
Cosmos 3 just collapsed the physical AI pipeline
NVIDIA Cosmos 3 collapses 4-model physical AI pipelines into one forward pass — PM assessment inside.

10/6/2026 · 20:30
7 suscripciones · 24 contenidos
The previous generation of physical AI required four separate models wired together in a pipeline: a vision-language model to perceive the environment, a world simulator to predict what happens next, a physics reasoner to validate whether that prediction was physically plausible, and an action generator to output motor commands. Every handoff between models added latency, accumulated error, and required its own training data regime.
NVIDIA Cosmos 3, released May 31, 2026 on HuggingFace and GitHub, collapses all four into a single forward pass. 1 That pipeline collapse — not any individual benchmark number — is why this release matters to PMs building in robotics, autonomous vehicles, or warehouse automation.
What the architecture actually does
Cosmos 3 uses a Mixture-of-Transformers (MoT) architecture (a design where two specialized transformer modules handle different tasks within the same model): an autoregressive Reasoner for perception and language understanding, and a diffusion Generator for producing images, video, audio, and robot action outputs. The two towers run in parallel and share parameters; the Reasoner's key-value representations flow into the Generator at every layer via Joint Attention. 2
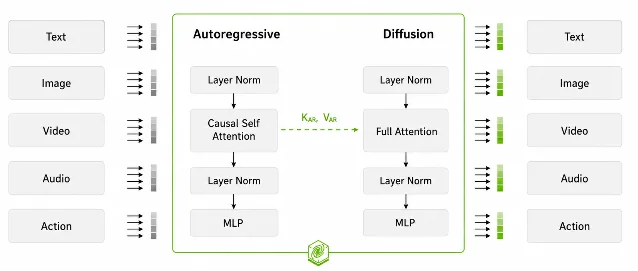
The practical result: the same model can take a text prompt, an image, a video clip, an audio segment, or a robot action trajectory as input — and produce any combination of those as output. It can watch a robot arm reach for an object and generate the next 7.9 seconds of video plus the joint-angle trajectory that produced that motion. 3 No separate policy model required.
As Michelle Sun, a robotics researcher at MIT CSAIL, noted in a widely shared thread: Cosmos 3 is the only robotics data type that "natively outputs action trajectories, not only video pixels." 4 Every other approach in robotics — teleoperation data, simulation data, egocentric video — still requires a separate step to get to motor commands.
Cargando tarjeta de contenido…
Two model sizes: Nano (16B parameters: 8B Reasoner + 8B Generator), which runs on a single NVIDIA RTX PRO 6000 workstation GPU (~$13,250), and Super (64B: 32B + 32B), which requires H100/H200/B200 datacenter GPUs. 5 A 4B Edge version for Jetson embedded hardware is announced but not yet released.
Benchmarks — and the quality counter-signal worth reading
NVIDIA's own benchmarks, drawn from the technical report, show Cosmos 3 Super leading open-source models on every physical AI axis: Driving Avg 79.3 (vs. Qwen3-VL-32B at 40.7 and Gemini 3.1 Pro at 47.2), Smart Infrastructure Avg 62.6 (vs. 56.1 and 58.6), and top scores on PAIBench-G text-to-video and image-to-video against all models including closed-source. 6
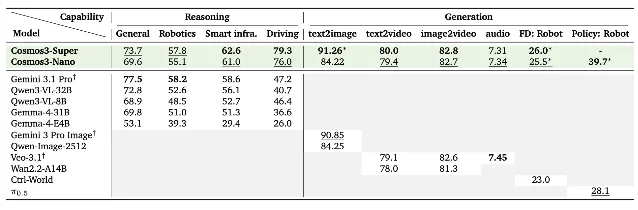
Important caveat: all benchmark numbers are vendor-stated, and the leaderboards themselves (PAIBench-G, Physics-IQ, RoboArena) are less than a year old with limited independent audit history. No third-party evaluation has been published. 7
More directly: when practitioner @varmology tested Cosmos 3 Nano on HuggingFace with a UR10 robot arm prompt, they rated the output "pretty bad imo." 8 This tracks with what you'd expect from a first open release at this architecture scale — the Nano generation quality is demonstrably frontier-rough. MindStudio's testing found that pure synthetic training underperforms mixed datasets and recommends 70-80% real demonstrations paired with 20-30% synthetic variation for optimal robot training. 9 You're not deploying this off-the-shelf; you're post-training it.
The data flywheel that comes with it
NVIDIA released six synthetic data generation (SDG) datasets alongside the model: 1
| Domain | Dataset |
|---|---|
| Robotics manipulation | Embodied Robot Scenes |
| Physics simulation | Physical Interaction Scenes (with per-object velocity and semantic segmentation) |
| Spatial reasoning | Spatial Reasoning (scene QA pairs for distance and position) |
| Human motion | Digital Human Scenes (diverse appearance, action, lighting) |
| Autonomous driving | Autonomous Driving Scenarios (weather, lane-change, pedestrian interactions) |
| Warehouse operations | Warehouse Operations Scenes (forklift collisions, cargo drops, safety scenarios) |
These datasets are available for post-training Cosmos 3 or any other model. The Reasoner context window is 256K tokens; the video generation spec supports up to 720p at 24fps for 400 frames. 5
What to do with this as a PM
The license is genuinely open. Cosmos 3 is released under the Linux Foundation's OpenMDW-1.1 license, which permits commercial use, modification, and redistribution. The only constraint: products must display "Built on NVIDIA Cosmos" attribution. 7
The hardware math. Nano runs on a single RTX PRO 6000 (~$13,250). Super requires datacenter Hopper/Blackwell hardware — and fp16 needs more than 128GB system RAM. 7 Before committing datacenter spend, there's a GPU-free trial on build.nvidia.com. 10
The right use cases right now. Cosmos 3 earns its place most clearly in two workflows today: (1) synthetic training data generation — using the model to augment real teleoperation data with varied environments, lighting conditions, and failure scenarios; and (2) policy simulation and testing — running a vision-language-action (VLA) policy inside Cosmos 3 as a world simulator to test how the policy reacts before deploying to hardware. Practitioner @ashokM93 demonstrated the second use case directly: running π0 (Physical Intelligence's open VLA model) inside Cosmos 3 Nano, deleting the target object from the scene, and watching the policy react. 11
The integration path. Two options:
Cosmos3OmniPipeline in HuggingFace Diffusers for Python-first research, or vllm/vllm-omni:cosmos3 Docker image for production API serving. Post-training scripts live at nvidia-cosmos/cosmos-cookbook on GitHub. 3Where the real moat is. The benchmark leadership may shift as independent evaluation catches up. What won't shift quickly is NVIDIA's end-to-end stack: Cosmos 3 is designed to work with Isaac Sim (physics simulation), Omniverse (digital twin platform), and the NIM inference microservices — all from the same vendor. The pipeline collapse (one model instead of four) cuts engineering complexity; the hardware integration cuts deployment friction. Those two together are harder to replicate than any individual benchmark score. Raúl Romero, co-founder of Kite ML, summarized the practical stake: "Robots break the moment the room changes. World models can fix that." 12 His team built Augment — the first publicly announced commercial product on Cosmos 3 — on exactly that premise: using Cosmos 3 to generate training video with matching actuator movements, so VLA policies generalize across different environments.
Cover image: AI-generated
Fuentes de referencia
- 1Welcome NVIDIA Cosmos 3: The First Open Omni-model for Physical AI
- 2Cosmos 3: Omnimodal World Models for Physical AI (arXiv:2606.02800)
- 3NVIDIA Developer Blog: Develop Physical AI Reasoning, World, and Action Models
- 4@michellelsun thread: 7 data types shaping robotics
- 5nvidia/Cosmos3-Nano · Hugging Face
- 6Cosmos 3 Technical Report (arXiv:2606.02800 PDF)
- 7NVIDIA Cosmos 3: The First Open Physical-AI Omnimodel — Guide 2026
- 8@varmology: Cosmos 3 Nano test results
- 9MindStudio: How to Use NVIDIA Cosmos 3 for Synthetic Training Data in Robotics
- 10Cosmos3 — a nvidia Collection on Hugging Face
- 11@ashokM93: π0 VLA policy running inside Cosmos 3 as simulator
- 12@Raul_RomeroM: Augment product launch built on Cosmos 3
Añade más opiniones o contexto en torno a este contenido.