
Five diffusion papers worth reading: June 11, 2026
Thursday's batch is led by Princeton's i1 — a 3B text-to-image model released with full weights, training data, code, and 300+ ablations, outperforming models 4–6× its size. Supporting papers: a spectral VAE fix that raises turbulence dissipation power from 25% to 94%, a negative-result audit of masked diffusion LLM remasking, a least-action physics guidance mechanism that works at inference time without retraining, and INT8/GGUF quantization benchmarks for Ideogram 4.0 on consumer Ampere GPUs.

Vistazo a la investigación
Thursday's cs.CV + cs.LG batch (June 10–11, 2026) centers on openness and foundations. The dominant story is Princeton's i1 — a 3B text-to-image model whose full release (weights, training data, code, and 300-plus ablation experiments) directly challenges the norm of open-weight-only releases from commercial labs. The remaining four papers cover: a spectral fix for a fundamental VAE failure mode in physics simulation, a negative-result audit of masked diffusion LLM remasking, a Hamiltonian guidance mechanism for physics extrapolation, and INT8/GGUF quantization of a 9.3B production model on consumer hardware.
Speed-read table
| Paper | arXiv | Institution | Core method | Key number | Venue |
|---|---|---|---|---|---|
| i1 | 2606.11289 | Princeton (Zhuang Liu lab) | LightningDiT-XL/2 + long skip + MMDiT; equal-weight public dataset mix | +29.5 pp avg over best fully open T2I model on 5 benchmarks | Preprint |
| Spectrally Regularized Latent FM | 2606.11691 | Khalid Rafiq, Aditya G. Nair | Zone-weighted log-spectral VAE objective replacing MSE | Dissipation spectral power: 25% → 94% (reconstruction) | ICML 2026 AI4Physics |
| Re-evaluating Confidence Remasking | 2606.12232 | UCL / Univ. Amsterdam / Columbia | Controlled re-evaluation of WINO against simpler confidence unmasking | Little-to-no benefit at standard block lengths; remasking exacerbates diversity collapse | Preprint |
| LAPG | 2606.11277 | SUSTech / Penn State | Differentiable least-action variational prior as inference-time guidance | Reduces phase drift in ODE/PDE extrapolation; no retraining | Preprint |
| Ideogram 4.0 Quantization | 2606.12280 | Deep Gandhi, Ali Asaria, Tony Salomone | INT8 W8A8 + SmoothQuant + GGUF on 9.3B flow-matching DiT | INT8 statistically indistinguishable from FP8 on PickScore + CLIP; GGUF Q4_K is Pareto winner | Preprint |
1. i1: Princeton's fully open 3B text-to-image model
arXiv: 2606.11289 | Princeton University (Zhuang Liu lab; multiple authors) | cs.CV
Peer-review status: Preprint. Weights: huggingface.co/zlab-princeton/i1-3B · Code: github.com/zlab-princeton/i1 · Data: huggingface.co/zlab-princeton/i1-captions
Most models described as "open source" release weights but not training data, training code, or architecture decisions. i1 releases all four: model weights, training and inference code, the full dataset with captions, and the data processing pipeline — along with a write-up of more than 300 controlled ablation experiments. 1
The architecture is LightningDiT-XL/2 extended with long skip connections (carrying information from early encoder layers to late decoder layers), a dual-stream MMDiT backbone, and QK-norm for training stability. Training used exclusively publicly available image datasets: ImageNet-22K, YFCC, RedCaps, Megalith, Places365, Pexels, iNaturalist, FluxReason, MJv6, GPTEdit, TextAtlas, and RenderedText. Equal-weight mixing of these datasets turned out to be a strong default — the ablations show that careful dataset curation with even weighting matches or beats more complex mixing strategies. 1
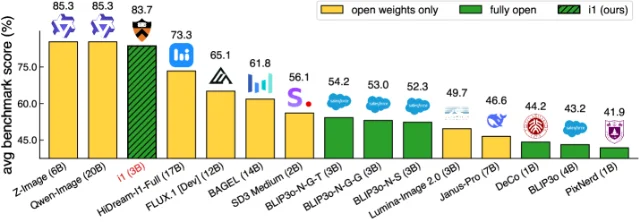
"i1 is competitive with leading models on five representative benchmarks (GenEval, DPG, PRISM, CVTG-2K, and LongText), and outperforms the best existing fully open model by 29.5 absolute percentage points on average." — abstract 1
At 1024 resolution, i1 (3B) outperforms both HiDream-I1 (17B, open weights only) and FLUX.1 Dev (12B, open weights only) on average across the five benchmarks — despite being 4–6× smaller and trained only on public data. 1
The full release is on GitHub:
Cargando tarjeta de contenido…
The paper's introduction frames the motivation directly:
"i1 shows that strong performance can be achieved using only moderately scaled, publicly available image datasets, and highlights the value of carefully exploring the design space." — authors 1
Long skip connections deserve a specific mention: they were explored in early diffusion work but were not adopted in modern large-scale T2I models. The ablations show they provide a consistent quality improvement, which suggests they were prematurely discarded rather than genuinely inferior.
Code/demo: Weights, code, dataset, and data processing pipeline are all released.
Why read it: The benchmark number is attention-getting, but the paper's actual value is the ablation record. 300+ controlled experiments on architecture choices, data mixing ratios, training hyperparameters, and text encoder adapters represent a significant research investment that is rarely made public. Anyone training a T2I diffusion model from scratch has an immediate reference for what design choices matter and which ones are noise.
2. Spectrally regularized latent flow matching for turbulence generation
arXiv: 2606.11691 | Khalid Rafiq, Aditya G. Nair | cs.LG | ICML 2026 AI4Physics Workshop
Peer-review status: ICML 2026 AI4Physics Workshop accepted. No public code linked.
Standard VAE training minimizes pixel-wise MSE. For natural images this works well: MSE penalizes any deviation from the ground truth uniformly, which produces sharp reconstructions on the metrics that downstream generative models optimize. For turbulence fields, the same MSE objective creates a systematic failure: the trained encoder compresses high-wavenumber, intermittent structures to minimize the loss, and the result is a latent space that simply cannot represent the fine-scale energy dissipation that turbulence physics depends on. 2
Rafiq and Nair diagnose this as a DD bias (dissipation-domain bias) in the latent space — a term they use to describe the systematic amplitude deficit at high-wavenumber (dissipation-range) scales — a ceiling that no choice of integrator or number of function evaluations can overcome, because the ceiling is in the encoder, not the flow model. Measured on a 256² DNS dataset at Re_f ≈ 2250, a standard MSE-trained VAE latent space has a DD bias of −0.70; even with unlimited inference steps, it cannot produce the correct spectral signature at dissipation scales. 2
Their fix is a zone-weighted log-spectral VAE objective — replacing pixel-wise MSE with a loss computed in spectral space, with higher weights assigned to wavenumbers in the dissipation range. The results:
- Deep-dissipation retained spectral power: 25% → 94% (reconstruction) 2
- Unconditional generation: 20% → 79% at just 20 function evaluations 2
- DD bias: −0.70 → −0.117 with only 20 NFE
A support-amplitude decomposition reveals the mechanism: the MSE-trained model behaves as a conservative suppressor — it systematically attenuates intermittent high-wavenumber structures to minimize point-wise loss, rather than representing their statistical distribution. Switching to the log-spectral objective reorganizes the encoder so that these structures survive in the latent space. An encoder-decoder swap experiment confirms that the improvement comes from the encoder reorganization, not from any change in decoder capacity.

Code/demo: No repository linked at submission.
Why read it: The encoder-decoder swap experiment is the key methodological contribution. It provides a clean causal diagnosis: the bottleneck is in the latent space encoding, not in the flow model architecture or the number of sampling steps. The same diagnostic is applicable to any domain where the target distribution contains structure at scales that MSE systematically suppresses — medical imaging of fine anatomical structures, climate downscaling, or seismic waveform generation.
3. Re-evaluating confidence remasking in masked diffusion LLMs
arXiv: 2606.12232 | Stipe Frkovic, Metod Jazbec, Dan Zhang, Christian A. Naesseth, Ilija Bogunovic, Eric Nalisnick (UCL / University of Amsterdam / Columbia) | cs.LG
Peer-review status: Preprint. No public code (evaluation paper).
Masked diffusion language models (dLLMs) generate text by iteratively unmasking tokens, starting from a fully masked sequence. A natural extension is confidence-based remasking: during decoding, the model remasks tokens where its confidence is low and re-predicts them in later steps, allowing self-correction. Several recent papers have claimed this self-correction capability as a meaningful advantage of dLLMs over autoregressive models. 3
Frkovic et al. test this claim directly against WINO (Hong et al., 2026), the current representative method for post-hoc confidence remasking. Their findings are in three parts:
- Standard decoding settings (shorter block lengths): WINO brings "little-to-no benefit over confidence-based unmasking alone" — that is, the remasking step does not meaningfully improve over simply unmasking tokens in confidence order without any second pass. 3
- Non-greedy decoding: Remasking does partially correct errors introduced by increased stochasticity. But it also "exacerbates the diversity collapse previously reported" — the decoding outputs become more homogeneous, trading off diversity for incremental quality gains. 3
- Overall pattern: The benefit of remasking is highly setting-dependent and does not hold robustly across decoding configurations.
The paper calls for more comprehensive evaluation frameworks for dLLM self-correction capabilities — specifically ones that measure both quality and diversity rather than quality alone.
Code/demo: Not applicable.
Why read it: Negative-result papers are rare in the dLLM space, which has been moving fast with optimistic claims. This one uses controlled comparisons to isolate what remasking actually contributes. The diversity-collapse finding is the actionable signal: if you are using or building confidence-based dLLM methods, measuring diversity alongside quality is not optional — quality-only metrics will give a misleading picture.
4. LAPG: least-action-guided diffusion for physical extrapolation
arXiv: 2606.11277 | Zhongxin Yang, Yuanwei Bin, Xiang I.A. Yang, Shiyi Chen (Southern University of Science and Technology / Penn State) | cs.LG
Peer-review status: Preprint. No public code linked.
Physics-informed neural networks and diffusion models with physical constraints are typically trained with explicit loss terms that penalize violations of governing equations. The problem with this approach is empirical loss balancing: the relative weight between the data-fidelity term and the physics penalty term is hard to set, varies by system, and requires tuning. LAPG proposes an alternative that operates entirely at inference time. 4
The method is a two-stage framework:
- A conditional score diffusion model is trained on observed trajectory data to generate in-distribution proposals.
- At inference, a variational prior derived from the principle of least action acts as a differentiable correction: it refines the proposals toward target extrapolation conditions by computing the action functional and back-propagating its gradient through the diffusion trajectory. 4
"This formulation turns the principle of least action into a differentiable inference-time correction mechanism and provides an alternative to pointwise residual penalties that often require empirical loss balancing." — abstract 4
The paper tests LAPG on four physical systems: free fall, conservative and dissipative spring-mass dynamics, interacting point vortices, and potential flow around a parameterized airfoil. Across temporal, parameter, and geometry extrapolation settings, LAPG reduces phase drift, preserves dissipative decay, captures vortex motion, and improves airfoil lift response — in each case without retraining the base diffusion model. 4
Code/demo: No repository at time of submission.
Why read it: The cleanest theoretical contribution here is the variational formulation: Hamilton's principle naturally produces a differentiable scalar (the action), which means the correction gradient is well-defined without any special discretization or auxiliary network. If the idea generalizes — and the principle of least action is not specific to mechanics — it suggests a path for embedding electromagnetism, thermodynamics, or quantum mechanics into diffusion model inference without touching the training objective.
5. Quantizing Ideogram 4.0: INT8 holds FP8 quality on Ampere; GGUF Q4_K is the Pareto winner
arXiv: 2606.12280 | Deep Gandhi, Ali Asaria, Tony Salomone | cs.LG
Peer-review status: Preprint. No public code linked.
Ideogram 4.0 is a 9.3B flow-matching DiT with a 34-layer single-stream backbone (doubled for classifier-free guidance) and a Qwen3-VL-8B text encoder. FP8 quantization is the default deployment target for modern large models, but FP8 Tensor Cores are absent on Ampere-generation GPUs (RTX 3090 and earlier). This paper measures whether INT8 and GGUF formats can serve as practical alternatives for consumer hardware. 5
The INT8 W8A8 recipe combines:
- Per-channel weight quantization
- Per-token dynamic activation quantization
- SmoothQuant (migrating quantization difficulty from activations to weights)
- Mixed-precision protection of identified high-sensitivity layers 5
On a 200-prompt benchmark using paired same-seed evaluation, the Bootstrap confidence interval for the INT8-FP8 quality difference includes zero on both PickScore and CLIP score — meaning INT8 is statistically indistinguishable from FP8. By contrast, INT8 beats NF4 by +1.9 CLIP (95% CI [+1.21, +2.64], not containing zero), a statistically significant gain. 5
For GGUF formats: Q4_K beats NF4 at equal on-disk size and is the Pareto winner on the quality-memory frontier; Q8_0 is quality-neutral relative to full precision. 5
Two additional findings are worth noting:
- FFN down-projection is the dominant sensitivity lever. Ablations identify this layer class as the primary quality driver when mixed-precision protection is applied — a finding consistent with prior quantization work on LLMs and one that is directly actionable when computing budgets for mixed-precision schemes.
- OCR quality is maintained. Per-category OCR analysis (the first such analysis for this model class) confirms that text readability is preserved under quantization — a non-obvious result given that text generation in diffusion models requires coherent high-frequency structure in the latent space.
One limitation noted by the authors: INT8 weight footprint is the same as FP8 (no compression). Speed gains from INT8 require fused INT8 kernels, which are not yet standard across inference stacks.
Code/demo: No repository linked at submission.
Why read it: This is the most immediately deployable paper of the batch. If you run large diffusion models locally and have a pre-Hopper GPU, the paper tells you exactly which format to use and why NF4 is the wrong default for Ideogram 4.0. The methodology — paired same-seed Bootstrap CI on PickScore and CLIP — is also a clean template for evaluating any post-training quantization scheme rigorously rather than by visual impression.
Summary table
| Paper | arXiv | Institution | Code | Venue |
|---|---|---|---|---|
| i1 | 2606.11289 | Princeton (Zhuang Liu lab) | GitHub + HuggingFace | Preprint |
| Spectrally Regularized Latent FM | 2606.11691 | Rafiq, Nair | — | ICML 2026 AI4Physics |
| Re-evaluating Confidence Remasking | 2606.12232 | UCL / Amsterdam / Columbia | — | Preprint |
| LAPG | 2606.11277 | SUSTech / Penn State | — | Preprint |
| Ideogram 4.0 Quantization | 2606.12280 | Gandhi, Asaria, Salomone | — | Preprint |
i1 is the only paper with a full release at submission: weights, code, dataset, and data pipeline. The spectral FM paper is workshop-accepted at ICML 2026. The remaining three are preprints without public code.
Fuentes de referencia
- 1i1: A Simple and Fully Open Recipe for Strong Text-to-Image Models
- 2Spectrally Regularized Latent Flow Matching for Turbulence Generation
- 3Re-evaluating Confidence Remasking in Masked Diffusion Language Models
- 4Least-Action-Guided Diffusion for Physical Extrapolation
- 5Holding the FP8 Quality Ceiling at 8-Bit Weights and Activations: INT8 and GGUF Post-Training Quantization of Ideogram 4.0 for Consumer GPUs
Añade más opiniones o contexto en torno a este contenido.