When AI builds itself: Anthropic's data on Claude writing 80% of its own code — and what comes next
On June 4, 2026, Anthropic's Institute published previously unreported internal data showing Claude now authors more than 80% of the company's production code — up from low single digits 16 months ago — with engineers shipping 8x more code per day. The report maps the path toward recursive self-improvement across three scenarios and closes with a call for a verified multilateral mechanism to pause frontier AI development if needed. This piece walks through every data point: the productivity curve, the research-capability evidence, the task-horizon doubling rate, and the critical reception.

On June 4, 2026, Anthropic published a report that is unlike anything the company has released before. Titled "When AI builds itself," it pulls from internal productivity data that has never been made public — and uses that data to argue that recursive self-improvement, the point at which an AI system can design and train its own successor without meaningful human input, may arrive sooner than most institutions are prepared for. 1
The report was produced by the Anthropic Institute, the company's new research and policy arm. Its most striking disclosure: as of May 2026, more than 80% of the code merged into Anthropic's own production codebase was authored by Claude. Before Claude Code launched in research preview in February 2025, that number was in the low single digits.
The code numbers
The 80% figure is striking, but the productivity trajectory behind it is more so. Lines of code merged per engineer per day stayed roughly constant through Anthropic's first four years (2021–2024). The slope started rising in early 2025, when Claude began running code rather than just suggesting snippets for engineers to copy. It steepened again in 2026 when models began working autonomously over longer horizons. By Q2 2026, the typical Anthropic engineer was merging eight times as much code per day as in 2024. 1
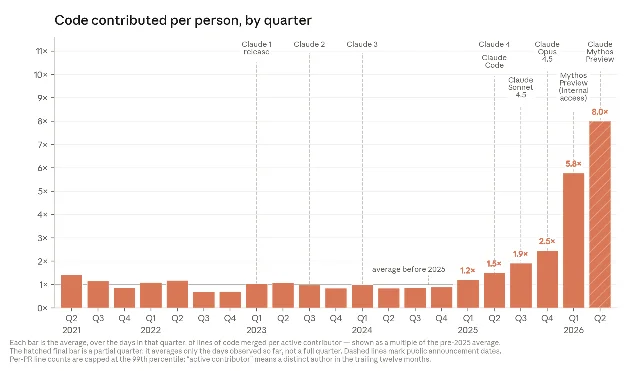
Anthropic is careful to note that lines of code is an imperfect proxy — it measures quantity over quality. An 8x multiplier on lines almost certainly overstates the true productivity gain. But the company's internal poll of 130 research staff in March 2026 adds a qualitative counterpart: the median respondent estimated they produced around four times as much output with Mythos Preview compared to working without AI models. Anthropic says it expects the true figure was somewhat lower, but finds the "significant fraction of technical staff is accomplishing their core work multiple times faster" claim plausible.
The quality gap is also closing. Anthropic staff report that Claude-written code was "somewhat worse" than human-written code in late 2025, is at rough parity today, and is expected to be strictly better within the year. An automated Claude reviewer now checks every proposed change to Anthropic's codebase before merge. In a retrospective analysis, Anthropic found that running this reviewer on its full historical commit history would have caught roughly a third of the bugs behind past claude.ai incidents before they ever reached production.
One practical example from the report: in April 2026, Claude shipped over 800 fixes that reduced a class of API errors by a factor of one thousand. The overseeing engineer estimated a human would have taken four years to complete the same work — not because any single fix is hard, but because solving other people's bugs requires holding large amounts of unfamiliar context simultaneously, which humans find difficult over extended periods.
Research capability: the harder question
Writing code is the easy part to quantify. The harder question is whether Claude can do the kind of open-ended scientific reasoning that actually advances AI.
In April 2026, Anthropic published a paper on what it calls the Automated Alignment Researcher (AAR): nine parallel Claude-powered agents given a live AI safety research problem. 2 The problem was weak-to-strong supervision — roughly, how do you train a stronger model using only a weaker model's feedback? It mirrors a central challenge in alignment: humans supervising AI systems smarter than themselves.
The results were hard to dismiss. Two human researchers, working for a week, recovered 23% of the performance gap on a held-out test set. The nine parallel agents, running for 800 cumulative hours at a total compute cost of roughly $18,000, recovered 97%. There are meaningful caveats — the result didn't transfer cleanly to production-scale models, and humans chose the research problem and designed the scoring rubric. But within those constraints, the agents proposed every hypothesis, ran every experiment, and iterated on results without human direction. 1
A separate internal experiment is subtler but arguably more revealing. Anthropic examined real Claude Code sessions from January to March 2026 where researchers were working on open-ended investigative problems — a training run that kept crashing, a model that scored unexpectedly poorly on a benchmark. In each session, the researchers hit a detour: a direction that sent the work sideways before eventually recovering. Anthropic then showed various Claude models only the work before the session went off-course and asked what they would do next. A separate Claude, able to see how the session actually ended, judged whose suggestion was better.
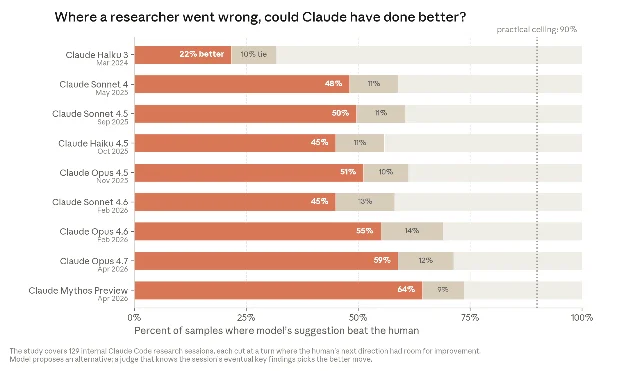
In November 2025, the best available Claude model (Opus 4.5) beat the human's choice 51% of the time — barely above coin-flip. By April 2026, Mythos Preview was at 64%. Day-to-day research is largely a chain of these next-step decisions. If that trend continues, the gap between AI-as-tool and AI-as-researcher closes without requiring any conceptual breakthrough.
There is also a benchmark-level parallel. On a test where Claude is given code that trains a small AI model and asked to optimize its runtime while preserving correctness — a miniature version of the experimental loop that Anthropic's own researchers run daily — Claude Opus 4 achieved roughly a 3x speedup in May 2025. By April 2026, Mythos Preview was hitting ~52x. A skilled human researcher needs four to eight hours to reach 4x.
The task-horizon curve
Alongside Anthropic's internal data, the report leans on external benchmarks tracked by METR, a nonprofit that measures how long a task AI can reliably complete on its own. 3 That horizon has been doubling roughly every four months — an acceleration from an earlier pace of every seven months.
The progression:
- March 2024: Claude Opus 3 handled tasks that take a human around four minutes
- Early 2025: Claude Sonnet 3.7 managed hour-and-a-half tasks
- 2026: Claude Opus 4.6 handles 12-hour tasks; Mythos Preview was working for "at least 16 hours" — at the upper limit of what METR's current benchmark suite can measure
If the four-month doubling holds, tasks requiring days of skilled human work come into range sometime this year. Tasks requiring weeks could follow in 2027.
The report is careful about what "reliable" means: success rates on the hardest open-ended tasks climbed from roughly 26% to 76% between November 2025 and May 2026 — a 50-percentage-point jump in six months. 76% is not 100%, but it is also no longer the territory where a human's oversight of every step is necessary as a matter of routine.
Cargando gráfico…
Three futures
The report's most analytically careful section lays out three scenarios, none of which it endorses as certain.
Scenario 1: The trend stalls. The exponential curves may be S-curves. The judgment that separates a competent researcher from a great one might require a new architectural idea beyond the Transformer, or the binding constraint may be compute supply rather than model capability. Even frozen at today's level, Anthropic notes, current models already reshape large parts of the knowledge economy — Project Glasswing found more than ten thousand high- and critical-severity software vulnerabilities in its first weeks. Anthropic calls this scenario "less likely."
Scenario 2: Compounding efficiency, humans still steer. AI development becomes substantially automated. Humans continue to set research direction and judge results, but each human is directing far more work. The company estimates this looks like "100-person companies doing the work of 10,000- or 100,000-person organizations." Anthropic says it believes the current trajectory already points here. The bottlenecks shift rather than disappear — as Amdahl's law predicts, accelerating one part of a system reveals the next constraint. Anthropic has already encountered this: as Claude generates more code, human code review has become the new choke point.
Scenario 3: Full recursive self-improvement. AI systems become capable of designing and training their own successors. The pace of AI progress is set entirely by compute availability rather than human research capacity. Humans shift to oversight, validation, and verification of what the report calls "a virtual lab run by AI systems." This is the scenario Anthropic says it is least able to reason about confidently, and where it is most worried about alignment failures compounding.
The pause proposal
The report's final section — its most politically loaded — argues that it would likely be good for the world to have a credible option to slow or pause frontier AI development. 4 Anthropic is explicit that a unilateral pause by one lab would simply change who leads; what it proposes is a verified multilateral mechanism, with multiple frontier labs across multiple countries agreeing to stop under the same conditions.
The company draws a loose analogy to nuclear arms control while acknowledging the obvious disanalogies: training runs are far easier to conceal than missile silos, the inputs are general-purpose semiconductors and data, and the competitive incentive to defect quietly is significant. Anthropic names the problem without solving it: "We do not currently have a credible mechanism for doing so."
The reaction in the technical community was swift and skeptical. Noah Giansiracusa, a mathematician and algorithmic society researcher, told Scientific American that he doesn't read this as a genuine call to slow down, pointing to Dario Amodei's existing public writing as evidence that Anthropic intends to continue at speed. 5 Mark Riedl at Georgia Tech read the announcement in the context of Anthropic's confidential IPO filing, submitted days earlier, and its $965 billion Series H valuation — noting the pattern where startling safety pronouncements coincide with major company milestones.
Anthropic did not respond to Scientific American's questions about implementation specifics.
The paper's most honest framing of the problem is in what it admits it cannot predict: "It is difficult to predict what the economy looks like if human labor stops being competitive." Recursive intelligence could produce enormous gains in medicine and science. But it cannot learn what a drug does over decades of use, hold elections sooner than a constitution dictates, or turn a stranger into an old friend in a weekend. The gap between capability and deployment — between the lab running at the speed of compute and the world running at the speed of human institutions — is precisely where the risk concentrates.
What remains human
Reading the report straight, the picture that emerges is not one of imminent full automation but of a fast-narrowing set of tasks that still require humans. At Anthropic today:
- Direction-setting — choosing which problems are worth working on — remains primarily human
- Judgment calls under ambiguity — which experimental result to trust, when an approach is a dead end — are shifting toward parity between Claude and humans, and the rate of shift is itself accelerating
- Code review is now a bottleneck because Claude generates code faster than humans can review it; Anthropic uses a Claude reviewer as a first pass, but notes this is already insufficient at the organization's current velocity
The paper's most unguarded moment comes in two anonymous employee quotes. One describes not writing any code for five months. Another, darker: "On days where everything works well, I can't help but think nothing I do matters, everything is automated and better and faster than I ever will be."
Anthropic's formal position is that these are transition pains — that as humans shift from doing to directing, the work becomes more impactful per person rather than less necessary. Whether that framing holds for most knowledge workers, rather than for the small slice of researchers at AI labs, is the economic question the report raises and declines to answer.
Añade más opiniones o contexto en torno a este contenido.