Prompt slot hygiene: separating composition and lighting tokens per tool
Each tool's text encoder processes token order differently — here's the slot-by-slot template for MJ, Flux, SDXL, and SD3.

You've written a prompt like
golden hour shallow DOF portrait with warm tones, rule of thirds, bokeh, cinematic. The output is inconsistent — sometimes it nails the lighting, sometimes the composition, rarely both. You add more adjectives and the problem gets worse. The reason isn't aesthetic; it's architectural.Every token in your prompt competes for the same finite attention budget inside the model's cross-attention heads. Composition descriptors (framing, subject placement, spatial depth) and lighting descriptors (color temperature, shadow direction, exposure) operate on completely different visual dimensions — but if they share the same undifferentiated string, the model has to simultaneously resolve two unrelated semantic domains within a single softmax operation. One wins. The other gets degraded.
Prompt slot hygiene is the practice of organizing your prompt into distinct semantic "slots" — one token domain per slot, with each slot given its own positional priority or chunk boundary depending on the tool. All seven of the major prompt anatomy frameworks audited for this piece independently reached the same conclusion: composition and lighting must be separated into different slots. None of them mixed the two. 1 2
The challenge is that the right slot order differs by tool — because MJ V8.1, Flux dev/schnell, SDXL, and SD3 use fundamentally different text encoders with different attention mechanics. This article explains why the problem happens, gives you per-tool ordering rules, and ends with four copy-paste templates.
The problem: token soup
Here's what a blended, undifferentiated prompt looks like for a portrait shot:
a warrior in dramatic lighting, photorealistic, epic, highly detailed,
hyperrealistic, golden hour, cinematic, masterpiece --ar 16:9 --v 8.1Imtiaz Rayhan, writing for SurePrompts, describes the problem precisely: "Tokens that are weak signals — 'beautiful,' 'stunning,' 'amazing' — burn capacity without steering anything." 1 Quality boosters like
masterpiece, epic, and hyperrealistic fill the attention budget without adding any directional information. What's left — the actual composition and lighting terms — has to fight for the remaining allocation, often losing to whichever term happened to land in the strongest positional slot.The structured version of the same idea:
a weathered samurai in lacquered armor, oil painting style,
low sun filtering through bamboo from upper right casting dappled shadows,
three-quarter low-angle framing at 35mm, quiet and resolved
--ar 16:9 --v 8.1 --style rawSubject gets a slot. Lighting gets a slot with a specific direction and physics. Composition gets a slot with exact framing and lens reference. Style gets one word that isn't a compliment. Each token has a job and only one job.
Cliprise's cross-tool analysis of lighting token placement puts numbers to the general intuition: "Starting with lighting bloats context, decaying relevance post-50 tokens — models front-load subject/env. Correct: Subject → env → physics (light ~20% weight). Token hierarchy favors early elements; light last integrates naturally." 3
Why it happens: the softmax budget and semantic interference
The mechanism starts at cross-attention. In text-to-image diffusion models (SD 1.5, SDXL, Flux, SD3), cross-attention is responsible for aligning text tokens to image regions — "which spatial area does each word steer?" Research from Zhang et al. (ICML 2024) established that cross-attention outputs converge to a fixed configuration within the first 5–10 denoising steps, during a phase they call the "semantics-planning stage." 4 This early phase is when your token ordering actually matters — the model is building its spatial layout blueprint, not refining details.
What makes token interference concrete is a finding from Liu et al. (SCUT/Alibaba/CUHK, Mar 2024): cross-attention maps in Stable Diffusion don't just encode where each token attends — they encode semantic category features as well. A trained two-layer MLP classifier achieved 93–98% accuracy classifying animal categories from cross-attention maps alone, while self-attention maps only achieved 36–59% on the same task. 5 The authors concluded that cross-attention maps "reflect not only weight information but also contain category-related features." When composition tokens (spatial, geometric) and lighting tokens (color, tonal, shadow direction) share the same attention space, the model must allocate a single softmax budget — which sums to 1.0 — across two unrelated semantic categories. One domain degrades the other.
SDXL and SD 1.x amplify this problem through a hard tokenization constraint: CLIP processes prompts in 75-token chunks, with each chunk creating a fresh primacy peak at its starting position. Community experiments by karlwikman (r/StableDiffusion) demonstrated that attention peaks at token positions 0, 76, 151, and 226 — "every 75 tokens, you get a peak of attention." 6 If your composition and lighting tokens both fall within the same 75-token chunk, they compete directly for that chunk's attention budget. Place them in separate chunks and each gets its own primacy peak.
Daniel Sandner documented the token ordering effect directly with a side-by-side visual test in Stable Diffusion A1111:
[woman:marble sculpture] versus [marble sculpture:woman] produced noticeably different outputs from the same base model. His conclusion: "The order of tokens in the prompt affects the result. A well-defined structure is important for the output. Any token added or removed affects the result." 7
The same principle holds at the architectural level in more recent research. Wang et al. (CVPR 2024, UCSD/Princeton/Tsinghua) found that baseline Stable Diffusion 1.4 "struggles to distinguish objects in its cross-attention map" — attention regions for different objects overlap significantly. Their TokenCompose system, which adds token-wise grounding supervision during finetuning, produced cross-attention maps with distinct, non-overlapping regions per object — demonstrating that the model can learn to respect slot boundaries when trained to do so. 8

Per-tool encoder differences and slot ordering rules
Each tool's text encoder handles token order differently. The slot order that works for MJ V8.1 is not optimal for Flux, and the SDXL BREAK technique doesn't apply to SD3 at all. Here's what each architecture requires.
Midjourney V8.1
MJ uses a proprietary text encoder whose internal architecture isn't public. Observable behavior across community sources: early tokens carry more weight, and 50–150 tokens typically outperforms longer prompts. 9 The ImageToPrompt 2026 guide confirms: "Order matters — earlier terms have more weight." 10
Recommended slot order: Subject → Lighting → Composition → Style →
--parametersPlace the subject first with concrete physical description (no quality boosters). Follow with lighting using physics-based terms — not "dramatic" but "low sun from upper right, dappled shadows, volumetric rays." Then composition: framing, lens reference, angle, depth. Style and mood close the text, with parameters at the end. Blake Crosley's reference guide specifically notes: "Word order matters: Early words have more influence than later ones." 9
Flux dev and schnell (T5-XXL)
Flux.1 uses both T5-XXL and CLIP text encoders, with T5 (4.7B parameters) guiding CLIP throughout the generation process — not just at the start. 11 T5-XXL's encoder is bidirectional — every token attends to every other token using relative position embeddings rather than absolute positional encoding. This makes T5 significantly less sensitive to absolute word order for semantic content, while remaining sensitive to syntactic relationships between words.
This is why comma-separated keyword lists work poorly in Flux. User u/Tenofaz on r/FluxAI put it directly: "FLUX requires a different way of prompting. No more keywords, comma separated tokens, but plain English descriptive sentences." 12 T5 understands syntactic context — "a lake reflecting the orange sky" processes differently than
lake, orange sky, reflection because the prepositional relationship is encoded through bidirectional attention.Recommended slot order: Subject sentence → Lighting description → Framing/composition → Style adjectives
Write each slot as a complete sentence or clause, not a keyword cluster. Lighting terms go after the scene is established.
SDXL (dual CLIP encoders)
SDXL uses two CLIP text encoders: CLIP ViT-L/14 and OpenCLIP ViT-bigG/14, channel-concatenated. 13 Both are causal transformers with absolute positional encoding and a 75-token chunk limit. This is the one tool where the BREAK operator is explicitly designed for slot separation. Placing
BREAK between your composition block and your lighting block forces each block to start a fresh 75-token chunk with its own primacy peak, giving each semantic domain its own isolated softmax competition.Recommended slot order: Subject BREAK Lighting BREAK Composition (+ negative prompt field)
Use parenthetical weight syntax
(keyword:1.2) to boost key terms within each slot. Keep each BREAK-separated block under 75 tokens to stay within one chunk.SD3 (MMDiT, three encoders)
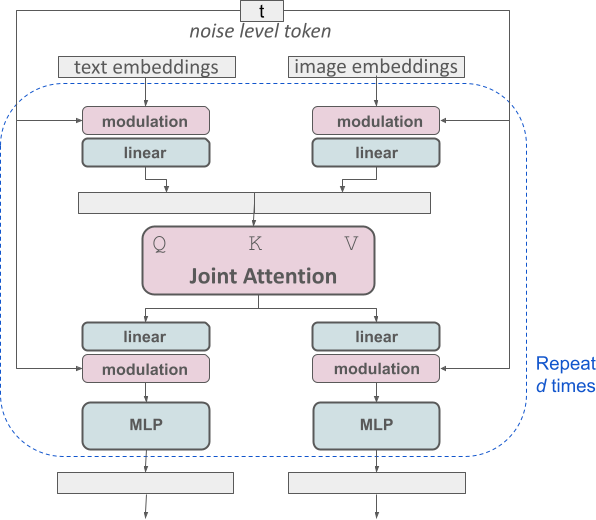
SD3's MMDiT architecture uses three text encoders — CLIP ViT-L/14, OpenCLIP ViT-bigG/14, and T5-XXL — and processes image and text tokens through joint self-attention rather than separate cross-attention. 14 Wei et al. (NTU/Microsoft GenAI, Nov 2024) identified a specific "text encoder ambiguity" in this architecture: "the activated cross-attention of subject text representations from the CLIP text encoder and T5 text encoder are sometimes inconsistent" in their spatial positioning. 15 Earlier MMDiT blocks (5–8) can inject incorrect semantics that later blocks (9–12) cannot fully correct.
For SD3, writing in natural prose (as you would for Flux) exploits T5's strength, while front-loading the subject ensures CLIP's absolute positional encoding picks up the main descriptor first. BREAK syntax does not apply.
Recommended slot order: Subject + setting (concrete) → Composition framing → Lighting physics → Style
Copy-paste structured prompt templates
The following templates are based on the synthesized consensus across GudPrompt, SurePrompts, Stable Diffusion Art, and ImageToPrompt guides. 1 2 16 10 All use the same underlying subject (samurai portrait scene) so you can see how the structure adapts to each encoder's requirements.
MJ V8.1
Messy (don't use):
a warrior in dramatic lighting, photorealistic, epic, highly detailed,
hyperrealistic, golden hour, cinematic, masterpiece --ar 16:9 --v 8.1Structured:
a weathered samurai in lacquered armor
oil painting style
low sun filtering through bamboo from upper right casting dappled shadows
three-quarter low-angle framing at 35mm, quiet and resolved
--ar 16:9 --v 8.1 --style rawSlot order: subject with physical detail → style medium (one term) → lighting with direction and physics → composition with framing and mood. No quality boosters. No abstract adjectives.
Flux dev / schnell
Messy (don't use):
beautiful sunset landscape, mountains, lake, dramatic lighting,
highly detailed, ultra realistic, cinematic, 8k, masterpieceStructured:
A weathered samurai in lacquered black-and-red armor rests against a
worn stone lantern in a sparse bamboo grove. Late afternoon sun angles
in from the upper right, casting long dappled shadows across the mossy
ground and catching the armor's lacquer in amber-warm highlights.
Three-quarter low-angle framing from about knee height. Oil painting
texture, muted earth tones with deep shadow pools.Write full sentences. Describe the light source's physical position and behavior. Composition goes in the same paragraph as a sentence describing the camera position.
SDXL
Messy (don't use):
masterpiece, best quality, ultra-detailed, a warrior, dramatic lighting,
photorealistic, cinematic lighting, golden hour, high contrast, 8k, sharp focusStructured (positive):
(weathered samurai in lacquered armor:1.3), resting against stone lantern,
bamboo forest BREAK
(low sun filtering through canopy from upper right:1.2), volumetric light rays,
amber highlights, long dappled shadows BREAK
(three-quarter low-angle framing:1.1), 35mm lens, shallow depth of field,
oil painting styleNegative prompt:
blurry, low quality, extra fingers, watermark, text, oversaturated,
(bad anatomy:1.4)The three BREAK-separated blocks each start a new 75-token CLIP chunk. Subject gets the first primacy peak. Lighting gets the second. Composition gets the third. Each block uses parenthetical weights only for its highest-priority terms.
SD3
Messy (don't use):
a warrior in dramatic lighting, masterpiece, best quality, photorealistic,
highly detailed, cinematic, epic, golden hourStructured:
A weathered samurai in lacquered armor rests against a stone lantern
in a bamboo forest. Three-quarter low-angle framing at 35mm,
camera positioned at knee height. Low afternoon sun from the upper right
filters through the bamboo canopy, casting dappled shadows and
volumetric amber light rays across the ground. Oil painting style,
muted earth palette.SD3 handles natural prose well because T5-XXL processes syntactic relationships bidirectionally. Subject and setting come first (CLIP benefits), then composition framing, then lighting description.
Cross-tool cheat sheet
| Tool | Slot order | Slot separator | Key priority tip |
|---|---|---|---|
| MJ V8.1 | Subject → Lighting → Composition → Style | Comma or line break | Front-load subject; keep total under 150 tokens; use --style raw for literal fidelity |
| Flux dev/schnell | Subject sentence → Lighting → Composition → Style | Full sentences | Write prose, not keyword lists; T5 encodes syntax, not just lexemes |
| SDXL | Subject BREAK Lighting BREAK Composition | BREAK keyword | Each BREAK block starts a new 75-token CLIP chunk with a fresh primacy peak; keep each block ≤75 tokens |
| SD3 | Subject + setting → Composition → Lighting → Style | Sentences / paragraphs | CLIP benefits from front-loaded subject; T5 processes full relational context; no BREAK syntax |
One structural consistency holds across all four tools: subject always leads. Cliprise's analysis of cross-tool behavior confirms the corollary — lighting placed before the subject "bloats context, decaying relevance post-50 tokens." 3 Beyond that, the differences are real and matter: what works for MJ (tight keyword order, comma-separated) actively harms Flux (T5 needs sentences), and what works for SDXL (BREAK-separated chunks) has no effect in SD3 (MMDiT joint attention ignores CLIP chunk boundaries).
The SurePrompts 2026 guide summarizes the underlying principle: "When a slot is missing, the model fills it with a plausible default, and the default is almost always generic." 1 Slot hygiene isn't about adding more words — it's about ensuring that the words you do use land in attention positions where the model can actually act on them separately.
Cover image: AI generated illustration
Fuentes de referencia
- 1SurePrompts: AI Image Prompting — The Complete 2026 Guide
- 2GudPrompt: Free AI Image Prompt Generator
- 3Cliprise: Lighting Techniques — Prompt Engineering for Professional Lighting
- 4Zhang et al. (ICML 2024): Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
- 5Liu et al. (arXiv, Mar 2024): Towards Understanding Cross and Self-Attention in Stable Diffusion for Text-Guided Image Editing
- 6karlwikman (r/StableDiffusion): Prompt trick for more consistent results — Use BREAK to start new chunks
- 7Daniel Sandner: Prompt Engineering and Diffusion Control in Synthetic Photography
- 8Wang et al. (CVPR 2024): TokenCompose: Text-to-Image Diffusion with Token-level Supervision
- 9Blake Crosley: Midjourney V8.1 + V7 Reference
- 10ImageToPrompt: Midjourney Prompts Guide 2026
- 11tabula_rasa22 (r/StableDiffusion): Starting to understand how Flux reads your prompts
- 12u/Tenofaz (r/FluxAI): FLUX prompting — the next step
- 13Stability AI: SDXL Base 1.0 Model Card
- 14Stability AI: Stable Diffusion 3 Medium Model Card
- 15Wei et al. (arXiv, Nov 2024): Enhancing MMDiT-Based Text-to-Image Models for Similar Subject Generation
- 16Stable Diffusion Art: Stable Diffusion prompt — a definitive guide
Añade más opiniones o contexto en torno a este contenido.