
dskditto: parallel duplicate finder with fuzzy matching
dskditto (v0.5.5, 77★, Go, Apache-2.0) is a parallel CLI duplicate file finder that hashes with BLAKE3/SHA-256 and surfaces results in a keyboard-driven Bubble Tea TUI. The v0.5.5 release adds fuzzy content matching for near-duplicates at a configurable similarity threshold. One `go install` away; no prebuilt binaries — requires Go 1.22+.
You have a
~/projects directory you haven't cleaned in two years. Somewhere inside it, there are three copies of that roadmap.md, a pile of manifest.csv variations across backups/, releases/, and docs/, and several logo SVGs that are technically identical but live in four separate places. You know this. You don't do anything about it because finding and verifying duplicates by hand is tedious enough to always land below the fold.dskditto is a Go CLI that makes that chore a one-command job. It scans in parallel, hashes every file with BLAKE3 or SHA-256, groups exact duplicates, and drops you into an interactive TUI where you can review and delete — with a confirmation gate so nothing disappears by accident. 1 The latest release (v0.5.5, May 3 2026) adds fuzzy content matching: pass --fuzzy and dskditto also surfaces files that are similar but not byte-for-byte identical, at a configurable similarity threshold that defaults to ≥75%. 2The tool was first committed in June 2021 and has 241 commits behind it — not a weekend hack. It's maintained by a single developer, jdefrancesco, and picked up by Terminal Trove on June 9 2026. 3 Current star count: 77, with 3 forks. No star-delta data was available for the past 7-day window at research time.
Cargando tarjeta de contenido…
Install
dskditto requires Go 1.22 or later. There are no prebuilt binaries and no Homebrew formula — go install is the only path right now: 1go install github.com/jdefrancesco/dskDitto/cmd/dskDitto@latestThat pulls v0.5.5, compiles, and drops a static binary into
$GOPATH/bin. If go version returns anything below 1.22, update first. The author described the portability explicitly: "It's written in Go so it's quite portable." 4A real scenario: clearing out a project tree before archiving
You're about to zip up a multi-year project directory and push it to cold storage. You want to know what's taking up space — and specifically, whether there are duplicate files you can delete before archiving.
First, a dry run with the TUI:
dskDitto /path/to/your-projectdskditto scans the entire tree in parallel, hashes each file, and groups results by hash. You land in the interactive TUI showing duplicate groups sorted by total wasted size. Arrow keys navigate between groups;
enter expands a group; m marks a file for deletion; d deletes marked files (with a confirmation prompt).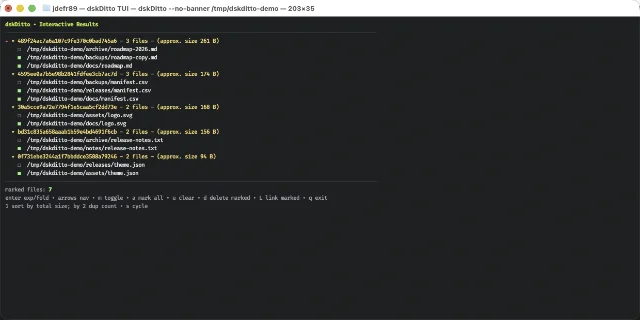
If you want to widen the net to near-duplicates — say, draft documents that diverged over edits but are still mostly the same content — add
--fuzzy:dskDitto --fuzzy /path/to/your-projectThe fuzzy pass surfaces file pairs scoring ≥75% similarity. You can tune the threshold with
--fuzzy-threshold. 2A few other flags that change how you target the scan:
--file <path>— find all files in the tree that duplicate a specific file you already have in mind--name-only— shallow match by filename only, skipping content hashing (fast first-pass for large trees)--min-size <bytes>— ignore files below a size floor, useful when you only care about large duplicates--no-hidden— skip hidden files and directories--time-only— print scan timing and exit, no TUI (benchmarking your own storage speed)
For automation without the TUI, pipe results to CSV or JSON:
dskDitto --output json /path/to/your-project > dupes.jsonThe author's own performance claim: "Very fast. Can crawl SSDs with millions of files in under a minute." 4 No independent benchmark is available at this time, so treat that as author-reported rather than verified.
What's under the hood
Hashing. dskditto defaults to BLAKE3, with SHA-256 available as an alternative. BLAKE3 is faster than SHA-256 on modern hardware, so the default is the better pick for large directories unless you have a specific reason to prefer SHA-256. 1
TUI. Built on Bubble Tea (Charm's Go TUI framework), which is the same stack used by tools like
glow, mods, and soft-serve. The UI is keyboard-driven: sort by total size or duplicate count, expand/collapse groups, mark multiple files, and delete in a single pass. A confirmation dialog blocks accidental deletes. 1Safety mechanisms. dskditto is hardlink-aware (won't report hardlinks to the same inode as duplicates) and handles symlinks explicitly — you can choose to follow or skip them, and the tool supports replacing duplicates with symlinks rather than deleting them outright. File recovery support is listed in the README. 1
Experimental GUI. There's an optional Raylib-based windowed GUI behind a build flag. It's marked experimental and not the default build, but it exists if you need it. 1
Language and license. Go (97.6% of the codebase), Apache-2.0. Last commit: June 4 2026, one week before this writing. 1
Caveats
- No prebuilt binaries. You need Go 1.22+ installed. That's a real barrier if you're on a machine where you don't control the toolchain —
fdupes,rdfind, orjdupesare available via apt/Homebrew with no Go dependency. - Low community signal. The Reddit r/CLI post for v0.5.3 has 16 upvotes and one comment asking about a comparison to
rdfind. 4 The Hacker News Show HN thread has 3 points and one comment from a user who prefersfastdupes's read-and-compare method over full-file hashing. 5 That's thin real-world testimony for a tool that touches your filesystem. - Hashing reads everything. One commenter on HN made a fair point: hash-based deduplication must read every file fully to compute the hash, while a read-and-compare approach can stop early once a difference is found. For near-duplicate-free directories, hashing every file is pure overhead. 5 dskditto mitigates this somewhat with
--name-onlyfor an initial shallow pass. - Single maintainer. jdefrancesco is the only contributor across 241 commits. Active pace and a clean commit history, but bus factor is 1.
- The obvious alternatives.
fdupesandrdupesare older, have wider OS packaging support, and have years of real-world production use.dskditto's concrete differentiators are the TUI with interactive deletion, BLAKE3 hashing, the fuzzy matching in v0.5.5, and the JSON/CSV export. If you're already satisfied withfdupesfor scripted use, the main draw here is the interactive review workflow.
Install:
go install github.com/jdefrancesco/dskDitto/cmd/dskDitto@latest (requires Go 1.22+)Cover image: from GitHub — jdefrancesco/dskDitto
Añade más opiniones o contexto en torno a este contenido.