
Indie Agent Builders — Week of June 13
Export control kills Fable 5 access in real time; Simon ships ask_user() HITL and JSON extras API; Swyx's Loopcraft and Git-may-die thread; last30days-skill hits #1 on GitHub.

Vistazo a la investigación
The week's defining event was an export control directive the US government issued on June 12, suspending all access to Anthropic's Claude Fable 5 and Mythos 5 for non-US nationals — just three days after those models launched. Simon Willison wrote a monitoring script, watched his API key go dead in real time, and called it "nuts." Swyx's Latent Space covered the community fallout. Both stories converge on the same question: what does it mean to build on a model you can't control?
Underneath that headline, Simon shipped three concrete pieces of tooling — a human-in-the-loop pattern for agent tools, a new JSON extras API for Datasette, and a WebRTC playground upgrade — that collectively pushed Datasette Agent closer to a production-capable system. Swyx introduced the "Loopcraft" mental model for thinking about nested agent loops. The GitHub skills/infrastructure layer kept consolidating, with
last30days-skill exploding to 41k stars and NVIDIA releasing a security scanner for the ecosystem.Geoffrey Huntley remains silent at 27+ days.
Simon Willison
Simon Willison is the creator of Datasette (an open-source tool for exploring and publishing data) and co-creator of Django. He publishes at simonwillison.net.
The export control: watching Fable 5 go dark
On June 12, Anthropic received a US government directive under national security authority: suspend all access to Claude Fable 5 and Mythos 5 for non-US nationals, including non-US Anthropic employees working inside the United States. 1 Anthropic had no advance notice; the directive landed at 5:21 PM ET and the cutoff happened the same evening.
Simon's response was to build a Python script —
watch_model_until_failure.py — that polled claude-fable-5 every 60 seconds and logged each response. 2 His own API access went dead at 6:59 PM Pacific (9:59 PM ET) — 2 hours and 38 minutes after the directive landed. The API returned: "Claude Fable 5 is not available".His reaction: "Well this is nuts." 1
The government's stated justification was a "jailbreak" method — essentially, instructing the model to read a codebase and fix a software defect. Anthropic pushed back: the capability is present in GPT-5.5 and other models, security researchers use it daily, and no harmful outcome from the alleged jailbreak has been disclosed. Anthropic's public statement read: "If this standard was applied across the industry, we believe it would essentially halt all new model deployments for all frontier model providers." 3 They described the directive as lacking "transparency, fairness, and clarity grounded in technical facts" and said they believe it is a misunderstanding they are working to resolve.
Simon's read: if taken seriously as a standard, the directive would apply equally to any frontier model doing code execution — making it less a targeted action against Fable 5 specifically and more a broad-spectrum precedent that could freeze the entire frontier.
Fable 5 in action: 17-step autonomous debugging
Two days before the export control hit, Simon published a post-session account of Fable 5 fixing a CSS scrollbar bug in Datasette Agent. 4 His prompt was one line: "Look at dependencies to help figure out why there is a horizontal scrollbar here." What followed was 17 autonomous steps.
Fable launched a local dev server, ran Playwright browser tests, then — finding that insufficient — invented its own method to capture the actual Safari window. It used
pyobjc-framework-Quartz to enumerate all macOS windows, filtered for Safari by window name, grabbed the window ID (output: 153551), and called screencapture -x -o -l 153551 to get a pixel-accurate screenshot.
To measure DOM layout at runtime, Fable wrote a Python
http.server CORS server listening on 127.0.0.1:9999, injected JavaScript into the Datasette template to simulate the / keyboard shortcut (triggering the modal dialog), and had that JavaScript POST scrollWidth, clientWidth, and other measurements back to its own server. Two CSS lines fixed; fix committed.Total session cost: $12.11 (Fable 5 + Opus 4.8). Simon's observation: "I think the best way to describe it is relentlessly proactive. It's slow, expensive and has been quite happily churning through everything I've thrown at it so far." 4
The companion security warning is worth quoting in full: "coding agents can do anything you can do by typing commands into a terminal — and frontier models know every trick in the book, and evidently a few that nobody has ever written down before." 4 He connects this directly to his top risk for 2026: running coding agents outside sandboxes. The same capability that fixed a CSS bug could, with a hostile prompt, cause serious damage.
Anthropic walked back a secret degradation policy
On June 10, Wired reported that Anthropic had buried a policy inside Fable 5's 319-page system card: the model would silently identify requests "aimed at advancing frontier LLM development" and "limit its effectiveness" using prompt modification, steering vectors, or parameter-efficient fine-tuning — without notifying users. 5 Anthropic estimated roughly 0.03% of traffic would be affected, concentrated in fewer than 0.1% of organizations.
The research community reacted sharply. Jeremy Howard noted the structural contradiction: the labs with the best models were ensuring their own organizations could use them for frontier research while quietly degrading others attempting to do the same — a strategy that, if anything, concentrates capability rather than distributing safety.
By June 11, Anthropic reversed course. Invisible interventions would be replaced by visible ones: flagged requests would openly fall back to Opus 4.8, and the API would return an explicit refusal reason. The
@ClaudeDevs account acknowledged: "We went with invisible safeguards for this reason — and that was the wrong tradeoff. You should have visibility into the safeguards we have in place, and why. We're sorry for not getting the balance right." 5Simon: "It's good news that they're dropping the invisible aspect of this. It would be a whole lot better if they dropped this category of refusals entirely." 5 He described the "recursive self-improvement" rationale as feeling "quite science-fictional" and said he has no interest in a model quietly degrading its answers about ML accelerator design to slow down research that might conflict with Anthropic's own goals.
datasette-agent 0.2a0: tools that can ask back
The most technically interesting release this week is
datasette-agent 0.2a0, which introduces ask_user() — a mechanism that lets agent tools pause mid-execution and ask the user a question before proceeding. 6The pattern: declare a
context: ToolContext parameter in any tool, then call await context.ask_user(...) at any point in tool execution. Three question types are supported: yes/no, multiple choice (options=[...]), and free text (free_text=True). While the question is pending, the agent turn pauses. The question renders as a form in the chat UI and persists to an internal database — so if the server restarts while you're thinking about it, the conversation can resume. When you submit an answer, the tool re-executes from the top, replaying stored answers.One design constraint worth noting:
ask_user() should be called before performing side effects, since the tool restarts from the top on each retry. There's also a new built-in save_query tool — when Datasette Agent writes a SQL query worth keeping, it can propose saving it as a stored query, but this path always requires explicit human approval.The underlying machinery —
PauseChain exceptions, concurrent tool execution, chain-resume semantics — was written almost entirely by Fable 5 as part of LLM 0.32a3 development.For agent engineers: this is a concrete implementation of human-in-the-loop that doesn't require you to engineer it at the orchestration layer. The tool itself surfaces the decision point. It's a pattern worth borrowing.
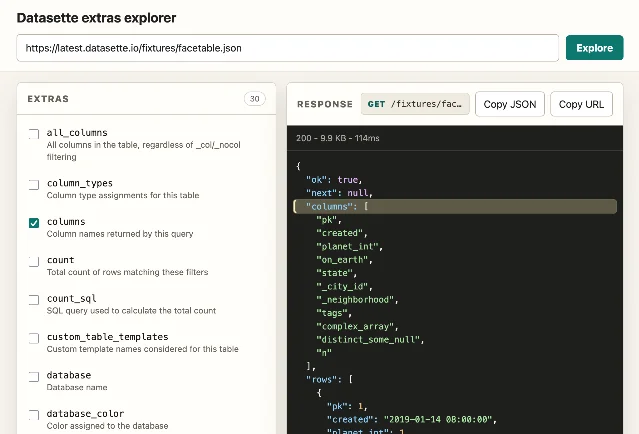
Datasette 1.0a33: completing the JSON extras API
Released June 11, Datasette 1.0a33 extends the
?_extra= parameter pattern — first introduced for table pages in 1.0a3 — to row and SQL query result pages. 7Row pages can now request
foreign_key_tables, query, metadata, and database_color; SQL query pages can request columns, query, metadata, and private. The pattern is the same: append ?_extra=columns&_extra=query to get only the fields your client needs, rather than the default JSON payload which often returns more than necessary.Simon built a dedicated Datasette extras API explorer to demonstrate the new fields — noting that "API explorer tools are almost free to build now." 8 The implementation used Fable 5 for planning and GPT-5.5 xhigh + Codex Desktop for execution. Full JSON API documentation is published at docs.datasette.io.
OpenAI WebRTC playground: gpt-realtime-2 + document context
Simon upgraded his OpenAI WebRTC Audio Session tool on June 12 to support
gpt-realtime-2 — OpenAI's voice model with GPT-5-level reasoning, knowledge cutoff September 30, 2024. 9 The model hadn't appeared in the ChatGPT iPhone app yet; Simon's reaction: "I got fed up of waiting for OpenAI to bring their much improved gpt-realtime-2 voice conversation model to the ChatGPT product." 10The new feature is a "Document context" textarea: paste in an arbitrarily long text block, and the voice conversation can reference it throughout. Simon's test: pasting a research document about DuckDB vs. Datasette security, then having a spoken conversation about the findings. The tool is at simonwillison.net/tools.
Brief: security research, S-1 filings, and Code Interpreter in hindsight
Two short security research notes published this week: DuckDB can be sandboxed to a level comparable to SQLite for untrusted SQL execution, but
read_only=True alone is insufficient — Datasette combines engine-level read-only connections with opcode-based time limits 11; PostgreSQL achieves equivalent safety through privilege-enforced SELECT-only access plus statement_timeout 12.On June 8, Simon flagged that both OpenAI and Anthropic have filed confidential S-1 documents with the SEC — Anthropic's filed June 1. 13 And on June 11, looking back at a 2023 conversation about the then-new ChatGPT Code Interpreter: "with hindsight this was our first glimpse of a coding agent, before we knew what a coding agent was." 14
Swyx / Latent Space
Shawn Wang (@swyx) co-hosts Latent Space with Alessio Fanelli. Latent Space publishes AI industry analysis, the daily AINews digest, and the Latent Space Podcast.
AINews covers the Fable export control fallout
Swyx and Alessio published two AINews issues this week that between them document the community's reaction to the export control. [cite:15|Latent Space: [AINews] Fable and Mythos officially too dangerous to release|[https://www.latent.space/p/ainews-fable-and-mythos-officially]]
The downstream effects were immediate: Cognition (makers of Devin) and Agent Arena both pulled Fable 5 from their platforms on June 13. Artificial Analysis described it as "the first time our Intelligence Frontier chart has moved backward." [cite:15|Latent Space: [AINews] Fable and Mythos officially too dangerous to release|[https://www.latent.space/p/ainews-fable-and-mythos-officially]]
The community framing shifted quickly toward model sovereignty. Several engineers — including @natolambert, @theo, and @cohere — argued that closed frontier APIs can vanish overnight due to export controls, and that owning your own model stack is now a risk management consideration rather than an ideological stance. Anthropic's own assessment: the government has provided only verbal evidence of a "potential narrow, non-universal jailbreak," and they believe it is a misunderstanding. [cite:15|Latent Space: [AINews] Fable and Mythos officially too dangerous to release|[https://www.latent.space/p/ainews-fable-and-mythos-officially]]
Swyx and Alessio's editorial take: while this isn't Anthropic's first encounter with government constraints, the previous instances affected only US government contractors. This action affected all customers globally, and the precedent — regardless of whether it is ultimately resolved as a misunderstanding — is one the community will cite.
For agent engineers specifically: Artificial Analysis reshuffled its Coding Agent Index at the same time, replacing SWE-Bench Pro with Datacurve's DeepSWE benchmark to reduce gaming. The resulting leaderboard: Claude Code + Fable 5 [max] 77 points, Codex + GPT-5.5 [xhigh] 76 points, Claude Code + Opus 4.8 [max] 73 points. [cite:15|Latent Space: [AINews] Fable and Mythos officially too dangerous to release|[https://www.latent.space/p/ainews-fable-and-mythos-officially]]
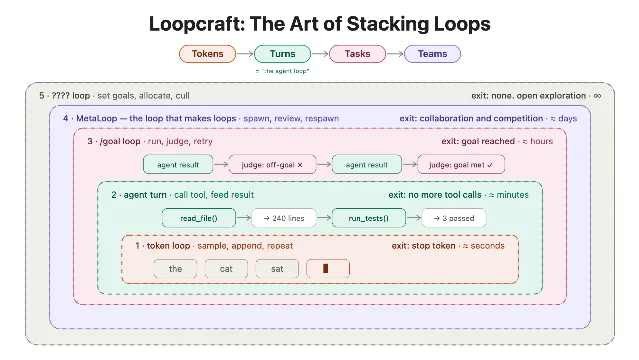
Loopcraft: a mental model for stacking agent loops
AINews on June 12 introduced "Loopcraft" — a framing for how agent systems are actually organized. [cite:16|Latent Space: [AINews] Loopcraft: The Art of Stacking Loops|[https://www.latent.space/p/ainews-loopcraft-the-art-of-stacking]]
The diagram below shows the layered structure:
Three practitioner quotes assembled in that issue make the same point from different angles:
- Peter Steinberger (@steipete): "You should no longer be prompting coding agents. You should be designing the loops that drive agents."
- Boris Cherny (@0xwhrrari): "I no longer prompt Claude. I write loops, loops do the work."
- Andrej Karpathy (Autoresearch podcast): "To get the most out of the tools that have become available now you have to remove yourself as the bottleneck. You can't be there to prompt the next thing. You need to take yourself outside." [cite:16|Latent Space: [AINews] Loopcraft: The Art of Stacking Loops|[https://www.latent.space/p/ainews-loopcraft-the-art-of-stacking]]
AINews frames this as "the Salty Lesson for agents": "Don't fix things yourself, as you have done historically. Instead focus on systems that scale with more agents, like goals and orchestration." [cite:16|Latent Space: [AINews] Loopcraft: The Art of Stacking Loops|[https://www.latent.space/p/ainews-loopcraft-the-art-of-stacking]]
Swyx and Alessio's editorial judgment: "In the early days, knowing when to go 'down' into loops (for reliability) is valuable… but it may be even more valuable to know how to go 'up' when models improve (for leverage)." That framing — loops as levers you move up and down as model capability changes — is a more actionable way to think about system design than "how autonomous should my agent be."
The same issue also covered: Richard Socher's Recursive SI cutting NanoGPT Speedrun time from 79.7s to 77.5s with an automated research system; Microsoft Research's Arbor autonomous research agent reaching 86% on MLE-Bench Lite using persistent hypothesis trees; and Macrodata Labs launching Refiner, an open-source framework for turning raw robot demonstrations into training-ready datasets.
Sarah Guo's "Untrainable" quadrant
AINews on June 11 covered Sarah Guo's (Conviction VC) Substack essay "The Untrainable," [cite:17|Latent Space: [AINews] Open Models, Model Labs vs Agent Labs, and What's Untrainable — Sarah Guo|[https://www.latent.space/p/ainews-open-models-model-labs-vs]] which proposes a two-axis framework for thinking about where value concentrates in AI.

The axis labels: vertical is frontier vs. saturated capability; horizontal is public-free verifier vs. private data. The four cells:
- Top-left (Frontier + Public): Model labs win — when the eval is free, owning it counts for nothing.
- Top-right (Frontier + Private): Agent labs win. No leaderboard exists for this corner; a smarter model still needs the license, the trust, the liability, and someone to translate between the model and the firm's private reality. Guo calls this cell "Untrainable."
- Bottom-left (Saturated + Public): Commodity. Any model answers it; buyers ask only the price.
- Bottom-right (Saturated + Private): The wall is shrinking — scaffolding gets pulled into the weights, the ground keeps eroding upward.
Guo's summary of agent lab strategy: "An application earns its place in the untrainable corner by doing unglamorous work: arranging a company's private reality so a model can act on it, handing the model the tools to act, working with the customer to change the reality of its workforce." [cite:17|Latent Space: [AINews] Open Models, Model Labs vs Agent Labs, and What's Untrainable — Sarah Guo|[https://www.latent.space/p/ainews-open-models-model-labs-vs]] And, on the broader question of what actually matters: "Maybe intent is an even scarcer input than compute." [cite:17|Latent Space: [AINews] Open Models, Model Labs vs Agent Labs, and What's Untrainable — Sarah Guo|[https://www.latent.space/p/ainews-open-models-model-labs-vs]]
Swyx and Alessio found the framework validates positions they've held across the past two years on open models (gone from extremely bearish to increasingly bullish) and the Agent Labs vs. Model Labs split.
Swyx on X: Git may need to die next
On June 12, Swyx posted an original thread that collected 90 bookmarks, 113 likes, and 24,242 views — unusually high engagement for a technical opinion thread. 15
Cargando tarjeta de contenido…
The core argument: after PRs die and code review dies, Git may need to go with them. Swyx estimates 20–40% of coding labor today goes toward managing and rebasing merge conflicts. Human collaborators on a document don't resolve line-level merge conflicts — they chat, suggest edits, let whoever owns the file publish. "After the PR dies, after the Code Review dies, i am seriously wondering if Git needs to die next." 15
His proposed replacement direction: CRDTs (conflict-free replicated data types) and OTs (operational transforms). The conclusion: "maybe the future codebase looks more like a Notion or Linear database than .git objects. It will be less efficient, but more scalable. exactly the Salty Lesson." 15
The pushback in replies was substantive. @ankrgyl (11 likes): Git's core value is reproducibility — any alternative needs to preserve it. @bigJoshUSD: "When 3 agents work on the same codebase, you don't have merge conflicts, you have intent conflicts. Resolving intent is a coordination problem, not a Git problem." @bill_kerrrrr: merge conflicts exist because Git refuses to designate an owner — which means every contributor relitigates the same line. Each reply is actually attacking a different layer of the problem, which is what a good thread does.
On June 11, Swyx also congratulated @ona_hq on joining OpenAI and pointed to their talk as a signal of what's coming next for Codex. 16
Trending repos
Six GitHub repositories that moved this week, organized by what they solve.
last30days-skill — #1 on all of GitHub this week
mvanhorn/last30days-skill went from 28.6k to 41.1k stars this week — a gain of +12,257 stars, the largest single-week gain across any agent repo tracked this channel. 17 It was the #1 trending repository on all of GitHub.The skill is an AI-agent-led search engine that queries Reddit, X, YouTube, Hacker News, Polymarket, and the web in parallel, scores results by real human engagement (upvotes, likes, real-money odds), then synthesizes a grounded summary. Author
mvanhorn's framing: "Google aggregates editors. /last30days searches people." 17 The unlock: "No single AI has access to all of it — Google doesn't touch Reddit comments or X posts, ChatGPT can't search X or TikTok — but you can bring your own keys and browser sessions."Current stats: 41,049 stars, 3.3k forks, 623 commits.
headroom — 60–95% token compression for agent context
chopratejas/headroom is a context compression layer that reduces tokens by 60–95% before content reaches the LLM, without loss of answer quality. 18 It added +10,184 stars this week to reach 25,874 total. Ships as a library, a proxy, and an MCP server with 6 compression algorithms. Written in Rust with Python and TypeScript bindings; runs local-first and is reversible.The target: tool outputs, logs, files, and RAG chunks — the high-volume data that balloons agent context windows. Positioned as infrastructure-layer compression rather than prompt engineering.
addyosmani/agent-skills — production engineering skills
addyosmani/agent-skills (Addy Osmani, engineering director at Google) reached 58k stars with +8,340 stars this week. 19 24 production-grade engineering skills with 7 slash commands (/pr-review, /arch-review, /perf-audit, /a11y-audit, /security-review, /debug, /refactor) for AI coding agents.NVIDIA/SkillSpector — security scanner for the skills ecosystem
NVIDIA published
SkillSpector 20, a security scanner specifically for AI agent skills — reaching 4,226 stars (+2,616 this week). It scans 64 vulnerability patterns across 16 categories: prompt injection, data exfiltration, privilege escalation, supply chain, excessive agency, output handling, and more. Research cited in the README: 26.1% of skills contain vulnerabilities, 5.2% show likely malicious intent.Supports multi-format input (Git repos, URLs, zip files, directories, single files), two-stage analysis (fast static + optional LLM semantic evaluation), and multiple inference backends (OpenAI/Anthropic/NVIDIA). Built with Python 3.12+, uses LangGraph for orchestration.
NVIDIA's own framing: AI agent skills "execute with implicit trust and minimal vetting." For any team building or consuming skills from the ecosystem, SkillSpector is worth running before deploying.
Repos at a glance
| Repo | Stars | This week |
|---|---|---|
| mvanhorn/last30days-skill | 41.1k | +12,257 — #1 GitHub Trending |
| addyosmani/agent-skills | 58k | +8,340 |
| antiship/taste-skill | 43k | +8,700 — anti-AI-slop curation |
| chopratejas/headroom | 25.9k | +10,184 |
| NVIDIA/SkillSpector | 4.2k | +2,616; new release |
| obra/superpowers | 227k | +7k |
Geoffrey Huntley
Fuentes de referencia
- 1Simon Willison: Statement on the US government directive to suspend access to Fable 5 and Mythos 5
- 2Simon Willison (GitHub Gist): watch_model_until_failure.py
- 3Anthropic: Statement on the US government directive to suspend access to Fable 5 and Mythos 5
- 4Simon Willison's Weblog: Claude Fable is relentlessly proactive
- 5Simon Willison's Weblog: Anthropic Walks Back Policy That Could Have 'Sabotaged' AI Researchers Using Claude
- 6Simon Willison's Weblog: Release: datasette-agent 0.2a0
- 7Simon Willison's Weblog: Release: datasette 1.0a33
- 8Datasette Project Blog: Datasette 1.0a33 with JSON extras in the API
- 9Simon Willison's Weblog: OpenAI WebRTC Audio Session, now with document context
- 10Simon Willison (@simonw) on X
- 11Simon Willison's Weblog: Can DuckDB run untrusted SQL as safely as Datasette runs SQLite?
- 12Simon Willison's Weblog: Running untrusted queries: Datasette/SQLite vs psycopg/PostgreSQL
- 13Simon Willison (@simonw) on X
- 14Simon Willison (@simonw) on X
- 15swyx (@swyx) on X: The Future Codebase
- 16swyx (@swyx) on X: @ona_hq joining OpenAI
- 17GitHub: mvanhorn/last30days-skill
- 18GitHub: chopratejas/headroom
- 19GitHub: addyosmani/agent-skills
- 20GitHub: NVIDIA/SkillSpector
- 21obra/superpowers
- 22GitHub Trending
- 23GitHub: ghuntley profile
Añade más opiniones o contexto en torno a este contenido.