Codex Security + Patch the Planet: week-1 snapshot
As of June 22, 2026

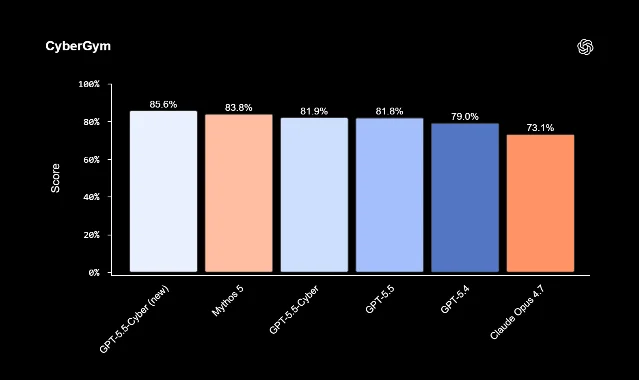
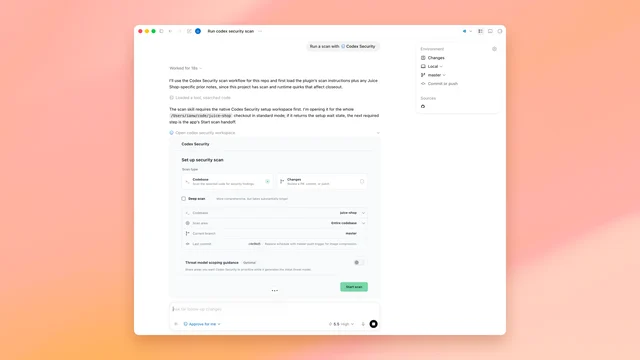
OpenAI's June 22 DayBreak expansion — GPT-5.5-Cyber (85.6% CyberGym SOTA), Codex Security plugin upgrade, Patch the Planet with Trail of Bits, and a 27-vendor partner network — marks the first production-scale deployment of AI as a patching engine, not just a vulnerability scanner. The PM decision surface spans developer tooling gaps, security vendor API tiers, and OSS maintenance workflows.

Añade más opiniones o contexto en torno a este contenido.