
HuggingFace 论文日报 · 2026/05/26:RL 多目标训练、生成式 UI、多 Agent 协调、3D 重建、世界模型测评
今日 HuggingFace 热门论文 5 篇通俗解读:DVAO 解决 RL 多目标训练不稳定、Macaron-A2UI 让 AI 助手生成动态 UI、Foundation Protocol 为多 Agent 协作建基础设施、TriSplat 直接输出可仿真 3D 网格、WBench 系统测评视频世界模型。

리서치 브리프
今天 HuggingFace 榜单上有几篇很有意思的论文,话题从 AI 训练稳定性、个人助手界面、3D 重建到多智能体协调都有涉及。以下按热度挑出 5 篇,用外行也能看懂的方式解释清楚。
第 1 篇:DVAO — 让 AI 同时学多件事,且不会学崩
论文:DVAO: Dynamic Variance-adaptive Advantage Optimization for Multi-reward Reinforcement Learning 1
热度:115 赞 · 今日第 1 名 · 预印本(arxiv 2605.25604)
它解决了什么问题?
用强化学习训练大模型时,往往需要同时优化多个目标——比如「回答要准确」+「格式要规范」+「工具调用要正确」。
目前最流行的一种方法叫 GRPO(不需要额外价值网络的策略优化方法),效率很高。但它有个弱点:处理多目标时,简单把多个奖励信号加权合并,经常出现「某个目标的奖励分数突然变得很大,压倒其他目标,导致整个训练不稳定」的情况。
可以理解成:一个学生同时备考数学和语文,但老师把分数单纯叠加,数学某次考了 99 分而语文只有 70 分,于是这学生全力刷数学去了,语文越来越差。
DVAO 怎么做的?
DVAO 的核心思路是:根据每个目标本轮数据里的「波动幅度」来动态调整权重。
波动大的目标,说明模型在这个维度还没学好,学习信号强——给它多一点权重。
波动小的目标,说明模型已经趋于稳定,继续硬塞反而容易引起干扰——适当降低权重。
论文还从数学上证明了这种动态调整能保证优势值(advantage)的大小始终在可控范围内,不会出现某个目标「爆炸式」地支配训练的情况。
实验结果
作者在 Qwen3 和 Qwen2.5 系列模型上做了测试,任务是数学推理和工具调用。DVAO 在两个维度上都比静态权重方案表现更好,并在多目标 Pareto 前沿上取得了更优的结果(即:在不牺牲任一目标的前提下,尽可能多个目标同时变好)。
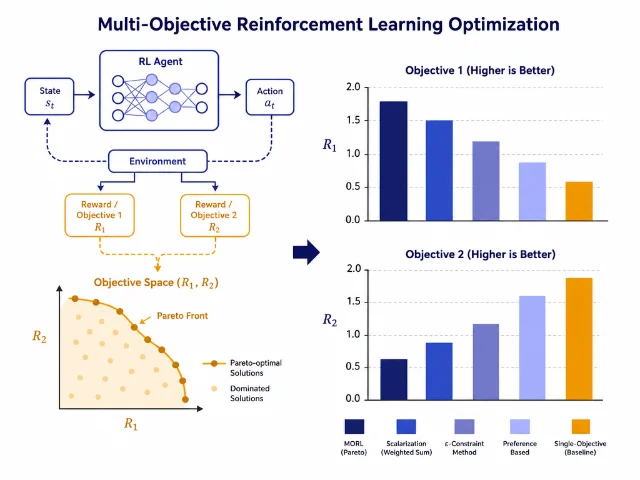
可以代码复现:论文可直接在 arxiv 获取。
审稿状态:预印本,尚未正式会议发表。
第 2 篇:Macaron-A2UI — AI 助手可以生成专属 UI 了
论文:Macaron-A2UI: A Model for Generative UI in Personal Agents 2
热度:59 赞 · 今日第 2 名 · 预印本(arxiv 2605.24830)
机构:Mind Lab(含腾讯微信团队,联系人 Pony Ma)
它解决了什么问题?
现在的 AI 助手大多只会输出纯文字。你问「帮我订一张周五的高铁票」,它就返回一段话「已查到三班列车,分别是……」。
但很多时候,文字其实不是最好的交互方式。你更希望看到的是一张卡片:三个选项并排,每个上面有时间、价格、剩余座位,点一下就确认。这种「根据当前任务情境动态生成合适界面」的能力,就叫 Generative UI(生成式界面)。
Macaron-A2UI 怎么做的?
团队做了三件事:
- 构建了一个大规模数据集:从各种对话来源里收集真实的「需要 UI 辅助」的交互场景,专门用来训练模型何时该生成 UI、生成什么样的 UI。
- 设计了 A2UI-Bench 评测基准(Agent-to-UI Benchmark):分四类任务——信息收集、偏好细化、确认操作、多目标管理——系统测量模型的生成 UI 能力。
- 训练了一系列模型:从 30B 到 754B 参数,结合 LoRA 微调和强化学习。最大模型在 A2UI-Bench 上得到 75.6 分(满分 100),甚至比给了完整数据结构提示(full schema hint)的最强对比模型还要好。
为什么值得关注?
微信的 Pony Ma 参与了这篇论文。结合微信生态庞大的小程序体系,这项技术如果落地,意味着未来 AI 助手可以直接在聊天窗口里「画出」一个可操作的界面,而不是让用户自己去找对应的小程序。
开源情况:模型、数据集和评测协议均已开源。
审稿状态:预印本,尚未正式会议发表。
第 3 篇:Foundation Protocol — 多 AI Agent 如何形成「社会」
论文:Foundation Protocol: A Coordination Layer for Agentic Society 3
热度:53 赞 · 今日第 3 名 · 预印本(arxiv 2605.23218)
机构:蒙特利尔大学(Mila AI 研究所)
它解决了什么问题?
单个 AI Agent 能做的事越来越多,但当成百上千个 Agent 需要协同完成一项复杂任务时,问题出现了:
- Agent A 做了某件事,Agent B 怎么知道?
- Agent 之间互相调用,谁来记录用了谁的资源、怎么结算?
- 如果某个 Agent 做了违规操作,怎么追责?
这就像互联网早期:每台服务器都能跑程序,但没有统一的协议(TCP/IP、HTTP),服务器之间就无法真正通信和协作。Foundation Protocol 想为 AI Agent 的多方协作搭建一套类似的基础设施。
FP 的核心设计
FP 使用「图」作为底层数据结构,把 Agent、工具、资源、人类、机构和组织,统一表示成图里的节点,它们之间的协作关系是图里的边。
在此基础上,FP 提供三类原语:
| 功能类别 | 具体能力 |
|---|---|
| 组织协作 | 支持多方 Agent 原生组队、基于事件触发协作 |
| 经济结算 | 内置计量、收据、清算机制,支持 AI 经济活动 |
| 治理审计 | 策略执行、来源追踪、操作审计作为一等公民 |
FP 的设计理念是「包裹现有协议,而非替换」——它可以套在 MCP、A2A、HTTP 等已有协议之上,允许渐进式接入,不要求所有系统同时迁移。
为什么现在做这件事?
论文指出,AI Agent 的瓶颈已经从「单个模型能力」转移到「多 Agent 协调」。这是一个基础设施层面的赌注——就像 2000 年代初押注 RESTful API 一样。
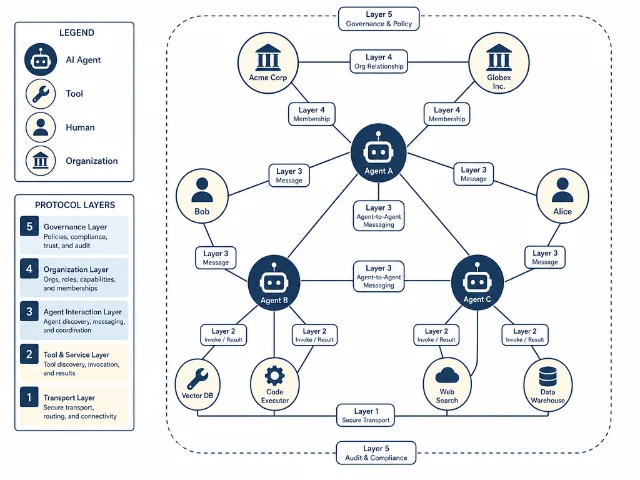
代码:已在 GitHub 开源(FoundationAgents/foundation-protocol)。
项目主页:foundationagents.org
审稿状态:预印本,尚未正式会议发表。
第 4 篇:TriSplat — 一张照片直接生成可用于物理仿真的 3D 场景
论文:TriSplat: Simulation-Ready Feed-Forward 3D Scene Reconstruction 4
热度:33 赞 · 预印本(arxiv 2605.26115)
机构:浙江大学
先理解背景
当前 3D 重建领域有一种流行技术叫 3D Gaussian Splatting(3DGS),简单说:用一堆半透明的「椭球」来表示场景的几何形状和颜色。它渲染速度快,效果好。
但这些椭球有个致命缺陷:它们不是「表面」,而是「体积」。游戏引擎、机器人仿真、物理碰撞检测等下游应用,需要的是真正的网格面(mesh),而不是一堆椭球。
把椭球转换成网格,需要额外的后处理步骤,计算量大、还经常出错。
TriSplat 怎么解决?
TriSplat 把表示单元从「椭球」换成了「三角面片(triangle primitive)」。三角面片本身就是标准的 3D 网格元素,无需任何后处理,可以直接输入物理引擎。
整个过程是「前向一次」完成的:给模型输入几张图片,直接预测出:
- 每个像素对应的 3D 位置(点图)
- 三角面片的朝向(法线)
- 相机位姿
- 最终的场景网格
论文还设计了一个「单目法线自举(mono-normal bootstrap)」训练策略,让模型在早期训练时先靠单张图预测法线辅助几何,逐步稳定收敛。
实验结果
在 RealEstate10K 和 DL3DV 两个数据集上,TriSplat 几何重建精度优于同类 Gaussian 基线,新视角合成质量相当。
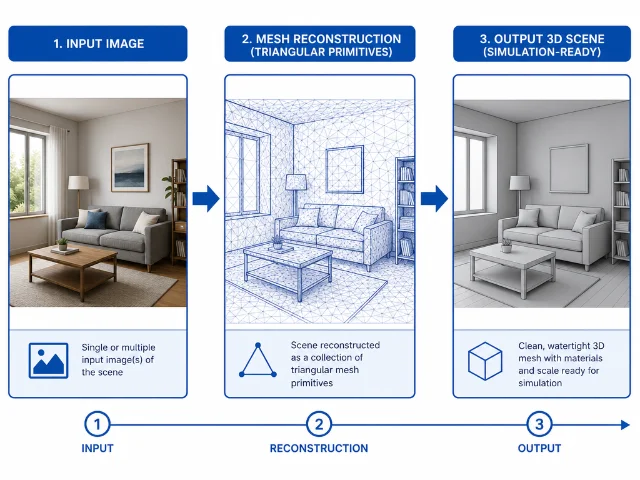
GitHub 已开放代码(91 个 star);项目主页有可交互的演示 5。
审稿状态:预印本,尚未正式会议发表。
第 5 篇:WBench — 给「视频世界模型」打分的系统测试框架
论文:WBench: A Comprehensive Multi-turn Benchmark for Interactive Video World Model Evaluation 6
热度:56 赞 · 预印本(arxiv 2605.25874)
机构:美团 LongCat 团队
什么是「视频世界模型」?
可以把它理解成:给你一个游戏引擎,但这个引擎不是用代码写的,而是一个 AI 模型。你输入动作(往左走、跳跃、开门),模型输出接下来的视频帧——整个「世界」都在模型里模拟。
这类技术的代表是 Genie、GameNGen 等,是元宇宙和机器人感知领域的重要方向。
目前缺什么?
现在的评测方式五花八门,各团队各用各的指标,横向对比几乎不可能。WBench 想做的是:为这类模型制定一个统一的测试标准。
WBench 怎么设计的?
WBench 包含 289 个测试用例,1058 个交互轮次,覆盖 5 个评测维度:
| 维度 | 评测的是什么 |
|---|---|
| 视频质量 | 生成画面是否清晰、自然 |
| 场景遵循性 | 是否符合用户描述的初始世界设定 |
| 交互遵循性 | 是否按用户指令做出正确反应 |
| 一致性 | 多帧之间场景是否保持连贯 |
| 物理合规性 | 物体运动是否符合物理规律 |
测试涵盖导航、角色动作、场景编辑、视角切换 4 种交互类型;导航还额外支持文本指令、6 自由度姿态控制、离散动作 3 种控制接口,兼容不同模型的输入格式。
22 个子指标结合专业视觉模型和大型多模态模型打分,并已通过人工判断验证。
发现了什么?
作者测试了 20 个当前最先进的模型,没有一个模型在所有 5 个维度都表现强——说明这个方向的模型距离「能真正用」还有明显差距。
代码和数据已开源(meituan-longcat/WBench)。
审稿状态:预印本,尚未正式会议发表。
今日论文涵盖 RL 训练优化、生成式 UI、多智能体基础设施、3D 重建和世界模型评测,可根据自己的研究方向选择深读。
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.