
HF Breakout Models, Jun 1–8: Nemotron Ultra, Ideogram 4, and Six Models Worth Evaluating This Week
Six open-weight HuggingFace models with explosive June 1–8 download growth across four modalities: NVIDIA Nemotron-3-Ultra (550B/55B active, OpenMDW-1.1, commercial-ready frontier LLM with 71.9% SWE-Bench Verified), JetBrains Mellum2 (12B/2.5B active, Apache 2.0, low-latency coding MoE at 17.4K downloads), Ideogram 4 (9.3B T2I, non-commercial, #1 open-weight on Design Arena), PaddleOCR-VL-1.6 (1B, Apache 2.0, 96.33% document parsing SOTA), Higgs Audio v3 TTS (4B, non-commercial, 100+ language zero-shot voice cloning), and Nemotron 3.5 ASR (600M, OpenMDW-1.1, 40-language streaming ASR at 17× throughput of Parakeet 1.1B). MiniMax M3 and Qwen3.7-Plus flagged as API-only / no weights.

The week's standout pattern: NVIDIA shipped two commercial-ready models on the same day (June 4) covering opposite ends of the stack — a 550B reasoning orchestrator and a 600M streaming ASR engine — while the broader community contributed the first open-weight image model to beat closed models in blind design tests, a sub-1B document parser that outperforms Gemini-class VLMs on benchmarks, and a 4B TTS system with inline emotion control. Six models are worth your time. One announcement (MiniMax M3) is still API-only; one model (Qwen3.7-Plus) never had weights.
LLMs
Nemotron-3-Ultra — 550B/55B active, OpenMDW-1.1, commercial OK
NVIDIA announced Nemotron-3-Ultra-550B-A55B-BF16 at Computex on June 1 and published the weights to HuggingFace on June 4. 1
The architecture is a LatentMoE hybrid: Mamba-2 layers + MoE + standard attention + Multi-Token Prediction (MTP). Total parameter count is 550B; 55B are active per token (~10% activation rate). Context window tops out at 1M tokens with 10-language support. The model was trained on approximately 20T tokens of pretraining data plus 212B domain-specific tokens (173B GitHub, 35B Wikipedia, 4B legal), 10M SFT samples, and 1M RL tasks generated across 15 environments. Training used MOPD (Multi-Teacher On-Policy Distillation) with more than 10 specialist teacher models covering coding, math, tool use, and agentic workflows. 1
Key benchmark results: SWE-Bench Verified 71.9%, LiveCodeBench v6 89.0%, PinchBench 90.0%, RULER @1M 94.7%, Apex-Shortlist (with tools) 84.8%, IFBench 81.7%. 1 NVIDIA's developer blog states the model "achieves 5x higher throughput compared to other open models in its class, enabling long-running agents to complete tasks faster and more efficiently." 2 That throughput figure reflects TRT-LLM on Blackwell NVFP4; the BF16 baseline on H100 is slower.
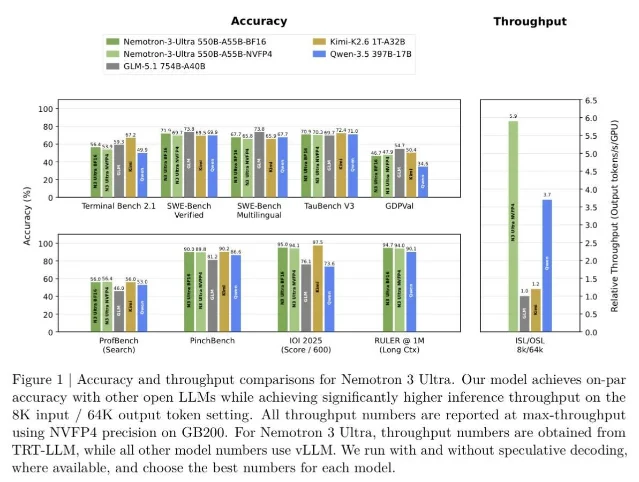
The hardware floor is steep. BF16 requires a single node of 8×B200 or a multi-node setup of ≥8×H100/H200/GB200/GB300. The NVFP4 quantized variant drops that to 4×GB200/B200/B300 or 8×H100. Supported inference stacks: vLLM v0.22.0, SGLang v0.5.12.post1, TensorRT-LLM — all with MTP speculative decoding and chunked prefill. Day-0 cloud support covers AWS SageMaker, Google Cloud, Microsoft Azure, Oracle Cloud, Baseten, DeepInfra, Fireworks AI, Together AI, Ollama Cloud, and Perplexity. 1
- License: OpenMDW-1.1 (Linux Foundation) — commercial and non-commercial use both explicitly permitted 1
- Active params: 55B (550B total MoE)
- Context: 1M tokens, 10 languages
- Deployment: vLLM, SGLang, TRT-LLM; 50+ cloud providers Day-0
- Builder angle: NVIDIA positions this as an orchestration model for "hard calls" in long-running agent workflows — maintaining architectural decisions across coding sessions, reconciling conflicting research sources, verifying constraints at scale. The throughput advantage is most relevant at high concurrency in cloud settings; self-hosting requires serious multi-GPU hardware. If you're on H100s already and need the best US-origin open-weight reasoning model for agentic pipelines, this is currently the leading option.
Mellum2 — 12B/2.5B active, Apache 2.0, low-latency coding
JetBrains published Mellum2-12B-A2.5B-Thinking around May 28 — it showed up in GenAI Secret Sauce's daily digest on June 5 with 14,700 monthly downloads, and reached 17,448 downloads by June 8. 3
Architecture: 12B total / 2.5B active (64 experts, 8 activated per token), 131,072-token context, mixed sliding-window (1,024) and full attention layers. The family ships as six checkpoints — Base Pretrain, Base, Instruct SFT, Thinking SFT, Instruct (RL-tuned), and Thinking (RL-tuned) — trained on ~11T tokens with SFT followed by RLVR (Reinforcement Learning with Verifiable Rewards). The Thinking variant outputs its reasoning trace inside
<think>...</think> tags before the final answer. 3Benchmark results for the Thinking variant: AIME 58.4%, LiveCodeBench v6 69.9%, GPQA Diamond 57.6%, BFCL v4 45.6%, MMLU-Redux 86.2%, IFEval 76.5%. 3
The model card frames the two variants cleanly: "Use this model when you want explicit chain-of-thought before the final answer — complex debugging, multi-step planning, agentic workflows, and math- or reasoning-heavy tasks." The Instruct variant handles direct, low-latency responses without a reasoning trace. 3
Community has already uploaded 2 fine-tunes and 26 quantized variants. vLLM deployment one-liner:
vllm serve JetBrains/Mellum2-12B-A2.5B-Thinking --max-model-len 131072 --reasoning-parser qwen3; add --enable-auto-tool-choice --tool-call-parser hermes for tool calls. 3Cargando tarjeta de contenido…
- License: Apache 2.0 — commercial use fully permitted
- Active params: 2.5B (12B total MoE), 131k context
- Deployment: vLLM (native), plus 26 community GGUF variants
- Builder angle: at 2.5B active parameters with 131k context and Apache 2.0 licensing, Mellum2 fits the routing and sub-agent slot in an IDE or RAG pipeline where you need reasoning-capable output but can't afford the latency or GPU cost of a 10B+ dense model. The Thinking/Instruct split means you can route low-stakes queries to Instruct and keep Thinking for the complex debug sessions.
Image generation
Ideogram 4 — 9.3B, non-commercial license
Ideogram AI released Ideogram 4 on June 3 — the company's first open-weight text-to-image model, and the only open-weight model currently sitting above all closed models on Design Arena's open rankings. 4
The architecture is a 34-layer single-stream DiT (Diffusion Transformer) with 9.3B parameters, trained from scratch — not a fine-tune of any existing model. The text encoder is Qwen3-VL-8B-Instruct, pulling hidden states from 13 intermediate layers and concatenating them for multi-scale semantic features. Two weight variants ship: fp8 (5,495 downloads, runs on any CUDA GPU) and nf4 (4,963 downloads, CUDA only, fits on a single 24 GB GPU). Download growth was sharp: 1,250 combined downloads in the GenAI Secret Sauce digest on June 5, reaching ~10,500 by June 8. 4 5
Capability range: native 256–2048px output at any aspect ratio up to 6:1, JSON-structured prompts with bounding box layout control, color palette adjustment, and multi-line multi-font text rendering. A ContraLabs blind test of ten professional designers on "Would you use this in real client work?" averaged 3.55/5 — ahead of Nano Banana 2 (2.84), Grok Imagine 1.0 (2.61), and FLUX.2[max] (2.49). 5
The inference code is open at github.com/ideogram-oss/ideogram4. Output samples showing multi-font typographic layouts, photorealistic portraits, and structured poster designs are available on the Ideogram AI blog. 5
Cargando tarjeta de contenido…
- License: Ideogram 4 Non-Commercial License — research and personal use only; commercial deployment requires a separate agreement from Ideogram AI
- Params: 9.3B, single-stream DiT
- Min hardware: single 24 GB GPU (nf4 variant)
- Builder angle: the non-commercial license blocks production deployment without a deal with Ideogram, but the weights are public for prototyping, fine-tuning research, and evaluating fit for your use case. The JSON-structured prompting interface (bounding boxes + color palettes) is specifically useful for design tools and templated asset generation, where most open T2I models require complex prompt engineering to hit layout precision. If you need a commercial path today, this isn't it yet.
Document parsing
PaddleOCR-VL-1.6 — 1B, Apache 2.0, document SOTA
PaddlePaddle (Baidu's open-source AI framework) published PaddleOCR-VL-1.6 on May 28. The model reached 9,924 downloads by June 8, growing steadily across the week. 6
At 1.0B parameters and Apache 2.0 licensed, it's a fine-tune of baidu/ERNIE-4.5-0.3B-Paddle and is architecture-compatible with PaddleOCR-VL-1.5 — meaning existing deployments upgrade without code changes. According to the model card, "PaddleOCR-VL-1.6 achieves a new state-of-the-art score of 96.33% on OmniDocBench v1.6, sets new records on OmniDocBench v1.5 and Real5-OmniDocBench as well, and demonstrates strong competitiveness against top-tier VLMs." 6 That benchmark compares against Gemini-3 Pro and Qwen3-VL-235B; a 1B model beating 235B dense models on structured document parsing is the headline. The improvement over 1.5 comes from a region-aware data optimization framework that identifies weak areas in the previous model and generates targeted training data for them.
Task coverage: OCR, table recognition, formula recognition, chart recognition, seal recognition, and text localization — the full document parsing stack in a single checkpoint. The technical report is arXiv:2606.03264.
- License: Apache 2.0 — commercial use fully permitted
- Params: 1.0B
- Builder angle: the combination of 1B scale, Apache 2.0 license, drop-in compatibility with 1.5, and SOTA benchmark performance makes this the go-to upgrade for any document intelligence pipeline currently running PaddleOCR. For builders building document extraction from scratch, the small footprint means it runs comfortably on a single mid-range GPU or even CPU inference for batch workflows.
Audio
Higgs Audio v3 TTS — 4B, non-commercial, 100+ languages
Boson AI released Higgs Audio v3 TTS around June 4. The model accumulated 15,005 downloads by June 8, the highest download count among this week's audio releases. 7
Architecture: ~4B autoregressive decoder (36 layers, hidden dim 2560, GQA (Grouped-Query Attention) 32/8). The model covers zero-shot voice cloning in 100+ languages, with 85 of those achieving WER/CER below 5% — production-quality transcription accuracy. On the Emergent TTS benchmark, Higgs Audio v3 achieved a 53.65% overall win rate, ahead of Fish Audio S2 Pro (43.80%) and Qwen3-TTS-1.7B (38.84%). Multilingual voice cloning WER averages: SeedTTS 2.10, CV3 4.41, MiniMax-Multilingual 2.74, Higgs-Multilingual 3.61 — best scores across all four evaluations. 7
The main differentiator is the inline control syntax. All emotion, style, and prosody control happens through tokens embedded directly in the input text using the
<|category:value|> format — 21 emotions (including elation, anger, sadness, and amusement), 3 speaking styles (singing, shouting, whispering), 9 sound effects, and explicit pause/pitch/speed control. The model card describes the design intent as: "Higgs Audio v3 TTS is built for voice chat: it speaks, not just reads." 7 Throughput: 14.74 req/s at 16 concurrent requests on a single H100, with RTF 0.262 (Real-Time Factor — below 1.0 means faster than real-time).- License: Boson Higgs Audio v3 Research and Non-Commercial License — no commercial use
- Params: ~4B
- Languages: 100+ (85 at production WER/CER)
- Builder angle: the non-commercial license limits production deployment, but for prototyping multilingual voice interfaces or testing zero-shot voice cloning quality before committing to a commercial TTS provider, this is currently the strongest open-weight option. The inline emotion tokens are particularly useful for voice assistant research — you can vary emotional register without post-processing or separate model calls.
Nemotron 3.5 ASR — 600M, OpenMDW-1.1, commercial OK
NVIDIA's Nemotron 3.5 ASR Streaming (released June 4) is the smaller, production-shaped sibling to Nemotron Ultra. At 600M parameters, it's a Cache-Aware FastConformer-RNNT (Recurrent Neural Network Transducer) designed for streaming multilingual transcription at scale. 8
Coverage: 40 language locales. 19 are "transcription-ready" (average WER 10.38% at 80ms chunk latency, dropping to 8.84% at 1120ms), 13 have broad coverage, and 8 need domain fine-tuning to reach production quality. A single model handles all languages via a language ID prompt: pass the target language or set
target_lang=auto for automatic detection. 8Streaming latency is configurable at 80/160/320/560/1120ms chunk sizes. At 80ms, a single H100 handles 240 concurrent streams — roughly 17× the throughput of Parakeet RNNT 1.1B (a larger model) at the same chunk setting. 8 The efficiency gain comes from the cache-aware design: the model maintains a rolling audio cache per stream rather than reprocessing context on every chunk.
- License: OpenMDW-1.1 — commercial and non-commercial use both explicitly permitted
- Params: 600M
- Languages: 40 locales (19 transcription-ready)
- Builder angle: if you're running real-time transcription across multiple languages and currently deploying separate per-language models, Nemotron 3.5 ASR collapses that into one model at substantially lower per-stream GPU cost. The 240-concurrent-stream figure on a single H100 at 80ms latency is the number to stress-test against your traffic patterns. Commercial license means you can ship it.
On the radar
Two announcements generated significant buzz this week but have no HF weights to evaluate.
MiniMax M3 launched on June 1 with claims of frontier coding performance (SWE-Bench Pro 59.0%), 1M context, native multimodal input, and a novel sparse attention architecture (MSA) that reportedly reduces per-token compute at 1M context to 1/20 of the prior generation. 9 The GitHub repository at MiniMax-AI/MiniMax-M3 says plainly: "The model is not yet released — this repository exists so the community can share what they need next." 10 MiniMax's blog committed to releasing weights within 10 days of the announcement, which puts the window at around June 11. 9 No license terms have been disclosed. Available now via the MiniMax Code desktop app and API (Plus $20/month, Max $50/month, Ultra $120/month).
Qwen3.7-Plus (Alibaba) appeared on OpenRouter on June 3 at $0.40/M input tokens with vision and GUI interaction support, 1M context. 11 No HF weights exist and none are expected — as Digital Applied noted, "Qwen3.7-Plus is closed; Step 3.7 Flash ships open weights." 11 Alibaba's Plus and Max tiers have not been open-sourced across any prior Qwen generation.
The week's shape
Six confirmed open-weight releases with real download traction, split between NVIDIA's Day-0 commercial stack (Nemotron Ultra for orchestration, Nemotron ASR for transcription, both OpenMDW-1.1) and a set of community-tier open models (Mellum2 and PaddleOCR on Apache 2.0) and research-licensed specialists (Ideogram 4 and Higgs Audio). The NVIDIA releases are immediately deployable in commercial products; the research-licensed models require a licensing conversation before production. Mellum2 is the clearest drop-in for builders already running open Apache 2.0 coding stacks who need a reasoning-capable sub-3B-active model.
Cover image: Ideogram 4 output sample collage, from the ideogram-oss/ideogram4 GitHub repository, used under Ideogram 4 Non-Commercial License
Fuentes de referencia
- 1nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16 · Hugging Face
- 2NVIDIA Developer Blog: Nemotron 3 Ultra Powers Faster, More Efficient Reasoning
- 3JetBrains/Mellum2-12B-A2.5B-Thinking · Hugging Face
- 4ideogram-ai/ideogram-4-fp8 · Hugging Face
- 5Ideogram 4.0 Technical Details: Open model at the forefront of design
- 6PaddlePaddle/PaddleOCR-VL-1.6 · Hugging Face
- 7bosonai/higgs-audio-v3-tts-4b · Hugging Face
- 8nvidia/nemotron-3.5-asr-streaming-0.6b · Hugging Face
- 9MiniMax M3: Frontier Coding, 1M Context, Native Multimodality
- 10GitHub - MiniMax-AI/MiniMax-M3
- 11OpenRouter June 2026: New Models, Pricing and Rankings
Añade más opiniones o contexto en torno a este contenido.