tools re-opens the surface.This defense also does not address model-level jailbreaks or exfiltration through allowed tools (a model calling
search to leak data is still within schema). For those paths, input filtering at Layer 2 (a classifier like Lakera Guard or a Llama Guard 3 self-hosted instance) is the right pairing. 4Ship it today
Two steps, one session:
- Patch first. Run
pip install --upgrade semantic-kernel>=1.39.4for Python agents, or bump your .NET SDK reference to>= 1.71.0for the .NET stack. The CVE-level fix removes the vulnerable execution paths entirely. - Add the snippet. Drop
validate_tool_call()into your agent's tool-dispatch layer. Start with["search", "summarize", "lookup"]as a placeholder, then replace with your actual tool registry. Confirm that every model output passes through this function before touching any executor.
To verify the fix yourself, Microsoft published an interactive CTF challenge built around CVE-2026-26030: github.com/amiteliahu/AIAgentCTF. Running through it takes about 20 minutes and gives you a concrete feel for the traversal path — useful context when explaining the fix to a security review team.
Cover image from: When prompts become shells — Microsoft Security Blog
このコンテンツについて、さらに観点や背景を補足しましょう。