23/6/2026 · 14:05
DPO's Arrow-shaped bargain
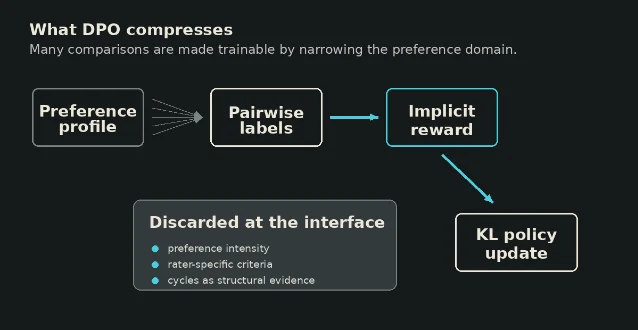
DPO looks clean because it compresses pairwise human preferences into an implicit reward scale, but that tractability comes from discarding plural disagreement rather than solving it.

DPO buys tractability by refusing to represent disagreement as disagreement.
The method is usually described as a cleaner RLHF objective. True, but incomplete. The social-choice reading is sharper: Direct Preference Optimization turns a messy profile of human comparisons into one KL-regularized policy update by assuming the comparisons are samples from a single latent reward scale. The impossibility it runs into is Arrow-shaped. It escapes only by narrowing the admissible preference domain.
The method: pairwise labels become an implicit reward
Rafailov, Sharma, Mitchell, Ermon, Manning, and Finn introduced Direct Preference Optimization in 2023; the arXiv v1 was submitted on 29 May 2023, and the OpenReview record lists the NeurIPS 2023 version as published on 21 Sept 2023.12
DPO starts from the same kind of data used in reward-model RLHF: for a prompt
x, annotators compare two completions and label one winner y_w and one loser y_l. The DPO paper states the standard reward-modeling phase as a dataset of triples {x, y_w, y_l} and models the probability of a preference with a Bradley-Terry style logistic comparison over latent rewards.3The move that makes DPO distinctive is the reparameterization. Instead of first fitting a separate reward model and then running PPO or another RL algorithm, DPO expresses the reward difference through the log-ratio between the trained policy and a reference policy. The paper's objective directly increases the relative log probability of the preferred completion and decreases the relative log probability of the dispreferred completion, with a KL-strength parameter controlling deviation from the reference model.3
Figure 1 in the DPO paper contrasts the RLHF reward-model-then-RL pipeline with DPO's direct preference objective.3
So the aggregation rule is not a vote over complete rankings. It is a statistical compression of local pairwise choices into one policy-relative scalar field. That scalar field may be implicit, but it still plays the social-choice role of a common ordering device.
The theorem: Arrow says the full preference profile cannot be kept
Arrow's 1950 article, "A Difficulty in the Concept of Social Welfare," appeared in the August 1950 issue of the Journal of Political Economy, volume 58, number 4, with DOI 10.1086/256963.4
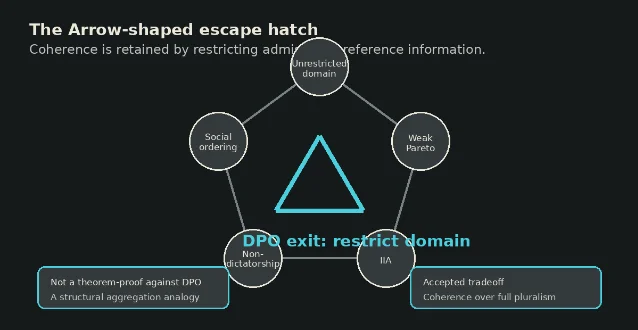
In the standard presentation, Arrow asks for a procedure that turns individual preference orderings into a social ordering. The Stanford Encyclopedia of Philosophy summarizes the core conditions as unrestricted domain, weak Pareto, non-dictatorship, social ordering, and independence of irrelevant alternatives; outside trivial cases, no aggregation procedure satisfies them all.5
DPO is not a voting rule, so the mapping is not a literal proof that DPO violates Arrow. The narrower claim is structural. DPO compresses many local human comparisons into one socially usable preference object. If we demand a procedure that can ingest arbitrary human preference profiles, preserve conflicts, respect unanimity, avoid dictatorship, and produce one coherent ordering, Arrow tells us that demand set is inconsistent.
DPO avoids that collision by not accepting the full demand set.
The accepted tradeoff: domain restriction over social choice
DPO's accepted tradeoff is best described as domain restriction. It assumes the usable preference data can be represented as if it came from a single latent reward structure, at least within the comparison distribution the training set covers. That assumption is what permits the logistic classification loss to stand in for reward learning plus policy optimization.
| Social-choice requirement | What DPO does instead | Why this matters |
|---|---|---|
| Handle arbitrary preference profiles | Fits pairwise comparisons under a Bradley-Terry or related preference model.3 | Cyclic, plural, or context-dependent preferences are not represented as first-class structure. |
| Produce a complete social ordering | Produces a policy-relative implicit reward, then updates token probabilities through the DPO loss.3 | The output is operationally decisive, not socially comprehensive. |
| Preserve independence across alternatives | Uses sampled pairs against a reference policy and learns from their relative log-probability ratios.3 | The learned result depends on which pairs were sampled, which model generated them, and what the reference policy makes likely. |
That is not a defect in the engineering sense. It is the price of making the problem trainable. The method chooses a tractable statistical domain over a full social-choice domain.
The discarded information: where disagreement goes
The lost information is specific.
First, DPO discards most of the preference profile. A label says that one completion beat another for a prompt. It does not retain a judge's complete ranking over plausible completions, a stable personal utility function, or a reasoned account of which criterion carried the choice.
Second, DPO discards interpersonal structure. Arrow's framework deliberately treats individual preferences as ordinal and notes the difficulty of comparing preference intensity across people.6 DPO goes in the other direction operationally: it learns as if the observed choices can be pooled into one training signal. If one rater prefers safety because of harm avoidance and another prefers usefulness because of task completion, the label format does not preserve that normative difference.
Third, DPO discards cycles as signal. If annotator groups produce
A > B, B > C, and C > A, Arrow-style social choice treats that as a structural problem. DPO has no natural place for the cycle except as noisy or inconsistent comparisons inside a loss.The common claim that DPO removes the reward model is therefore slightly misleading. It removes the explicit reward-model training stage. It does not remove the social-choice compression. The compression has simply moved into the preference model, the reference policy, and the loss.
Practical consequence: cleaner training, narrower alignment semantics
For practitioners, the benefit is real. DPO is simpler than PPO-based RLHF because it avoids a separate reward-model training stage, avoids sampling from the LM during fine-tuning, and optimizes a classification-style objective on preference pairs.1
The consequence is also real. DPO is strongest when the preference data approximately behaves like a coherent latent reward order over the sampled completions. It is weaker as a representation of plural human values. Minority preferences, criterion conflicts, and non-transitive tradeoffs can be optimized over only after they have been flattened into pairwise wins and losses.
So the method gives up this: it cannot tell you whether the trained policy reflects a legitimate aggregation of human preferences. It can tell you that, under a chosen preference model and reference policy, the policy moved in the direction implied by the labels. That is the narrower, honest claim.
Añade más opiniones o contexto en torno a este contenido.