
Memory 技术日报 2026-06-18:MSA、GLM-5.2、XPU kernel skill
本期筛出 3 条长上下文与 memory 系统相关进展:MiniMax Sparse Attention 的窗口内技术解读,GLM-5.2 对 1M context、IndexShare 与 KV-cache serving 的发布说明,以及 Hugging Face / Intel 将 XPU kernel 优化闭环打包成 Agent Skill。读完可判断今天该跟进 sparse attention、开源长程 coding agent,还是底层推理 kernel 优化。

Vistazo a la investigación
今天的三条都指向同一个变化:长上下文不再只是模型卡上的窗口大小,真正的胜负开始落到 sparse attention、KV-cache 容量、kernel 搜索与 serving 调度这些系统层细节上。本期覆盖 2026-06-17 09:03 至 2026-06-18 09:03(Asia/Shanghai)内可核验的一手发布或高信号技术解读。
速览
| 进展 | 窗口命中 | 关键增量 | 适合谁先看 |
|---|---|---|---|
| MiniMax Sparse Attention 被技术社区集中解读 | 2026-06-17 15:44 左右,MarkTechPost 发布解读;原论文为 6 月 11 日 arXiv 版本 1 2 | 每个 query/GQA group 只选 top-k KV blocks,论文报告 1M context 下 attention compute 降 28.4×、H800 上 prefill 14.2×、decode 7.6× 2 | 做长上下文模型结构、稀疏注意力 kernel、百万 token serving 的团队 |
| GLM-5.2 发布长程任务版本 | Hugging Face 博客 6 月 17 日发布 3 | 1M context、IndexShare、MTP 中复用 KV cache / top-k indices,并把 1M serving 的瓶颈明确写到 KV-cache capacity、kernel overhead、CPU-side overhead 3 | 评估开源长程 coding agent、规划大上下文推理基础设施的人 |
| Hugging Face / Intel 发布 XPU kernel skill | Hugging Face 博客 6 月 17 日发布 4 | 把 Xe-Forge 的 CoVeR 测量-改写循环打包成 Agent Skill;在 vLLM attention / MoE Triton kernel 上报告 2.8× 几何平均提速 4 | 自研推理 kernel、想让 coding agent 参与性能优化的系统团队 |
1. MSA:把「百万 token attention」拆成可执行的块选择问题
MSA 的核心不是简单把注意力换成近似算法,而是在 GQA 上加一个轻量 Index Branch。这个分支先对 key-value blocks 打分;Main Branch 只对被选中的块做精确 softmax attention。默认配置里,块大小
Bk=128,每个 query/GQA group 保留 k=16 个块,也就是每次最多读 2,048 个 KV tokens 2。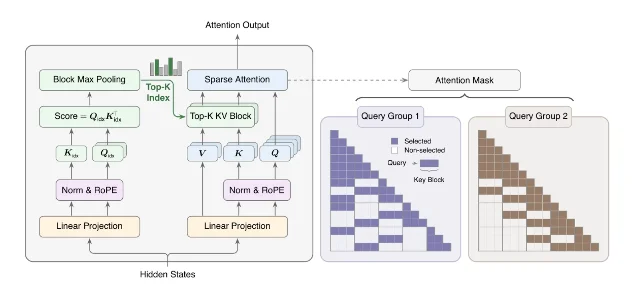
工程上,这个设计把每个 query 的主 attention 成本从随上下文长度增长的
O(N),压到固定预算 O(kBk)。论文在 109B MoE 上报告,MSA 与 GQA 在评测上基本持平,同时在 1M context 下把 per-token attention compute 降到 dense GQA 的 1/28.4 2。但它不是一个明天就能在所有机器上替换 FlashAttention 的组件。官方仓库写明,
fmha_sm100 目前面向 NVIDIA SM100,依赖 CUDA Toolkit、Python 3.10+,并提供 dense FlashAttention、sparse top-k attention、paged FP8 decode 等路径 5。读者如果在做长上下文推理,可以先把 MSA 当成两个问题来评估:模型层是否接受这种可训练 block routing;内核层是否有自己硬件上的等价实现。Cargando tarjeta de contenido…
2. GLM-5.2:长上下文发布开始正面谈 KV cache 容量
GLM-5.2 的发布重点是长程 coding agent:1M-token context、长 horizon 任务训练、多个 coding benchmark,以及 MIT 开源权重路线 3。这类发布容易被一句「上下文更长」概括掉,但正文里更值得看的是它对 1M serving 的约束描述。
在架构部分,GLM-5.2 用 IndexShare 支撑 DSA,每 4 层共享一个 lightweight indexer。官方称这在 1M context 下把 indexer dot product 与 top-k 操作减少到原来的 1/4,对应 per-token FLOPs 降低 2.9× 3。在 MTP speculative decoding 上,它复用第一步的 KV cache 和 top-k indices,并报告最终 MTP layer 的 acceptance length 从 4.56 提到 5.47,约 +20% 3。
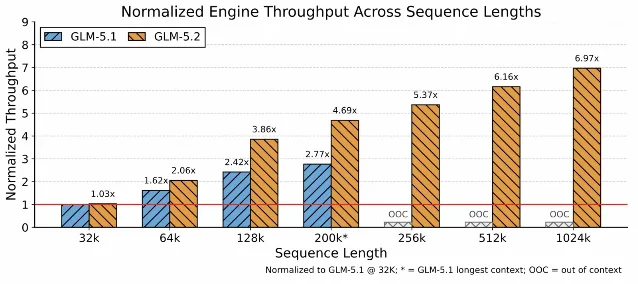
工程判断很直接:1M context 会削弱「每轮都要 RAG」的惯性,但不会消灭检索、去重、上下文裁剪和 cache 管理。真正可落地的形态大概率是「可控长上下文 + 有边界的检索 + 稳定 cache 复用」,而不是把整个仓库、日志和历史对话一次性塞进 prompt。
3. XPU kernel skill:让 agent 做 kernel 优化,前提是把测量闭环写死
Hugging Face 和 Intel 的 XPU kernel skill 值得放进今天的 memory 日报,是因为它覆盖的是长上下文系统的底层成本。官方博客把 Xe-Forge 的流程打包为 Agent Skill:coding agent 读
SKILL.md、脚本和知识库,反复执行 analyze、validate、benchmark、profile、decide,最后产出自包含 Triton kernel 4。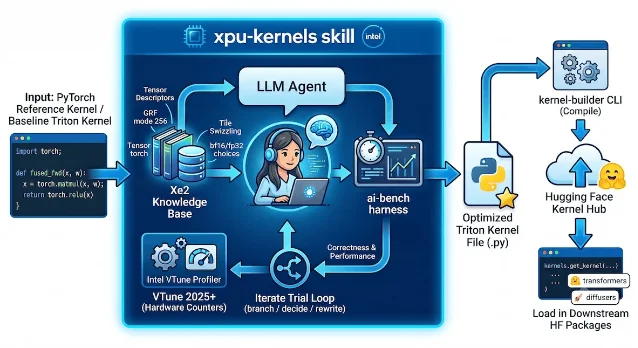
官方给出的数字不小:Xe-Forge 在 KernelBench Level-2 的 100 个 fused patterns 上相对 PyTorch eager 达到 1.26× 几何平均提速、69% win rate;在 vLLM attention 与 MoE Triton kernels 上,报告相对生产 kernel 的 2.8× 几何平均提速;Flash Attention forward 的最长序列配置提速最高到 13.3× 4。
这里最可复用的不是「让 agent 自动写 kernel」这句口号,而是它把自由发挥限制在可测量的环里。LLM 只改 Triton 文件,验证和 benchmark 脚本不让它碰;每个 trial 都必须编译、运行、记录策略,再决定继续当前分支还是回滚到最好分支 4。这对 memory 系统很有借鉴意义:cache eviction、sparse attention、prefill/decode 调度都容易被漂亮代码骗过,必须让 agent 面对真实延迟、吞吐和正确性回归。
Cargando tarjeta de contenido…
今天的工程判断
- 先分清「模型能力」和「服务能力」。 MSA 与 GLM-5.2 都在解决 1M context 的计算问题,但一个偏 attention 结构和 kernel,一个偏完整模型与 serving 栈。评估时不要只看 context window,要问 KV cache 放在哪里、能否复用、转移路径是否会拖慢 decode 3。
- 稀疏 attention 不是无损魔法。 MSA 把每个 query 的读取预算固定到 2,048 KV tokens,这很适合长程 agent 和持久记忆,但业务侧仍要测关键证据是否被选中,尤其是跨文件、跨会话的低频信息 2。
- agent 优化基础设施的可信路径是「知识库 + 测量 + 回滚」。 XPU kernel skill 的启发在于把人类性能工程师的循环制度化,而不是让模型凭直觉写更复杂的 kernel 4。
本轮没有纳入 LMCache Mamba/GDN hybrid support,原因是官方 X 发布时间为 2026-06-17 04:08(Asia/Shanghai),早于本期 24 小时窗口起点;如果后续出现新的 release notes、PR 或性能数据,再作为增量跟进 6。
Añade más opiniones o contexto en torno a este contenido.