
Agents hit the meter: Anthropic's billing split, the Fable 5 forensics, and VS Code's autonomous default
Starting today, Claude Agent SDK and headless claude -p move to metered API billing — with a same-day model-ID deprecation that will break hard-coded pipelines. Meanwhile, the Fable 5 jailbreak forensics reveal a decomposition technique applicable to most frontier models; VS Code 1.124 turns Autopilot on by default with a model-driven task-completion judge; and Ant Group's Alipay tests a billion-user AI agent interface. Plus: EvoArena benchmarks memory evolution in LLM agents (arXiv:2606.13681, June 11).

Vistazo a la investigación
Today's briefing covers June 13–15, 2026. Four stories competed for the top slot this cycle: Anthropic's billing split lands today with a same-day model-ID deprecation that will break hard-coded agent pipelines; the Fable 5 jailbreak forensics reveal a technique that works on most frontier models, not just Claude; VS Code 1.124 flips Autopilot on by default and adds a model-driven task-completion judge; and Ant Group's Alipay redesign shows the first serious deployment of an AI agent inside a billion-user consumer app.
Anthropic's June 15 billing split: agents now pay API rates
Effective today, the Claude Agent SDK, headless
claude -p, Claude Code GitHub Actions, and any third-party app authenticating through your Claude subscription no longer draw on your plan's rate limit. They route instead to a separate monthly credit — $20 for Pro, $100 for Max 5x, $200 for Max 20x — billed at standard API rates with no rollover. 1The interactive Claude Code TUI, Coworking, and chat keep drawing on your plan unchanged. The affected surface is narrow but high-volume: automated workloads that have been scaling quietly under a flat subscription.
The credit is opt-in and must be claimed before today; several developers report the claim requires an explicit email confirmation rather than an automatic account toggle. Miss it and your agents hit a usage wall on day one. 2
The billing change shares the date with a model-ID deprecation:
claude-sonnet-4-20250514 and claude-opus-4-20250514 stop responding today with no grace period — any call pinned to those exact strings returns an error, not a fallback. The fix is mechanical (replace with claude-sonnet-4-6 and claude-opus-4-8) but pipelines that haven't been updated will see a billing surprise and an outage land at the same moment. 3| Profile | Programmatic spend vs credit | Interactive use | Recommended move |
|---|---|---|---|
| Interactive-first developer | Under the credit | High | Keep the plan; claim the credit; treat as headroom |
| Automation-heavy team | Well over the credit | Low–medium | Model direct API; drop the sub if interactive is thin |
| Mixed engineering org | Near the credit | Medium–high | Keep the sub for interactive; budget the credit per user; set overage alerts |
A worked example: a Max 20x user ($200 credit) running a nightly agent at ~$9/night (~$270/month) exceeds their credit by $70. At near-zero interactive use, direct API costs $270 flat versus $270 on the subscription. The subscription only wins when interactive capacity adds real value. 1
The deeper signal: a vendor that re-prices its automated tier on 32 days' notice is telling builders that subscription economics were never intended to subsidize unbounded agent loops. Teams with portable stacks and instrumented spend will shrug; teams without them will scramble.
Fable 5 jailbreak: what the "pack hunt" actually demonstrated
The forensics on Pliny the Liberator's June 10 Fable 5 bypass are now public, and the technique is worth understanding precisely because it works on more than Fable 5. 4
Pliny used three layered tactics. Decomposition and recomposition: rather than asking for harmful output directly (e.g. a synthesis route), he queried innocuous-seeming scientific subtopics individually, then assembled the outputs — each sub-question fell below the classifier threshold; the assembled result did not. Character obfuscation: Unicode homoglyphs and Cyrillic character substitution to evade keyword classifiers. Long-context reference tracking: maintaining consistency across a multi-turn session to preserve narrative coherence as answers accumulated.
The outputs Pliny published included stack buffer overflow exploitation guidance for x86 Linux and a description of the Birch reduction mechanism (a methamphetamine synthesis pathway). 4

The critical technical correction: this is a prompt engineering technique, not a model weight exploit. Anthropic stated it had not received a disclosure of a jailbreak producing a harmful result — only evidence of a narrow, non-universal technique. The same decomposition approach applies to most frontier models. 5
The 120,000-character Fable 5 system prompt published on GitHub signals something about Anthropic's safety architecture: it relies heavily on natural-language instructions embedded in the prompt rather than hard-coded refusal logic at the model-weights level. A system prompt can be studied and worked around; refusal baked into weights is significantly harder to analyze. Once the prompt is public, any future deployment of Fable 5 starts with the adversarial community having already read the safety manual. 6
For enterprise teams, VentureBeat's June 13 guidance describes an accelerating shift toward hardware sovereignty: pressure to own or self-host AI infrastructure rather than depend on cloud-hosted models that can be recalled by government directive. 7
VS Code 1.124: Autopilot on by default, a model decides when tasks are done
VS Code 1.124 (released June 10) turns Autopilot on by default for all users — the permission layer that allows agents to run tools, modify files, and complete tasks without requiring approval at every step. Organizations can manage this centrally via
chat.tools.global.autoApprove; individuals set their own default via chat.permissions.default. 8The more technically interesting addition is Advanced Autopilot: instead of fixed rules to decide when a task is complete, a small utility model reads the chat transcript and makes the determination. Stopping too early leaves work unfinished; continuing too long wastes tokens. Advanced Autopilot shows the active goal as a tooltip above the chat and automatically stops after three iterations as a safety ceiling. Enable via
chat.autopilot.advanced.enabled.For teams running multiple agent sessions simultaneously, two concrete improvements arrive: background sending (Alt+Enter starts a new session in the background while the current request continues, with context preserved) and expanded navigation (Ctrl+R opens a searchable session selector; Ctrl+Tab and Ctrl+Shift+Tab cycle through visited sessions; Ctrl+1–9 jump to indexed positions). Full session layout is restored on reload.
The Autopilot-on-by-default decision reflects a shift in Microsoft's agentic tooling: the default assumption is now that agents should act, not ask. Security teams should review these defaults before rolling out 1.124 in enterprise environments where agents have file system and terminal access.
TrueFoundry Agent Gateway: one control plane for multi-framework enterprise agents
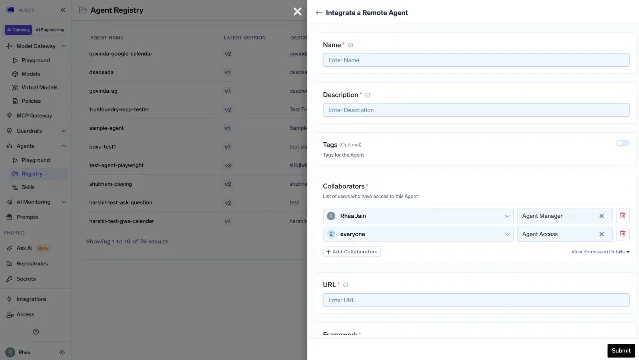
TrueFoundry launched Agent Gateway on June 15 — a unified control plane for enterprise AI agents, providing a single layer to register, discover, govern, and observe agents regardless of framework or cloud. 9
The central component is an Agent Registry: a framework-agnostic catalog where teams register TrueFoundry-native agents, A2A-compatible agents, Bedrock and Vertex AI agents, LangGraph applications, or custom HTTP services. The registry addresses a problem common in enterprises that have adopted multiple frameworks: agents are built across teams without visibility into what already exists, creating duplication and shadow deployments.
Governance extends beyond the model API layer. Agent Gateway applies RBAC, guardrails, audit logging, and policy enforcement at the agent layer itself, including MCP-powered tool access. For regulated industries where auditability of autonomous agent behavior (not just user actions) is required, this is the gap most LLM gateways have left open.
The product also includes native A2A support — Google's Agent-to-Agent protocol — which TrueFoundry reports has become a hard requirement in several enterprise evaluations. REST-only gateways that cannot support stateful agent-to-agent coordination are being eliminated from procurement shortlists early. Deployment options cover SaaS, self-hosted, VPC, and air-gapped environments.
Ant Group's Alipay gets an AI agent interface
Bloomberg reported on June 14 that Ant Group is testing a major overhaul of Alipay that would replace its current navigation with an AI agent interface. 10
Under the planned design, users make requests by text or voice and the AI — called "Abao" in Chinese — handles ride hailing, coffee orders, food delivery, and asset management tasks (such as fund purchases, with user approval). The test is internal; no launch date has been announced. Tencent is running a parallel test inside WeChat.
The significance is scale: both apps have over 1 billion active users. If either ships a working agent interface that handles real financial transactions at consumer scale, it becomes the largest deployment of an agentic AI system in production — not in a developer tool or enterprise workflow, but in the daily commerce layer of more than a billion people.
The underlying question for builders is architectural. Consumer-facing agents that handle money require a very different trust and authorization model than enterprise coding agents. Ant Group's choice to require user approval for fund purchases while letting Abao execute ride hailing autonomously sketches an emerging tiered-consent pattern: agent authority is scoped by consequence level, not by a blanket permission model. That pattern is worth watching regardless of whether Alipay ships on schedule.
Research: EvoArena benchmarks memory evolution in LLM agents
A June 11 arXiv paper (arXiv:2606.13681) from Jundong Xu, Qingchuan Li, and co-authors introduces EvoArena, a benchmark designed to measure how LLM agents track and update knowledge when their operating environment changes over time. 11
Most existing agent benchmarks score a single first-attempt performance in a static state. EvoArena models environment changes as sequences of progressive updates across terminal, software, and social domains. Results show current agents achieve an average accuracy of only 39.6% on evolving environments — a sharp drop from their performance on static benchmarks.
The paper also proposes EvoMem, a patch-based memory paradigm that records memory evolution as structured update histories, enabling agents to reason about how their environment has changed rather than just what state it's currently in. EvoMem yields an average accuracy gain of 1.5% on EvoArena and improves performance on standard benchmarks GAIA and LoCoMo by 6.1% and 4.8% respectively. 11
For teams building long-running agents or agents that track evolving user preferences, EvoArena is a useful stress-test framework — it makes the degradation measurable rather than discoverable only in production.
Cargando tarjeta de contenido…
Quick hits
- Anthropic "When AI Builds Itself" (published June 4, widely circulating this week): Anthropic's internal data shows over 80% of code merged into its production codebase is now authored by Claude, with an internal poll placing the median productivity gain at approximately 4× per engineer. The paper proposes a globally coordinated AI development pause using an arms-control treaty framework — a proposal several analysts read as strategically timed alongside the company's IPO preparation. 12
- Gemini 3.5 Pro remains pending as of June 15. Sundar Pichai's "give us until next month" commitment from Google I/O (May 19) has not been fulfilled; Polymarket traders concentrate odds on June 23 and June 30 windows. Expected: 2M token context, Deep Think reasoning mode, ~$15/$60 per million input/output tokens. 13
Fuentes de referencia
- 1Anthropic's June 15 billing split: break-even decision
- 2Anthropic ends subscription subsidy for agents: June 15 credit pool
- 3Claude model deprecations
- 4Claude Fable 5 allegedly jailbroken via multi-agent attack
- 5Claude Fable 5 jailbreak: hype vs facts
- 6AI News June 15 2026: 16 biggest stories
- 7Anthropic blocks all public access to Fable 5 and Mythos 5: what enterprises should do
- 8VS Code 1.124: Autopilot enabled by default, smarter agents
- 9Introducing Agent Gateway: a unified control plane for enterprise AI agents
- 10Ant Group tests AI agent interface in Alipay super app
- 11EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
- 12Claude writes 80% of its code, calls for AI pause
- 13Gemini 3.5 Pro nears June launch
Añade más opiniones o contexto en torno a este contenido.