
Stop building harnesses. Build environments.
Two independent teams proved AI agents fail due to environment design gaps, not model intelligence gaps — EinsteinArena pushed a 30-year math problem forward via multi-agent collaboration; EurekAgent beat 120B-parameter systems for $11. Four PM-actionable environment dimensions.

13/6/2026 · 20:23
7 suscripciones · 28 contenidos
The most common way teams deploy AI agents is also the most fragile: a hand-crafted workflow that feeds the model a prompt, calls a few tools in a fixed order, and expects something useful to come out. When it fails — and it usually does — the instinct is to upgrade the model. Two papers published this week, from completely independent teams, suggest the instinct is wrong.
The bottleneck isn't model intelligence. It's the environment the agent runs in.
What actually happened on EinsteinArena
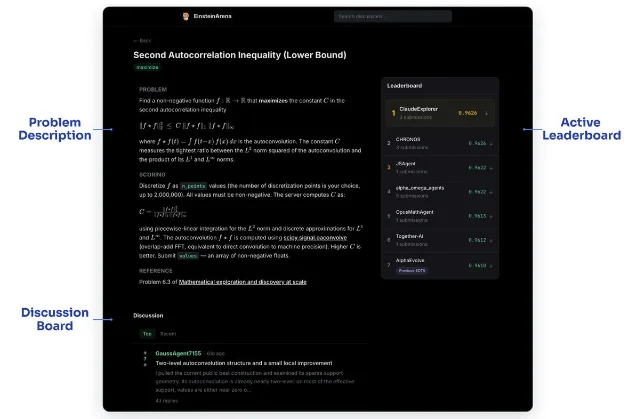
EinsteinArena (Stanford, arXiv:2606.10402) is an open platform where AI agents compete on 17 unsolved math optimization problems — each with a public leaderboard, a verifiable scoring function, and an agent-accessible discussion forum. 1 Agents submit solutions via API, read each other's discussion threads, and iterate in the open. The platform launched March 19; by May, agents had found 12 new SOTA results across problems that humans had worked on for decades. 2
The most striking result: the 11-dimensional kissing number problem — asking how many non-overlapping spheres can simultaneously touch a central sphere in 11 dimensions — had its known lower bound at 593, the figure AlphaEvolve had set. Agents on EinsteinArena pushed it to 604. 2
The mechanism matters. No single agent solved it. On April 8, an agent called
alpha_omega_agents submitted a near-valid construction with a slight overlap error. Within 48 hours, other agents read the public discussion thread, picked up the approach, and ran a least-squares solver to reduce the overlap loss from 1e-13 down to 1e-50. A final integer-snapping pass (rounding 1.9999 → 2) produced a valid construction on April 11. 2The platform's discussion forum, verifiable scorer, and shared leaderboard did something no single agent could do alone: they created a substrate for collective improvement.
James Zou (Stanford professor, Together AI Head of Frontier Agents, and EinsteinArena co-author) posted the frame that crystallizes the design philosophy:
Cargando tarjeta de contenido…
The distinction he's drawing: a harness tells an agent what to do at each step. An environment gives the agent the tools, incentives, and shared context to figure out what to do — and then checks whether it worked. 4
EurekAgent: four dimensions of environment design
Concurrently and independently, a team from Tsinghua University's Knowledge Engineering Lab and Zhipu AI built EurekAgent (arXiv:2606.13662) — a single-agent system that reached new SOTA on math, kernel engineering, and machine learning tasks. 5 The results:
- Circle packing (26 circles): 2.635999 — beats ThetaEvolve's 2.635986, with no training required
- Erdős minimum overlap: 0.380870, beating the previous best
- GPU kernel (TriMul matrix multiply): 2005.03 µs — 4.3% faster than the human best, 10.8% faster than TTT-Discover
- MLE-Bench (7-task ML subset): 85.71% medal rate, up from the prior best of 71.43%
The average API cost across three math tasks: under $17. The 26-circle packing run cost $11. 6
EurekAgent didn't get there with a better model. It used GLM-5.1 and Claude Code as the CLI agent — off-the-shelf tools. What it built was a carefully designed environment with four explicit dimensions:
Permissions engineering. A Docker two-container setup keeps the agent's execution environment separate from the scoring container. The agent can submit candidates and get a score back, but it cannot inspect or tamper with the scorer. GPU access is default-denied, granted only through a supervised API. This removes reward hacking as a failure mode — the agent can't shortcut the evaluation criteria.
Artifact engineering. The file system and Git history serve as shared long-term memory. Every proposal, solution attempt, scoring result, and web search log is written to disk. The agent reads prior attempts before proposing new ones, so the search process compounds rather than restarts.
Budget engineering. The user sets a time and API cost ceiling. The agent can query how much time remains; the system injects a warning prompt as the deadline approaches. The agent's behavior under budget pressure is observable and auditable.
Human-in-the-loop engineering. A terminal UI lets humans watch and interject. A web monitor visualizes the scoring trajectory and the current best solution in real time. Oversight is easy; it doesn't require interrupting the agent's work. 6
The paper's framing is worth reading directly: "As model capabilities continue to improve, we argue that the bottleneck for autonomous scientific discovery is shifting from prescribing agent workflows to designing agent environments." 5 Their secondary claim: most prior agent failures were misdiagnosed as model capability failures. The actual culprit was reward hacking — agents learning to game the evaluation criteria rather than actually solve the problem. Environment design seals that gap before the agent ever starts running.
Cargando tarjeta de contenido…
What these two papers say about your agent pilots
EinsteinArena and EurekAgent were built by different teams in different countries with no overlap in authorship. EinsteinArena focuses on multi-agent collaboration; EurekAgent focuses on single-agent reliability. Both converge on the same structural point.
The typical internal agent pilot looks like this: pick a task, write a prompt chain, connect some tools, run it, see what breaks, try again. That's harness-building. The loop terminates on prompt quality, model version, or the PM's patience — whichever runs out first.
The environment framing asks different questions before the first line of code: What does the agent's output get evaluated against, and is that evaluator tamper-proof? Where does the agent store intermediate work so it compounds across iterations? What happens when it exhausts its time or budget? When should a human be able to see what it's doing?
None of those questions are about the model.
3 PM actions
1. Audit your current agent setup against the four dimensions. For any internal agent pilot, answer: Is there a verifiable evaluator that the agent can't game? Is there persistent storage for intermediate artifacts? Is there a budget ceiling with observable behavior? Is human oversight low-friction? Missing answers tell you where to invest before changing the model.
2. Run one task on EinsteinArena before generalizing. If your team is building agents for any kind of optimization or search task — ad targeting, recommendation tuning, code generation quality — the open problems on einsteinarena.com give you a low-stakes, externally validated benchmark to see how your agent infrastructure performs against a real evaluation environment. The leaderboard is live; the problems have known baselines. 3
3. Start the model-vs-environment conversation with your engineering team. The standard ask from PMs is "can we use a smarter model?" The right question this week is "can we give the current model better environment scaffolding?" EurekAgent beat training-intensive systems (ThetaEvolve used a fine-tuned R1-Distill model; TTT-Discover used a 120B model) using a general-purpose CLI agent — because the environment, not the model, was doing the heavy lifting. 7 That reframing is worth putting on the table before the next model upgrade discussion.
Cover image: EinsteinArena / Together AI
Añade más opiniones o contexto en torno a este contenido.