Anthropic says Claude Code works best when the user knows the job
Anthropic's Jun. 16 Economic Research report says Claude Code sessions succeed more often when users bring task-specific expertise. The brief explains the usage data, why it matters for enterprise rollout, and the limits of Anthropic's classifier-based evidence.

Anthropic's newest Claude Code research is less a product launch than a usage audit with commercial consequences. The company says it analyzed about 400,000 interactive Claude Code sessions from roughly 235,000 people between October 2025 and April 2026, using privacy-preserving methods, then classified what work was being done, who appeared to be doing it, and whether the session succeeded. 1
The headline for buyers and investors: Claude Code is not making human judgment disappear. In Anthropic's data, people still make about 70% of planning decisions, while Claude makes about 80% of execution decisions. The user decides what should be built; the agent decides much of how to build it. 1
What changed
Anthropic published the report, "Agentic coding and persistent returns to expertise," on June 16 under its Economic Research program. The study covers Claude Code sessions through the command-line interface, Claude.ai, and the Claude Code desktop app; it excludes third-party IDE integrations, SDK usage, and headless single-prompt runs. 1
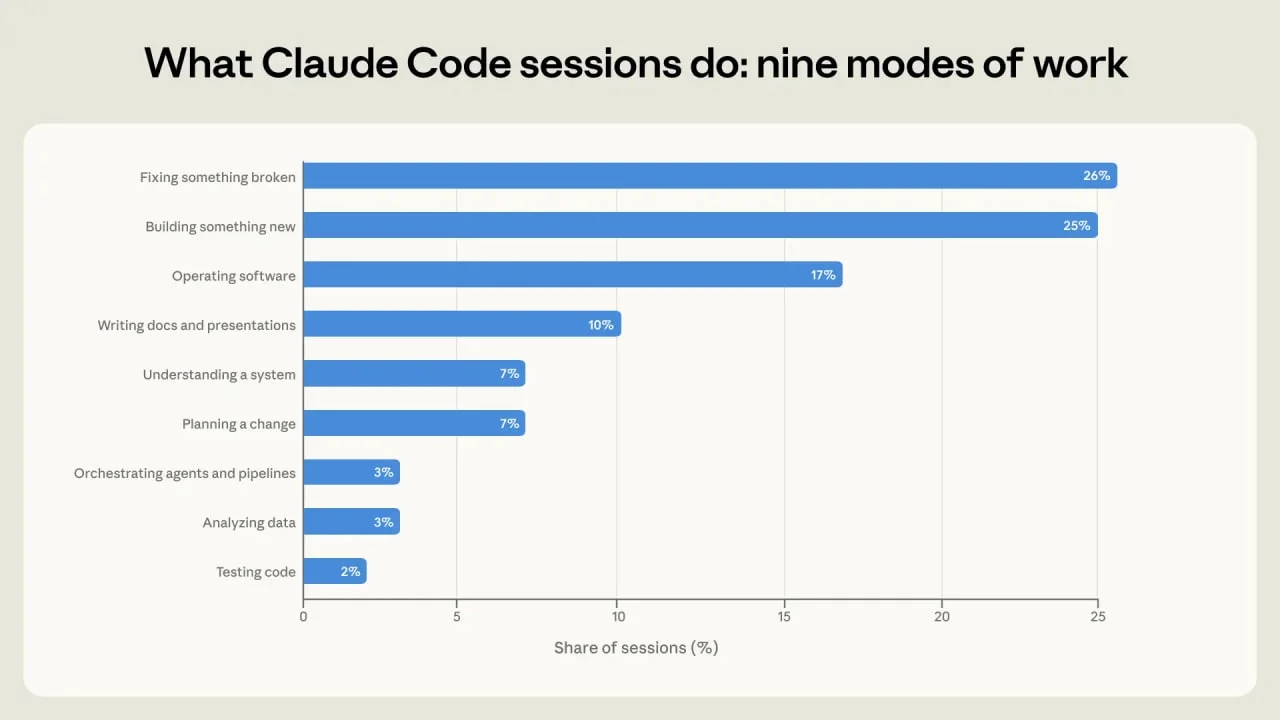
The task mix is broad enough to matter beyond software teams. Anthropic classifies about 56% of sessions as direct code work: building something new at 25%, fixing broken code at 26%, and testing or orchestrating at 5%. Another 17% involve operating software, 14% involve planning or understanding systems, and 13% produce analysis or prose where code is incidental. 1
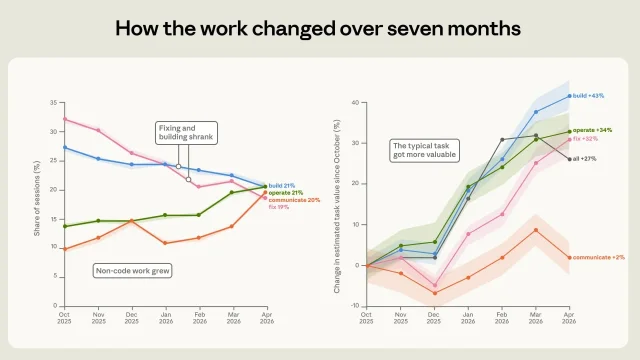
The time trend is the strongest product signal in the report. From October to April, the share of sessions spent fixing broken code fell from 33% to 19%. Operating software rose from 14% to 21%. Anthropic says writing and data analysis roughly doubled, and its estimated economic value of the average task rose 27% over the period. 1
Why it matters
The report supports a specific version of the enterprise AI thesis: the user who benefits most may not be the best programmer. Anthropic's classifier rates the user's task-specific expertise from novice to expert, based on how precisely the user frames instructions, what they ask Claude to verify, and whether the user corrects Claude or vice versa. 1
That expertise changes the amount of work Claude does per instruction. In typical novice sessions, each prompt leads to about five Claude actions and roughly 600 words of output. In expert sessions, a prompt leads to more than twice as many actions, about 12, and around 3,200 words of output. 1
The success data points in the same direction. Novice-rated sessions hit Anthropic's strict "verified success" definition 15% of the time; sessions rated intermediate or higher reach verified success 28% to 33% of the time. On the looser measure of at least partial success, novice sessions reach 77%, while intermediate-through-expert sessions reach 91% to 92%. 1
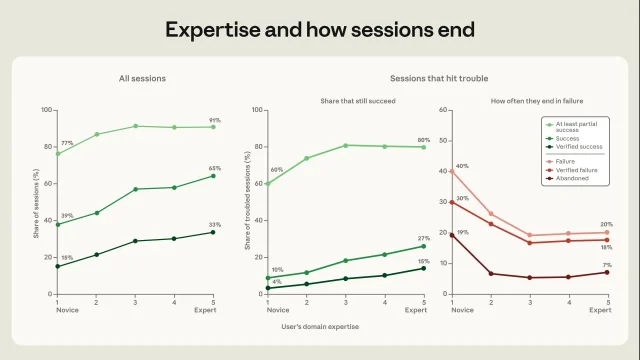
For enterprise buyers, this argues against a rollout strategy that treats Claude Code as a tool only for engineering. Anthropic says code-producing sessions by users in non-software occupations reach verified success about 29% of the time, compared with 34% for software-related occupations; under its looser partial-success measure, the two groups are nearly tied at 88% and 89%. 1
What to watch next
This is a pro-Claude Code finding, but it is not a clean replacement story. The most commercially useful reading is that agentic coding shifts some implementation work from specialists to domain owners, provided those domain owners know the problem well enough to steer and verify the output.
That has two implications for Anthropic's go-to-market story. First, the enterprise wedge is stronger if Claude Code can be sold to finance, legal, operations, science, and management teams, not only to developers. Second, training and internal controls matter: the report's success gap is tied to the user's ability to specify intent, catch mistakes, and recover when the session goes wrong. 1
The caveats are material. Anthropic says it does not observe real-world outcomes, such as whether code produced in a session is later used, discarded, or economically valuable. It also says its classifications depend on model-based transcript analysis, and that the excluded non-interactive usage is substantial enough to need a separate measurement framework. 1
For this monitor, the event is a product-and-research signal, not a funding, leadership, customer, or litigation update. The next measurable question is whether the same expertise pattern holds as Claude Code becomes more autonomous. If the gap narrows, Anthropic will have stronger evidence that the tool is broadening technical production beyond skilled domain users. If the gap persists, the buyer message becomes narrower but still valuable: Claude Code is a force multiplier for people who already understand the work.
Añade más opiniones o contexto en torno a este contenido.