SkillOpt trains your agent skills like a neural network
Microsoft Research's `microsoft/SkillOpt` (MIT, 8.2K stars, v0.1.0) is a Python framework that replaces manual skill-file guessing with a validated, bounded training loop — rollout → reflect → aggregate → select → update → gate — applied to your agent's Markdown skill document while the LLM itself stays frozen. On GPT-5.5, it averaged +23.5 points across six benchmarks; a Codex-trained SpreadsheetBench skill transferred to Claude Code with +59.7 points. The June 15 SkillOpt-Sleep preview extends the same discipline to nightly offline self-evolution of your own coding-session transcripts.

Vistazo a la investigación
Spend an hour manually editing your Claude Code skill file, run the agent, watch the score drop. Sound familiar? That's the failure mode SkillOpt was built around.
microsoft/SkillOpt is a Python framework from Microsoft Research (with Shanghai Jiao Tong University, Tongji University, and Fudan University) that treats your agent's Markdown skill document as a trainable parameter — and runs a proper optimization loop against it. 1 The target model stays completely frozen. The deployed artifact is a plain
best_skill.md file, typically 300–2,000 tokens, that your agent loads at runtime with zero extra API calls. 2It went from GitHub to PyPI in one week (v0.1.0 released June 2, 2026) and crossed 8,200 stars by June 18. 1
Why manual skill editing keeps failing
Lead author Yifan Yang (Microsoft Research Asia) put it plainly in a VentureBeat interview: 3
"The breaking point isn't whether a team can change a skill, it's that they can't guarantee the change is an improvement. Three failure modes recur: no step-size control, so skills drift; no validation, so a fix that reads as reasonable gets written in and can quietly regress performance; and no negative memory, so the same failed edit keeps coming back."
One concrete example from the paper: an ungated rewrite of GPT-5.5 on SpreadsheetBench pushed the score from 41.8 down to 41.1. 2 The edit looked reasonable. It wasn't.
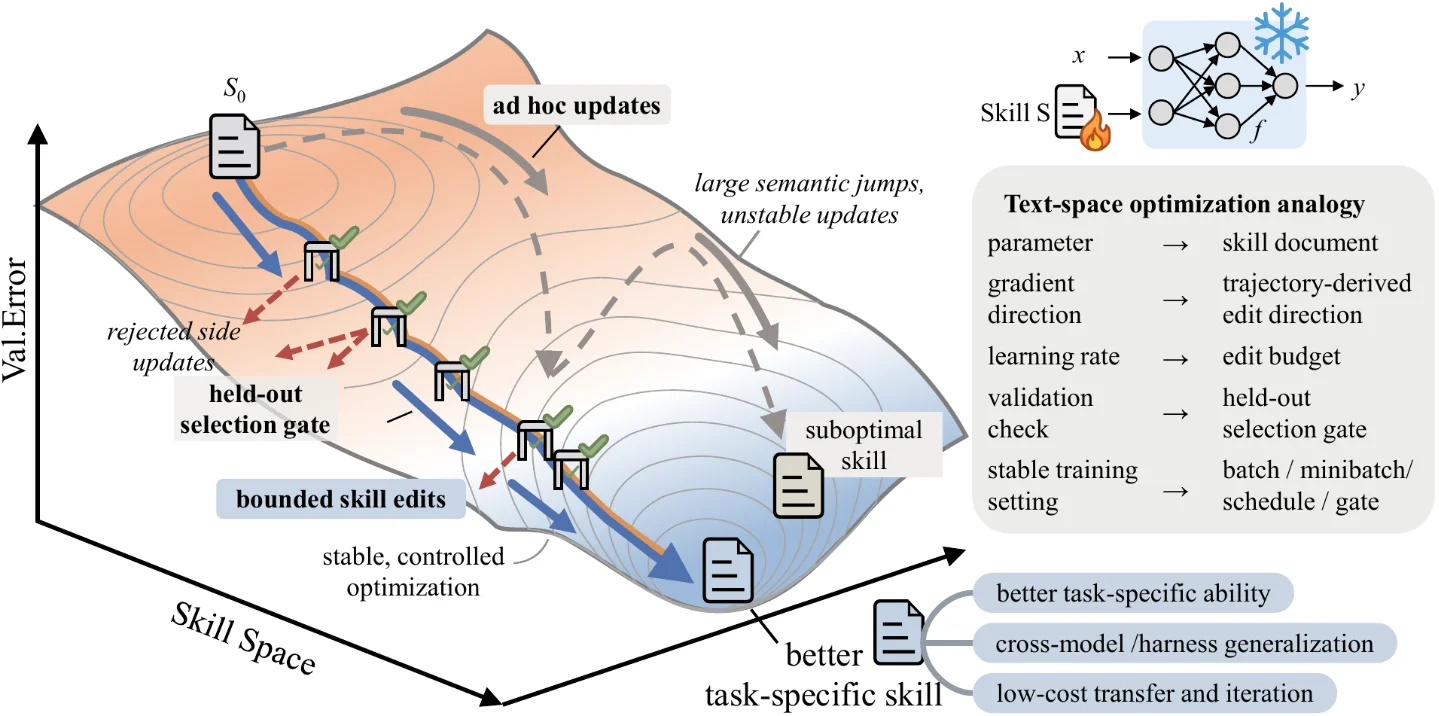
SkillOpt addresses all three failure modes by borrowing the discipline that deep learning uses to train neural networks — and mapping each concept to text space:
| Deep learning | SkillOpt text-space equivalent |
|---|---|
| Trainable parameter | Skill document (Markdown) |
| Gradient direction | Trajectory-derived edit patches |
| Learning rate | Edit budget per step |
| Validation check | Held-out selection gate |
| Momentum / slow update | Epoch-wise longitudinal reflection |
| Negative feedback | Rejected-edit buffer |
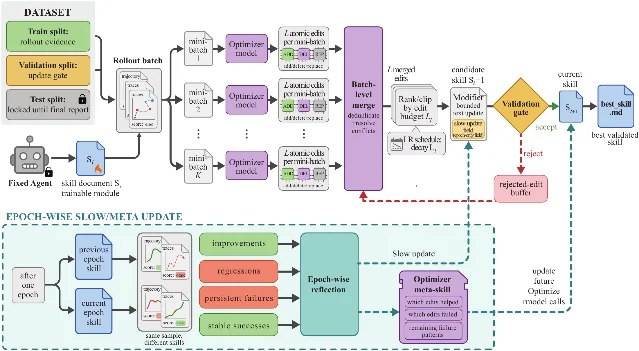
The training loop, step by step
The loop lives in
ReflACTTrainer and runs in six stages per optimization step: 2- Rollout — the frozen target agent runs a minibatch of tasks with the current skill, producing scored trajectories
- Reflect — an optimizer LLM analyzes trajectories and proposes structured
ADD/DELETE/REPLACEpatches - Aggregate — semantically overlapping patches are merged hierarchically to avoid conflicting edits
- Select — patches are ranked and clipped to the current learning-rate budget (default: 4 edits max, cosine-decayed)
- Update — accepted patches are applied to produce a candidate skill
- Gate — the candidate is scored on a held-out split; it only replaces the current skill if it strictly improves the score
After each full epoch, a "slow update" compares the previous-epoch skill against the current-epoch skill on the same tasks, writing longitudinal guidance into a protected region of the document that per-step edits can't touch. A "meta skill" captures which edit patterns helped or hurt across epochs — it informs the optimizer but never ships with the deployed artifact. 4
The rejected-edit buffer matters more than it looks. Removing it alone drops SpreadsheetBench by 4.6 points and LiveMath by 2.4 points. Removing both the meta skill and the slow update together collapses SpreadsheetBench from 77.5 to 55.0 — a 22.5-point loss that shows these aren't decorative features. 2
Install and configure
pip install skillopt # core package, Python ≥3.10
pip install skillopt[claude] # adds Anthropic Claude backend
pip install skillopt[webui] # adds Gradio dashboard on port 7860
pip install skillopt[alfworld] # adds ALFWorld benchmarkFor SkillOpt-Sleep (the nightly offline self-evolution companion, preview as of June 15):
pip install skillopt does not include it. Clone from GitHub instead. 5git clone https://github.com/microsoft/SkillOpt
cd SkillOpt
pip install -e .Credentials go in a
.env file (copy from .env.example). SkillOpt supports Azure OpenAI, plain OpenAI endpoints, Anthropic Claude, local Qwen via vLLM, and MiniMax. One quirk: it reuses AZURE_OPENAI_* env variable names even for plain OpenAI — there's no separate OPENAI_API_KEY knob. 4Quick-check without paying any API cost:
python -m skillopt_sleep.experiments.run_experiment \
--persona researcher \
--assert-improvesThis deterministic proof run (no API key needed) confirms your install is working before you burn tokens. 6
Launching a training run
# config.yaml
task: spreadsheetbench
target_model: gpt-5.4
optimizer_model: gpt-5.5
seed_skill: ./skills/my_spreadsheet_skill.md
epochs: 4
batch_size: 40
minibatch_size: 8
learning_rate: 4 # edit budget per step
lr_min: 2 # cosine decay floor
n_workers: 16python -m skillopt.run --config config.yamlOutput lands in
output/: best_skill.md, per-epoch snapshots in skills/, slow-update and meta-skill logs, and runtime_state.json for auto-resume. If the run is interrupted, re-running the same command picks up from the last completed step. 4Integrating with Claude Code, Codex, and Copilot
# Claude Code — installs /skillopt-sleep command into plugin cache
/plugin marketplace add ./plugins/claude-code
# Codex
bash plugins/codex/install.sh # adds skillopt-sleep skill
# Copilot — register as MCP server
python plugins/copilot/mcp_server.py⚠️ Known issue: the Claude Code plugin has a packaging bug (issue #52) where
plugins/run-sleep.sh is not copied into the plugin cache, causing sleep.sh to fail with a missing-runner error. Manual copy workaround: 7cp plugins/run-sleep.sh ~/.claude/plugins/skillopt-sleep/Also:
ClaudeCliBackend hardcodes a --bare flag that breaks subscription-token auth. If you're on a Claude subscription (not API key), every model call silently returns score 0 — the fix is pending in issue #68. 8What the numbers actually say
GPT-5.5 direct-chat results across six benchmarks after SkillOpt training: 2
| Benchmark | Before | After | Gain |
|---|---|---|---|
| SpreadsheetBench | 41.8 | 80.7 | +38.9 |
| OfficeQA | 33.1 | 72.1 | +39.0 |
| LiveMathematicianBench | 37.6 | 66.9 | +29.3 |
| DocVQA | 78.8 | 91.2 | +12.4 |
| SearchQA | 77.7 | 87.3 | +9.6 |
| ALFWorld | 83.6 | 95.5 | +11.9 |
Average: +23.5 points. Codex agentic loop averaged +24.8; Claude Code averaged +19.1. Across all 52 combinations of 6 benchmarks × 7 models × 3 harnesses, SkillOpt is best or tied-best — zero losses to any baseline, including human-written skills, TextGrad, EvoSkill, and GEPA. 2
Small models benefit the most in relative terms. GPT-5.4-nano nearly doubles on DocVQA (30.8 → 80.2, +49.4) and approaches triple on ALFWorld (34.3 → 69.4, +35.1). Qwen3.5-4B gains +50.7 on ALFWorld. 2 The paper authors explain the pattern: a skill can supply procedural knowledge that small models don't hold in their weights.
The cross-harness transfer finding is worth paying attention to if you're running a multi-agent setup. A SpreadsheetBench skill trained entirely inside the Codex loop, when dropped into Claude Code without any retraining, gained +59.7 (22.1 → 81.8) — slightly exceeding the in-domain Claude Code SkillOpt reference of 80.4. 2 That gap shows the learned rules aren't harness-specific command recipes; they encode workable procedure.
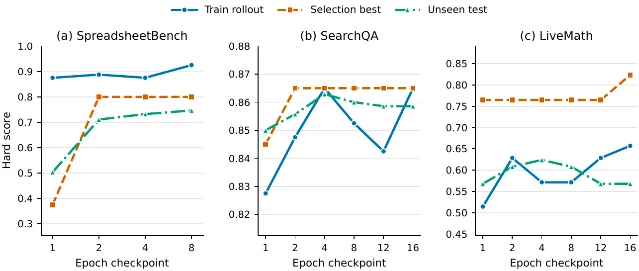
The final skill documents are compact: 379 tokens (LiveMath) to 1,995 tokens (SpreadsheetBench), median ~920 tokens, from only 1–4 accepted edits total. That's what ~23 million training tokens produces — a few hundred words that do the heavy lifting. 2
SkillOpt-Sleep: the nightly loop
Released June 15 as a preview, SkillOpt-Sleep applies the same optimization discipline to your own daily coding sessions rather than to pre-made benchmark tasks. 6
Each night it:
- Harvests session transcripts from Claude Code / Codex / Copilot
- Mines recurring tasks (not one-off requests)
- Replays them offline against your API budget
- Consolidates validated improvements into your long-term skills via the same reflect → bounded-edit → gate pipeline
From the README: 6
"The agent gets better the more you use it, with no weight training and zero inference-time overhead."
On the gbrain-evals benchmark (gbrain's real-agent evaluation harness), deficient seed skills went 0.00 → 1.00 on the held-out set with both Claude Code and Copilot, all 4 seeds. SearchQA with
recall_k=20 (pulling 20 most-similar past tasks for contrastive reflection) gained +4.5 points. 6The README is upfront about the ceiling: 6
"On saturated or noisy benchmarks the effect is flat within run-to-run noise — single-seed baseline variance here is ±1–2 pts, so treat sub-~1.5 pt differences as noise."
Community reception
The Hivemind team (activeloopai/hivemind, an open-source skills layer) announced SkillOpt integration on June 17 in r/codex: 9
"A growing pile of skills is not the same as skills that get better... This isn't memory. Memory recalls what happened. This changes what the agent is good at."
Cargando tarjeta de contenido…
On the practitioner side, Mitko Vasilev ran SkillOpt on a local Qwen3.6-27B stack with a Pi harness — no cloud API — against a .NET debug agent skill, and reported positive results: "My .NET debug agent now does gradient descent on its own stack traces. Pi is now using a frozen base model and a living skill." His LinkedIn post drew 373 reactions. 10
X/Twitter community response has been strongest in Chinese-language AI circles — VincentLogic's thread (54K followers) hit 43,302 views and 733 bookmarks on June 15, with engagement focused specifically on the cross-model transfer capability. 11
Cargando tarjeta de contenido…
Yifan Yang clarified the DSPy relationship when the question came up in the VentureBeat interview: 3
"DSPy is a different, complementary layer. It compiles declarative LM pipelines and optimizes program structure; SkillOpt optimizes the external skill state a frozen agent loads. You can run them together."
GitHub repo
Cargando tarjeta de contenido…
Limitations worth knowing before you start
The scoring function is the actual bottleneck. SkillOpt's loop is only as good as your verifier. Yang: "With no clean automatic scorer you have to design a human- or model-based evaluator and watch its stability." 3 For tasks where "good" is binary or numeric (code execution pass rate, exact-match extraction score, math answer correctness), the framework works well. For open-ended writing, creative work, or anything where quality requires human judgment, you're on your own for evaluator design.
Token cost scales with benchmark complexity. Single-task optimization in community frameworks like GBrain (Garry Tan's open-source coding-agent framework) runs ~$1–5 using Claude Sonnet as the optimizer. 3 Paper-scale training across SearchQA or DocVQA consumed 188–214 million tokens. If you're optimizing multiple tasks or running high epoch counts, the bill adds up. Flowtivity's community synthesis is accurate here: "RAG for knowledge, SkillOpt for behavior, and fine-tuning reserved for cases where you need deep domain adaptation." 12
Windows support is missing for the Codex and opencode plugins (issues #46 and #56, both open with no resolution timeline). 7
Six weeks old. The paper dates from May 22; PyPI from June 2. Strong benchmarks and early ecosystem adoption don't yet tell you what happens at production scale. One critical voice on X (@AndrewK404): "It's extremely hard to apply in domains where feedback can't be evaluated binarily + for every unit of effect you spend 0.6 to 46 million tokens. The idea is cool though — it just needs to be simplified." 13 That's a real constraint, not a dismissal.
The community consensus as of today (Flowtivity's synthesis): 12
"SkillOpt works exceptionally well for procedural, tool-heavy tasks where success is binary or numeric. It is less effective for subjective tasks where defining a good outcome is itself the challenge."
If your agent skills are in the first category — data extraction, spreadsheet manipulation, code execution, structured QA — the validation gate and edit-budget mechanics deliver exactly what they promise.
Cover image: SkillOpt text-space optimization teaser figure from Microsoft Research / SkillOpt project page
Fuentes de referencia
- 1GitHub - microsoft/SkillOpt
- 2arXiv: SkillOpt paper v2
- 3VentureBeat: Microsoft's open-source SkillOpt
- 4SkillOpt Documentation & Reproduction Guide
- 5GitHub Issue #58: skillopt_sleep not in PyPI
- 6GitHub: SkillOpt-Sleep README
- 7GitHub Issues: microsoft/SkillOpt
- 8GitHub Issue #68: ClaudeCliBackend hardcodes --bare
- 9Reddit r/codex: Hivemind SkillOpt integration
- 10LinkedIn: Mitko Vasilev
- 11X/Twitter: @VincentLogic SkillOpt thread
- 12Flowtivity: Microsoft SkillOpt Explained
- 13X/Twitter: @AndrewK404
Añade más opiniones o contexto en torno a este contenido.